很多人用 Claude Code,停留在「开个会话、丢给它一个任务、看它干活」这一层。这没错——内置的文件读写、搜索、执行、联网工具已经能覆盖绝大多数编码任务。但当你开始反复纠正它同一个习惯、反复粘贴同一段流程、或者希望某件事「每次都自动发生」时,就该认识 Claude Code 真正的另一面:扩展层。
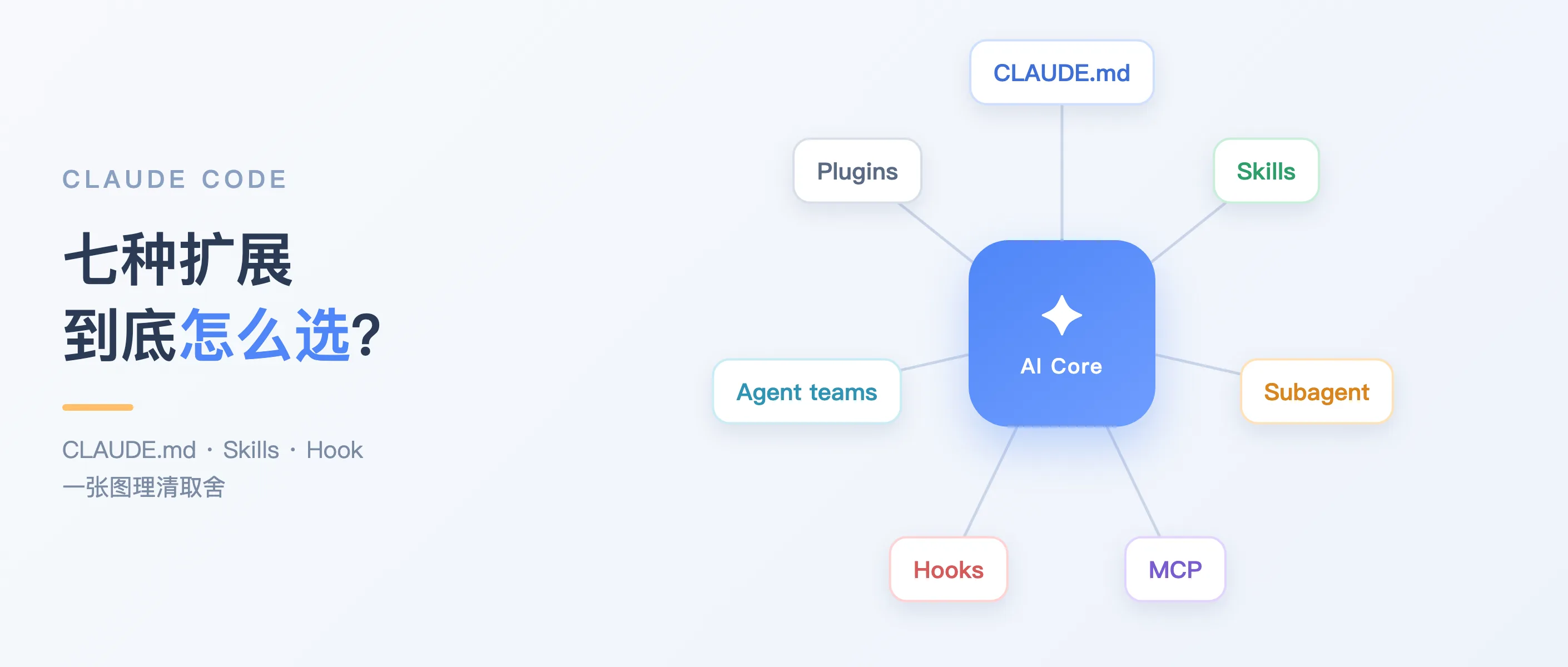
官方把扩展能力拆成了七块:CLAUDE.md、Skills、子代理(Subagent)、Agent teams、MCP、Hooks,以及把它们打包分发的插件(Plugins)。名字一多就容易犯选择困难症。这篇文章想做的,就是把「什么时候该用哪个」讲明白。
先有一张地图:它们各自插在 agent 循环的哪一环
Claude Code 的核心是一个会推理代码的模型 + 一圈内置工具构成的「智能体循环」。所有扩展,本质上都是往这个循环的不同位置插东西:
- CLAUDE.md:每次会话都会被加载的持久上下文,相当于 Claude 永远记得的「项目须知」。
- Skills(技能):可复用的知识、流程或指令,一个 Markdown 文件。可以用
/deploy这样的命令手动触发,也能让 Claude 在相关时自动加载。 - Code intelligence(代码智能):接上语言服务器(LSP),让 Claude 做符号级跳转、看实时类型错误。
- MCP:把 Claude 接到外部服务和工具上(数据库、Slack、浏览器……)。
- 子代理(Subagent):在隔离的上下文里跑自己的循环,只把摘要带回来。
- Agent teams(智能体团队):多个独立会话协同,共享任务列表、彼此直接通信(实验特性,默认关闭)。
- Hooks(钩子):在生命周期事件上触发,可以跑脚本、发 HTTP 请求、跑一段 prompt 或子代理。
- Plugins / Marketplaces:把上面这些打包、分发的层。
其中 Skills 是最灵活的一个。它既能当「知识库」(比如你团队的 API 风格指南),也能当「可触发的工作流」(比如 /deploy 跑一遍部署清单);既能在当前会话里运行,也能通过子代理在隔离上下文里跑。
按目标选特性:一张速查表
这些特性的差别,可以归结为三种「时机」:永远在线的上下文、按需调用的能力、事件触发的后台自动化。
| 特性 | 它做什么 | 什么时候用 | 例子 |
|---|---|---|---|
| CLAUDE.md | 每次会话自动加载的持久上下文 | 项目约定、「永远要做 X」的规则 | 「用 pnpm 不用 npm;提交前先跑测试」 |
| Skill | Claude 可用的指令、知识、工作流 | 可复用内容、参考文档、重复任务 | /deploy 跑部署清单;API 文档技能 |
| Subagent | 隔离上下文,只返回摘要结果 | 上下文隔离、并行任务、专职 worker | 读几十个文件做调研,只回关键结论 |
| Agent teams | 协调多个独立 Claude 会话 | 并行调研、新功能开发、竞争性假设调试 | 同时派出安全/性能/测试三个 reviewer |
| Code intelligence | 语言服务器导航与诊断 | 强类型语言、grep 又慢又不准的大库 | 直接跳到符号定义,而不是通读整个文件 |
| MCP | 连接外部服务 | 需要外部数据或动作 | 查数据库、发 Slack、控制浏览器 |
| Hook | 事件触发的脚本/请求/prompt/子代理 | 必须在每个匹配事件上发生的自动化 | 每次编辑文件后跑 ESLint |
插件(Plugins)是打包层:把若干 Skills、Hooks、子代理、MCP server 捆成一个可安装单元。插件里的技能会被加命名空间(如 /my-plugin:review),所以多个插件可以共存。当你想在多个仓库间复用同一套配置、或者分发给别人时,就该用插件。
不用一开始就配满:按「触发信号」逐步搭建
一个常见误区是开局就想把所有扩展配齐。其实每个特性都有一个可识别的触发信号,大多数团队是按下面这个顺序自然长出来的:
