
引言:Transformer 如何重塑 AI 格局
在短短几年内,Transformer 架构彻底重塑了人工智能 (AI) 的技术版图。由 Vaswani 等人在其里程碑式的论文《Attention Is All You Need》中提出的 Transformer,展示了一种在处理序列数据时完全无需循环 (Recurrence) 或卷积 (Convolution) 的独特方法。Transformer 最初在自然语言处理 (NLP) 领域取得突破,并迅速成为跨多个领域(包括图像识别、视频分析甚至语言翻译)最先进模型(State-of-the-Art)的通用框架。
在 NLP 领域,Transformer 取代了传统的基于 RNN 和 LSTM 的系统,使得模型能够更有效地捕捉长距离依赖关系,并且可以并行训练,极大地提高了准确性和效率。不久之后,视觉研究人员将 Transformer 应用于计算机视觉任务,催生了像视觉 Transformer (Vision Transformers, ViTs) 这样的架构,它们如今已能与卷积神经网络 (CNNs) 相媲美,甚至常常超越后者。这种处理文本、图像及其他复杂模式的能力,使 Transformer 成为当今最强大 AI 系统(如 GPT、BERT、DALL·E 等)的核心支柱。
在本文中,你不仅将清晰地理解 Transformer 的工作原理及其高效的原因,还将亲手构建自己的 Transformer 模型。为了最大化学习效果(并加速实验),我们还将探讨如何利用 DigitalOcean Gradient™ AI GPU Droplets,它提供了训练和微调 Transformer 模型所需的计算能力,避免了漫长的等待和资源瓶颈。
什么是 Transformer?
在深入探讨 Transformer 及其架构之前,我们首先需要理解词嵌入 (Word Embedding) 及其重要性。
词嵌入 (Word embeddings) 将每个词元(token,可以是单词或子词)转换为模型可以处理的定长数字向量。由于神经网络处理的是数字而非文本,这一步至关重要。嵌入技术将语义相似的词在向量空间中置于相近的位置(例如,“国王 (king)” 和 “王后 (queen)” 的向量会很接近)。
简而言之,词嵌入是一种将词语表示为高维空间(如 300D, 512D, 1024D)中密集向量的方法,其中:
- 相似的词在空间中彼此靠近。
- 不相似的词则相距甚远。
- 向量间的几何关系(如距离、角度)反映了词语的语义和句法关系。
例如: “king” → [0.25, -0.88, 0.13, …] “queen” → [0.24, -0.80, 0.11, …] “apple” → [-0.72, 0.13, 0.55, …]
在这里,"king" 和 "queen" 的向量会比它们各自与 "apple" 的向量更接近。这些词嵌入并非手动设定,而是在训练阶段学习得到的。
最初,每个词被赋予一个随机向量。在训练过程中(如语言建模、翻译等任务),网络会不断更新这些向量,使得在相似上下文中使用的词获得相似的向量,从而为特定任务有意义地聚合词语。
在 Transformer 中,嵌入是第一步。
从词嵌入到上下文嵌入
让我们以单词 “bank” 为例。无论它表示“河岸 (river bank)” 还是“银行 (money bank)”,传统的静态词嵌入都会赋予它相同的向量。因此,静态嵌入在这种情况下可能无法奏效。为此,Transformer 模型引入了上下文嵌入 (Contextual embedding)(动态嵌入)。这类嵌入会根据周围词语动态生成一个变化的向量。
"I sat by the bank of the river"→ 嵌入向量会偏向自然的含义。"I deposited money at the bank"→ 嵌入向量会偏向金融的含义。
因此,上下文嵌入会因句子的不同而变化。
位置编码:模型如何理解顺序
Transformer 以并行方式处理所有词元,因此它本身无法感知词语的顺序信息(这与按顺序处理的 RNN 不同)。为了让模型理解词元的顺序,我们需要将一个位置特定的向量添加到词嵌入中。
常用方法是使用正弦函数:对于位置 pos 和维度 i,
PE(pos, 2i) = sin(pos / 10000^(2i/d))PE(pos, 2i+1) = cos(pos / 10000^(2i/d))
这种方法为每个位置创建了独特且平滑变化的信号。当然,学习式的位置嵌入也是一种可行的替代方案。
现在,模型就能够区分“这是第 3 个词元”与“这是第 7 个词元”,这对理解句意(例如,主语在动词之前)至关重要。
