引言:本地运行 LLM 的挑战与 Ollama + Docker 的解决方案
大多数开发者都希望尝试本地运行大型语言模型(LLM),但往往不知从何开始。随着 Llama 和 Mistral 等开源模型的兴起,本地 AI 的可访问性达到了前所未有的高度。你不再需要为 OpenAI 或 Anthropic 等服务支付高昂费用,也不必担心数据被发送到第三方。然而,挑战在于传统的设置指南通常涉及管理复杂的 Python 环境、CUDA 驱动和各种依赖项,这些配置在不同机器间迁移时常会引发问题。
Ollama 通过提供一种极其简单的方式来运行本地 LLM,从而解决了这些痛点。当将其与 Docker 结合使用时,你将获得一个整洁、可移植的解决方案,确保在不同系统上都能保持一致的运行效果。
本指南将向你展示如何在 Docker 中设置 Ollama,拉取你的第一个模型,并开始运行可供任何应用访问的本地 LLM。
如果你对 Docker 完全陌生,建议你先学习 Docker 入门 课程,以掌握其基础知识。
什么是 Ollama?
你可以将 Ollama 视为在个人硬件上运行大语言模型最简单的方式。
它是一个轻量级的运行时,负责处理本地 LLM 的所有繁重工作。你无需管理 Python 环境,手动安装 CUDA 驱动,或费心处理模型权重和分词器。Ollama 仅需一个命令即可完成 LLaMA、Mistral 和 Gemma 等模型的下载、加载和服务。
Ollama 内置了隐私保护功能。你的对话内容永远不会离开你的机器。没有 API 密钥,没有使用跟踪,也没有数据发送到外部服务器。这使得它非常适合处理敏感工作,在这些场景下,你不能冒将专有代码或个人信息暴露给第三方服务的风险。
Ollama 专为开发者设计,它原生支持 macOS 和 Linux,提供一个简单的 REST API 便于集成,现在也支持在 Docker 容器中运行。这意味着你可以在开发过程中使用相同的本地设置,并将其部署到任何支持 Docker 的环境。
你将获得一个生产就绪的 LLM 服务器,只需一个命令即可启动并支持离线工作。
Ollama 并非唯一的 LLM 运行时,你也可以尝试 n8n 和 Qdrant。
为什么选择 Docker 运行 Ollama?
答案很简单——你可以在享受 Ollama 全部优势的同时,保持系统环境的清洁。
直接在机器上运行 Ollama 效果良好——它以打包安装程序(Windows 为 .exe,Mac 为 .dmg)的形式提供,可以为你处理一切。但 Docker 提供了一个关键优势:隔离性。
通过 Docker,Ollama 在其独立的容器中运行。这能保持你的宿主系统整洁。你的主系统上不会留下任何安装痕迹,测试完成后也不会有残留文件,当你想要切换版本或彻底清理时,也能轻松移除。
得益于其可复现性,同一套设置适用于团队中的每个人。只需共享一个 Docker 命令,无论是在 macOS、Linux 还是 Windows 上,任何人都可以运行完全相同的 Ollama 环境。
跨平台支持让部署变得简单。在你的笔记本电脑上运行的同一个容器,无需修改即可在云服务器、CI/CD 流水线或同事的机器上工作。
通过简化的设置和销毁流程,你可以在几秒钟内启动 Ollama,并以同样快的速度将其完全移除。没有卸载脚本,没有四处寻找配置文件,也没有系统清理的烦恼。
这使得 Docker 成为以下场景的理想选择:
- 测试不同的模型,而无需进行完整安装