| 触发信号 | 该加什么 |
|---|---|
| Claude 把某个约定或命令搞错了两次 | 写进 CLAUDE.md |
| 你总在重复敲同一段开场 prompt | 存成一个可手动触发的 skill |
| 你第三次把同一份多步流程粘进对话 | 把它沉淀成 skill |
| 你总在从 Claude 看不到的浏览器标签页里抄数据 | 把那个系统接成 MCP server |
| Claude 为了找某个符号定义读了一堆文件 | 装一个对应语言的 code intelligence 插件 |
| 某个支线任务把对话刷满了你不会再看的输出 | 改用子代理来跑 |
| 你希望某件事「每次都自动发生」、不用问 | 写一个 hook |
| 第二个仓库需要同样这套配置 | 打包成插件 |
这套信号反过来也告诉你「什么时候该更新已有的东西」:一个反复犯的错误、一条反复出现的 review 意见,应该是一次 CLAUDE.md 的编辑,而不是聊天里的一次性纠正;一个你总在手动微调的工作流,是一个需要再迭代一版的 skill。
容易混的几对,怎么区分
有些特性长得很像,下面挑几对最容易搞混的说清楚。
Skill vs Subagent
最核心的区别:Skill 是可复用的内容,Subagent 是隔离的 worker。
- Skill 把知识/流程加载进当前上下文,会占用你的主窗口;
- Subagent 在单独的上下文窗口里干活,主对话只收到一份摘要。
所以:当你需要上下文隔离、或者主窗口快满了,就用子代理——它可能读了几十个文件、跑了大量搜索,但这些都不污染你的主对话。两者还能组合:子代理可以通过 skills: 字段预加载特定技能,而一个技能也能用 context: fork 在隔离上下文里运行。
CLAUDE.md vs Skill
两者都存指令,但加载方式不同:CLAUDE.md 每次会话自动全量加载,Skill 按需加载。
- 如果 Claude 应该永远知道(编码约定、构建命令、项目结构、「绝不做 X」),放 CLAUDE.md;
- 如果是有时才需要的参考资料(API 文档、风格指南)或一个用
/<name>触发的工作流,放 Skill。
经验法则:CLAUDE.md 控制在 200 行以内。如果它在膨胀,就把参考内容挪到 skills,或拆进 .claude/rules/ 文件。其中 rules 还能用 paths frontmatter 做到「只在处理匹配文件时才加载」,进一步省上下文。
Subagent vs Agent team
都能并行,但架构不同:
- Subagent 跑在你的会话内部,结果汇报回主上下文;主 agent 统一管理所有工作,token 成本更低。
- Agent team 是彼此独立的 Claude 会话,队友之间直接通信、共享任务列表自协调;每个队友都是一个独立 Claude 实例,token 成本更高。
判断分界点:如果你在跑并行子代理但撞上了上下文上限,或者子代理之间需要互相通信,那 agent team 就是自然的下一步。(注意:agent teams 目前是实验特性,默认禁用。)
MCP vs Skill
MCP 提供连接,Skill 提供「怎么用好这个连接」的知识,两者是搭配关系。典型例子:MCP server 把 Claude 接到你的数据库,而一个 skill 教会 Claude 你的数据模型、常用查询模式、不同任务该用哪张表。
Hook vs Skill
一句话:Hook 在生命周期事件上触发,Skill 是被加载进上下文供 Claude 参考。
- Hook 的触发是确定性的——事件一到必然执行,不需要 Claude「思考」;
- Skill 由 Claude 解释执行,结果可能有变化。
这里有个特别重要的点:护栏要用 hook,而不是 prompt。在 CLAUDE.md 或 skill 里写「永远别改 .env」,那只是一个请求,不是保证;而一个 PreToolUse hook 去拦截这个编辑,才是真正的强制。如果某条规则必须每次都成立,就把它做成 hook,而不是一句提示。
同一个特性出现在多个层级时,怎么叠加