Transformer 架构详解
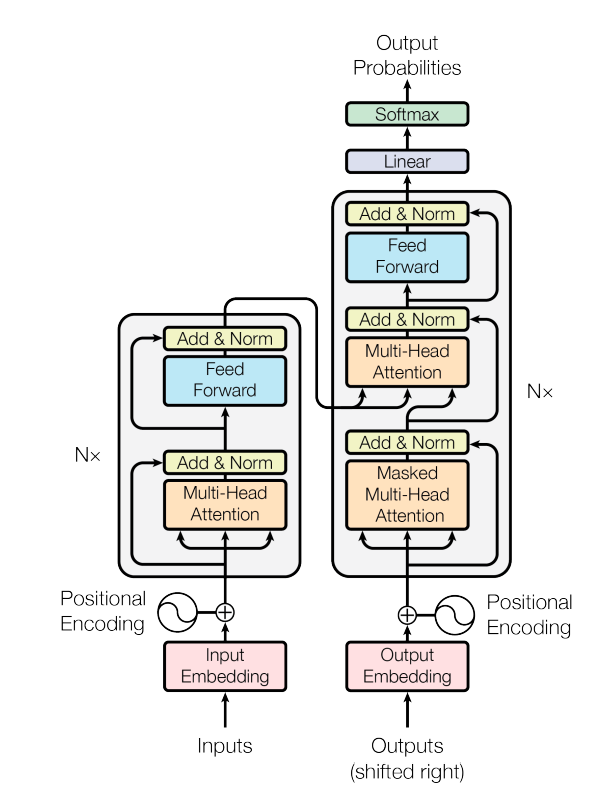
上图展示了 Transformer 的两个主要部分:编码器 (Encoder) 栈(左侧)和解码器 (Decoder) 栈(右侧)。编码器将输入词元转换为富含上下文信息的嵌入,而解码器则自回归地生成输出词元。每个栈都由 N 个相同的层堆叠而成(例如,N 可以是 6, 12, 24…),以增加模型的深度。
其工作流程可以概括为:
输入词元 → 输入嵌入 + 位置编码 → 编码器层 (自注意力 + 前馈网络) → 编码器输出
解码器接收偏移的输出嵌入 + 位置编码 → 掩码自注意力 → 编码器-解码器注意力 → 前馈网络 → 线性层 → Softmax → 输出词元概率
输入嵌入 + 位置编码
输入嵌入是将文本中的单词或词元转换为模型能够理解的数字的过程。这就像将人类语言翻译成模型能“说”的密码。
然而,仅有这个密码并不能告诉模型每个词在句子中的位置。这时位置编码 (Positional Encoding) 就派上用场了:它为每个嵌入添加一个独特的数字模式,以表示每个词元在序列中的位置(第一个、第二个、第三个等)。通过将两者结合,模型既能知道每个词的含义,也能知道它在句子中的位置,这对于理解上下文和顺序至关重要。
编码器层
Transformer 中的编码器层 (Encoder Layer) 是一个可重复堆叠的基本构建块(在原始 Transformer 中重复了 6 次)。每个编码器层包含两个主要部分:
-
多头自注意力机制 (Multi-Head Self-Attention):允许输入序列中的每个词元关注所有其他词元,从而计算出每个词元对于理解当前词元的重要性。这帮助模型捕捉整个序列中的复杂关系,例如“谁对谁做了什么”。
-
位置前馈网络 (Position-wise Feed-Forward Network):独立地处理每个词元更新后的表示,对其进行非线性变换和特征提炼。
在这两个子层的周围,还包裹着残差连接 (Residual Connections)(将输入直接加到输出上,形成“捷径”)和层归一化 (Layer Normalization)(稳定学习过程),确保信息流畅传递并保持训练的稳定性。通过堆叠多个相同的编码器层,Transformer 能够构建出对输入文本越来越丰富、上下文感知越来越强的表示。
解码器层
解码器层同样由多个相同的块堆叠而成,但它包含三个主要部分:
-
掩码多头自注意力 (Masked Multi-Head Self-Attention):在这一部分,解码器中的每个词元只能“看到”它自己及之前位置的词元。这是通过一个“前瞻掩码 (look-ahead mask)” 实现的,它阻止模型在生成当前词时偷看未来的词,确保了文本是按顺序一步步生成的。
-
编码器-解码器注意力 (Encoder-Decoder Attention):也称为交叉注意力 (Cross-Attention)。解码器的查询 (Query) 来自其前一层的输出,而键 (Key) 和值 (Value) 则来自编码器的最终输出。这种机制让解码器在生成每个输出词元时,能够聚焦于输入句子中最相关的部分。
-
位置前馈网络 (Position-Wise Feed-Forward Network):与编码器层类似,用于进一步处理和提炼每个词元的表示。
每个子层之后同样应用了残差连接和层归一化 (LayerNorm) 来稳定训练。当最顶层的解码器完成工作后,其输出会通过一个线性投影层和 Softmax 函数,最终转化为词汇表中每个词的概率分布。
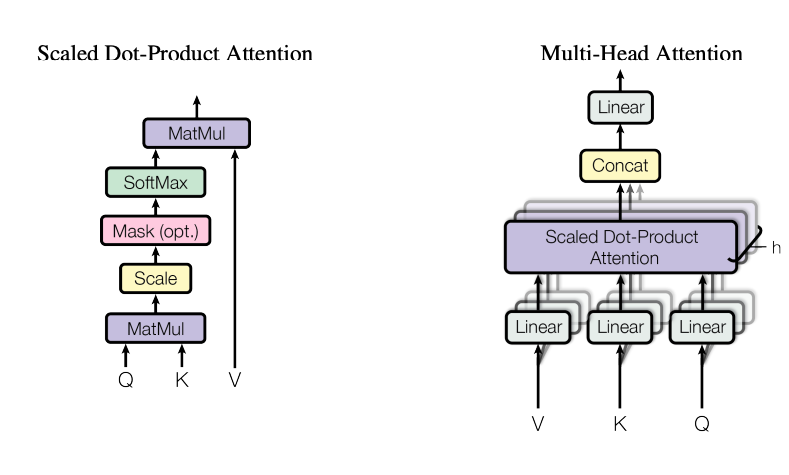
注意力机制的核心数学原理
线性投影(每个头)
输入序列嵌入 X (形状为 seq_len × d_model) 被投影到三个不同的空间中:
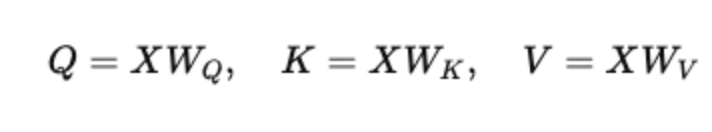
其中 WQ, WK, WV 是可学习的权重矩阵,形状为 (d_model × d_k)。这些投影让模型学习如何查询、比较和检索相关信息。
缩放点积注意力 (Scaled Dot-Product Attention)
-
计算每个查询 (Query) 与所有键 (Key) 之间的相似度得分:
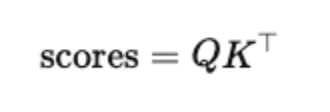
-
将得分除以
sqrt(d_k)进行缩放,以避免过大的值导致 Softmax 函数不稳定: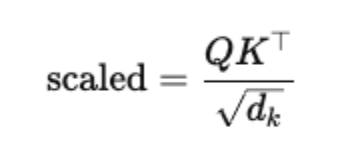
-
对键维度应用 Softmax,将得分转化为注意力权重:
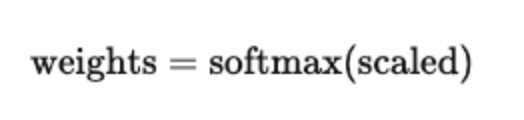
-
将权重乘以值 (Value)
V,得到值向量的加权和。
多头注意力 (Multi-Head Attention, MHA)
-
将上述过程并行重复
h次,每次使用不同的参数集: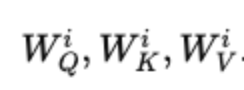
-
每个“头”专注于序列中不同的关系或特征。
-
将所有头的输出拼接起来,并通过另一个线性投影
WO恢复到d_model维度。
掩码注意力 (Masked Attention)
- 目的:防止模型关注某些位置。
- 因果掩码 (Causal Mask):在自回归任务中,阻止对当前位置之后词元的注意力。
- 填充掩码 (Padding Mask):在处理变长序列时,忽略填充 (padding) 位置。
- 实现方式:在 Softmax 之前,将不希望关注位置的得分加上一个非常大的负数(如
-∞):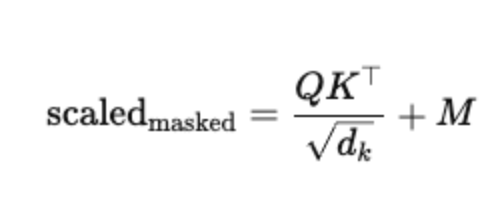 其中
其中 M矩阵中,允许的位置为 0,屏蔽的位置为-∞。经过 Softmax 后,这些位置的概率将趋近于零。
为什么使用 GPU 训练 Transformer?
训练 Transformer 模型,无论是用于自然语言处理、计算机视觉还是多模态任务,都需要巨大的计算能力。Transformer 使用多头注意力、大规模矩阵乘法和深度网络层,必须同时处理数百万甚至数十亿的参数。在 CPU 上,这些操作可能需要几天甚至几周才能完成,这使得模型开发和迭代变得极其缓慢。
GPU (Graphics Processing Units) 专为高吞吐量的并行计算而设计,这使它们成为加速 Transformer 训练的完美工具。与专为顺序处理设计的 CPU 不同,GPU 拥有数千个较小的核心,可以同时执行许多操作。这种并行架构极大地缩短了训练时间;在 CPU 上可能需要数周的任务,在 GPU 上可以在数小时或数天内完成。
为了让 GPU 的强大算力更易于获取,DigitalOcean Gradient™ AI GPU Droplets 提供了按需访问强大 GPU 实例的服务,无需处理复杂的基础设施。你可以在几分钟内创建一个用于 AI/ML 任务的环境,并且只为你使用的资源付费。
环境准备:在 DigitalOcean 上设置 GPU 环境
- 创建并添加 SSH 密钥:如果你还没有 SSH 密钥,请先创建一个,并将其添加到你的 DigitalOcean 账户。
- 创建 GPU Droplet:
- 登录 DigitalOcean,点击 Create -> Droplets。
- Datacenter:选择一个离你最近的区域。
- Choose an image -> Marketplace:搜索并选择 AI/ML Ready 模板。
- Choose a plan -> GPU:选择一个 GPU 选项,例如 Single H100。
- Authentication:选择你之前添加的 SSH 密钥。
- 为你的 Droplet 命名并创建它。
- 通过 SSH 连接到 Droplet:
- 从控制台复制 Droplet 的 IPv4 地址。
- 在本地终端运行:
ssh root@<your_ipv4_address> - 安装依赖并启动 Jupyter:
# (可选) 创建一个新用户 useradd -m -g users <username> su <username> cd ~ # 安装依赖 sudo apt update sudo apt install python3-pip python3.10-venv -y python3 -m venv myenv source myenv/bin/activate pip install jupyterlab # 启动 Jupyter Lab,注意使用 0.0.0.0 作为 IP jupyter lab --ip=0.0.0.0 - 访问 Jupyter Lab:
- Jupyter 启动后会提供一个带有 token 的 URL,例如
http://127.0.0.1:8888/lab?token=...。 - 在你的本地浏览器中,将
127.0.0.1替换为你的 Droplet 的 IPv4 地址并访问该 URL。
- Jupyter 启动后会提供一个带有 token 的 URL,例如
现在,你就可以在本地浏览器中运行 JupyterLab,并利用 DigitalOcean Droplet 提供的 GPU 加速了。
动手实践:训练一个 Transformer 模型