特性可以定义在多个层级:用户级、项目级、插件、或受管策略(managed policy);CLAUDE.md 还能在子目录里嵌套。当同一个特性在多个层级都存在时,叠加规则各不相同:
- CLAUDE.md 是叠加式的:所有层级的内容同时进入上下文。工作目录及其上层的文件在启动时加载,子目录的随着你进入而加载。指令冲突时,Claude 自行权衡,通常更具体的指令优先。
- Skills / Subagents 按名字覆盖:同名时按优先级取一个(技能:managed > user > project;子代理:managed > CLI flag > project > user > plugin)。插件技能有命名空间,不会冲突。
- MCP server 按名字覆盖:local > project > user。
- Hooks 是合并的:所有注册的 hook 都会在匹配事件上触发,不分来源。
真实场景里,它们是组合着用的
每个扩展各擅长一件事,真实配置往往是把它们拼起来。比如:CLAUDE.md 放项目约定,一个 skill 放部署流程,MCP 连数据库,一个 hook 在每次编辑后跑 lint。几个常见组合:
| 组合 | 怎么配合 | 例子 |
|---|---|---|
| Skill + MCP | MCP 给连接,skill 教怎么用好 | MCP 连数据库,skill 记录 schema 与查询模式 |
| Skill + Subagent | skill 派生子代理做并行工作 | /audit 技能拉起安全/性能/风格三个隔离子代理 |
| CLAUDE.md + Skills | CLAUDE.md 放常驻规则,skill 放按需参考 | CLAUDE.md 说「遵循我们的 API 约定」,skill 是完整风格指南 |
| Hook + MCP | hook 通过 MCP 触发外部动作 | 编辑关键文件后,hook 发一条 Slack 通知 |
别忽视:上下文成本
这是最容易被新手忽略的一环。你加的每一个特性都会消耗 Claude 的上下文。加太多不只是把上下文窗口塞满,还会引入噪音让 Claude 变笨——技能可能不该触发的时候触发、或者它把你的约定弄丢。
各特性的加载策略与成本:
| 特性 | 何时加载 | 加载什么 | 上下文成本 |
|---|---|---|---|
| CLAUDE.md | 会话开始 | 全部内容 | 每个请求都带着 |
| Skills | 会话开始 + 使用时 | 开始时只加载描述,用时才加载全文 | 低(描述每个请求都在)* |
| MCP server | 会话开始 | 工具名;完整 schema 按需加载 | 用到具体工具前都很低 |
| Code intelligence | 编辑后 / 按需 | 编辑后给诊断,查符号时给定位 | 低;还能减少别处的文件读取 |
| Subagent | 被派生时 | 全新隔离上下文 | 与主会话隔离 |
| Hook | 触发时 | 默认什么都不加载(外部运行) | 零,除非 hook 返回了额外内容 |
* 默认情况下,技能的描述会在会话开始时加载,好让 Claude 自己决定何时用。如果某个技能你只想自己手动触发,在它的 frontmatter 里设 disable-model-invocation: true,就能把它从 Claude 眼前彻底藏起来,上下文成本归零——对有副作用的技能(比如部署)尤其推荐这么做。对于不是你写的技能,可以在 settings 里用 skillOverrides 达到同样效果,而不必改它的文件。
小结:怎么记住这套心智模型
把七个特性塞回三个问题里就清楚了:
- Claude 该不该永远知道这件事? → 是,写 CLAUDE.md(或拆进 rules)。
- 这是有时才需要的知识/可触发的流程吗? → 是,做成 Skill;要隔离上下文就配 Subagent,要多方协作就上 Agent team;要连外部系统就接 MCP。
- 这件事必须每次自动、确定性地发生吗? → 是,写 Hook。
最后,别忘了「逐步搭建」这条原则:不要一开局就配满,让每个特性在真实的触发信号出现时再加进来。配置是长出来的,不是设计出来的。
关于
关注我获取更多资讯