我们将构建一个轻量级的 Transformer 文本分类器,用于处理 Kaggle 的“Disaster Tweets”数据集。这个数据集包含一个 text 列和一个二元 target (0/1)。
准备工作
- 从 Kaggle 的 Real or Not? NLP with Disaster Tweets 比赛页面下载
train.csv文件,并将其放置在你的工作目录中。 - 安装所需的 Python 库:
pip install torch pandas scikit-learn numpy - 在 Jupyter Lab 中创建一个新的 Notebook,并将以下代码粘贴进去运行。
Transformer 训练代码
import re
import math
import random
import time
import os
import numpy as np
import pandas as pd
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# ====== 配置参数 ======
DATA_PATH = "./train.csv"
MAX_LEN = 50
MIN_FREQ = 2
BATCH_SIZE = 64
EMBED_DIM = 128
FF_DIM = 256
N_HEADS = 4
N_LAYERS = 2
DROPOUT = 0.1
LR = 3e-4
EPOCHS = 5
SEED = 42
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
print(f"Using device: {DEVICE}")
# ====== 加载数据集 ======
df = pd.read_csv(DATA_PATH)[["text", "target"]].dropna()
train_df, val_df = train_test_split(df, test_size=0.15, stratify=df["target"], random_state=SEED)
# ====== 分词器与词汇表 ======
def simple_tokenizer(text):
text = text.lower()
return re.findall(r"\b\w+\b", text)
counter = Counter()
for text in train_df["text"]:
counter.update(simple_tokenizer(text))
# 特殊词元
PAD_TOKEN = "<pad>"
UNK_TOKEN = "<unk>"
BOS_TOKEN = "<bos>"
EOS_TOKEN = "<eos>"
itos = [PAD_TOKEN, UNK_TOKEN, BOS_TOKEN, EOS_TOKEN] + [w for w, c in counter.items() if c >= MIN_FREQ]
stoi = {tok: i for i, tok in enumerate(itos)}
PAD_IDX = stoi[PAD_TOKEN]
BOS_IDX = stoi[BOS_TOKEN]
EOS_IDX = stoi[EOS_TOKEN]
def text_to_ids(text):
tokens = [BOS_TOKEN] + simple_tokenizer(text)[:MAX_LEN-2] + [EOS_TOKEN]
ids = [stoi.get(tok, stoi[UNK_TOKEN]) for tok in tokens]
# 填充或截断
if len(ids) < MAX_LEN:
ids += [PAD_IDX] * (MAX_LEN - len(ids))
else:
ids = ids[:MAX_LEN]
return ids
# ====== 数据集类 ======
class TextDataset(Dataset):
def __init__(self, df):
self.texts = df["text"].tolist()
self.labels = df["target"].astype(int).tolist()
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
ids = torch.tensor(text_to_ids(self.texts[idx]), dtype=torch.long)
label = torch.tensor(self.labels[idx], dtype=torch.long)
return ids, label
train_ds = TextDataset(train_df)
val_ds = TextDataset(val_df)
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE)
# ====== 位置编码 ======
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer("pe", pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1), :]
# ====== 模型定义 ======
class TransformerClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, num_heads, ff_dim, num_layers, num_classes, pad_idx, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=pad_idx)
self.pos_encoding = PositionalEncoding(embed_dim)
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dim_feedforward=ff_dim, dropout=dropout, batch_first=True)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc = nn.Linear(embed_dim, num_classes)
self.pad_idx = pad_idx
def forward(self, ids):
mask = (ids == self.pad_idx)
x = self.embedding(ids)
x = self.pos_encoding(x)
x = self.encoder(x, src_key_padding_mask=mask)
x = x[:, 0, :] # 使用 [BOS] 词元的输出来进行分类
return self.fc(x)
model = TransformerClassifier(len(itos), EMBED_DIM, N_HEADS, FF_DIM, N_LAYERS, 2, PAD_IDX, DROPOUT).to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
# ====== 训练循环 ======
for epoch in range(1, EPOCHS + 1):
model.train()
train_loss = 0
for ids, labels in train_loader:
ids, labels = ids.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
output = model(ids)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 验证
model.eval()
val_loss, preds_all, labels_all = 0, [], []
with torch.no_grad():
for ids, labels in val_loader:
ids, labels = ids.to(DEVICE), labels.to(DEVICE)
output = model(ids)
loss = criterion(output, labels)
val_loss += loss.item()
preds_all.extend(torch.argmax(output, dim=1).cpu().numpy())
labels_all.extend(labels.cpu().numpy())
acc = accuracy_score(labels_all, preds_all)
f1 = f1_score(labels_all, preds_all, average="macro")
print(f"Epoch {epoch}: Train Loss={train_loss/len(train_loader):.4f}, Val Loss={val_loss/len(val_loader):.4f}, Acc={acc:.4f}, F1={f1:.4f}")
print("Training complete.")
# ====== 随机抽样预测 ======
model.eval()
sample_indices = random.sample(range(len(val_df)), 5)
for idx in sample_indices:
text = val_df.iloc[idx]["text"]
true_label = val_df.iloc[idx]["target"]
ids = torch.tensor(text_to_ids(text), dtype=torch.long).unsqueeze(0).to(DEVICE)
with torch.no_grad():
pred = torch.argmax(model(ids), dim=1).item()
print(f"Text: {text[:80]}...")
print(f"True: {true_label}, Pred: {pred}")
print("-" * 50)
常见问题 (FAQs)
1. 什么是 Transformer?为什么它如此流行? Transformer 是一种深度学习架构,它使用自注意力机制来并行处理输入数据,而非像 RNN 那样按顺序处理。这使其非常高效和可扩展,在翻译、摘要和图像分类等任务中取得了突破。它们捕捉长距离依赖关系和处理大型数据集的能力,使其成为现代 AI 研究的首选。
2. 为什么应该在 GPU 上训练 Transformer? Transformer 涉及大量计算密集的矩阵乘法和注意力计算。GPU 专为并行处理而设计,能极大地加速训练。没有 GPU,训练可能需要数天甚至数周;而使用 GPU,则可以缩短到几小时。
3. 什么是混合精度训练?它有什么帮助? 混合精度训练在训练过程中同时使用 16 位和 32 位浮点数。这可以减少内存占用并加速计算,而不会显著影响模型精度,尤其是在具有针对 FP16 运算优化的 Tensor Cores 的 GPU 上效果更佳。
4. 如何为 Transformer 训练选择合适的批量大小 (batch size)? 批量大小影响训练速度、收敛性和内存使用。较小的批量大小占用内存较少,但可能导致收敛过程不稳定;较大的批量大小更稳定,但内存消耗大。通常最好在你的硬件上尝试不同的大小以找到平衡点。
5. 我应该从头开始训练 Transformer,还是使用预训练模型?
从头训练资源消耗巨大,且需要庞大的数据集。大多数实践者会从一个预训练好的 Transformer 开始,然后在自己的特定数据集上进行微调 (fine-tuning)。像 Hugging Face 的 transformers 这样的库使这个过程变得非常简单。
总结与展望
在本文中,我们探讨了 Transformer 模型的核心概念,理解了其模型架构和关键组件。我们还从零开始,实践了模型训练的核心步骤,包括数据集预处理、模型架构定义以及模型推理。
虽然我们专注于一个相对较小且易于管理的数据集来演示概念,但相同的原则也适用于大规模任务。对于生产级工作负载,高效扩展训练能力至关重要。这正是云 GPU 解决方案能够显著加速你工作流程的地方。
通过将强大的模型设计与可扩展的 GPU 基础设施相结合,你可以更快、更轻松地从原型走向生产。
后续步骤
- 尝试使用来自 Kaggle 或 Hugging Face Datasets 的更大数据集进行实验。
- 在一个特定领域的任务上微调一个预训练的 Transformer 模型。
- 实现更高级的优化,如学习率预热 (learning rate warm-up)、权重衰减 (weight decay) 或梯度裁剪 (gradient clipping)。
- 将你训练好的 Transformer 模型部署到 DigitalOcean App Platform 或 GPU Droplet 上,以提供实时推理服务。
关于
关注我获取更多资讯