- 构建与本地 LLM 集成的应用程序
- 创建可供多个团队成员共享的开发环境
- 在不希望修改基础系统的服务器上运行 Ollama
简而言之,你将获得本地 LLM 的所有优势,而无需面对任何设置上的麻烦。
需要更多实用的 Docker 资源?这篇关于 12 个用于机器学习和 AI 的 Docker 容器镜像 的文章将助你入门。
在 Docker 中设置 Ollama
你只需三条命令即可在 Docker 中运行 Ollama。
首先,从 Docker Hub 拉取官方的 Ollama 镜像:
docker pull ollama/ollama
拉取 Ollama 镜像
接下来,使用正确的端口和数据卷映射来运行容器:
docker run -d --name my-ollama.docker -p 11434:11434 -v ollama:/root/.ollama ollama/ollama
运行 Ollama
以下是每个参数的含义:
-d:在后台运行容器。--name my-ollama.docker:为你的容器指定一个友好的名称。-p 11434:11434:将 Ollama 的默认端口映射到你的宿主机器。-v ollama:/root/.ollama:为下载的模型创建了一个持久化卷(volume)。
容器会立即启动,并开始监听 http://localhost:11434。
Ollama 在本地运行
现在下载一个模型来测试一切是否正常工作:
docker exec -it my-ollama.docker ollama pull llama3.1
拉取 Llama 3.1 模型
这将在你的容器内部下载 Llama 3.1 8b 模型。该模型大小约为 5GB,因此下载可能需要几分钟。
你可以通过列出可用模型来验证设置:
docker exec -it my-ollama.docker ollama list
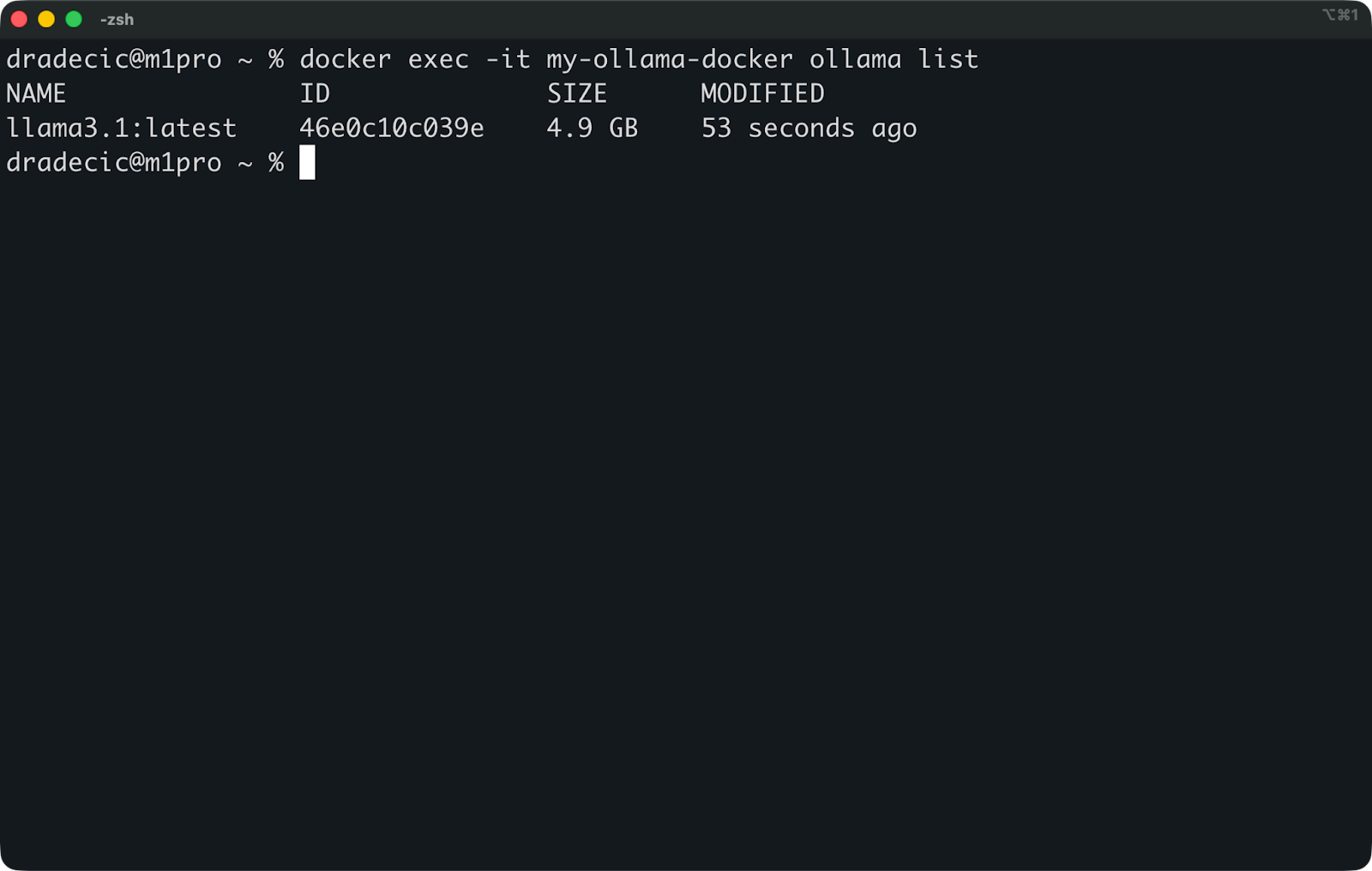
列出可用模型
数据卷映射非常重要。如果没有它,当容器停止时,你将丢失所有下载的模型。ollama:/root/.ollama 数据卷能够在容器重启和更新之间持久化你的模型。
对于生产环境设置,你可能希望构建预加载模型的自定义镜像。创建一个 Dockerfile,在构建过程中下载模型:
FROM ollama/ollama
COPY . /app
WORKDIR /app
RUN ollama pull llama3.1
这会将模型烘焙(bake)到你的镜像中,这样新的容器启动时就万事俱备了。
通过 Docker 使用 Ollama 进行推理
一旦你的容器开始运行,Ollama 就像任何其他 REST API 一样工作。
服务在 http://localhost:11434 监听,并接受标准 HTTP 请求。你不需要特殊的客户端或 SDK——只需发送 JSON 并接收响应即可。
以下是使用 curl 命令生成文本的方法:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Why is the sky blue?"
}'

使用 curl 访问 Ollama
API 返回一个包含生成文本的 JSON 响应。将 "stream": false 设置为一次性获取完整响应,或将 "stream": true 设置为在生成时接收 token。
Python 集成同样简单:
import ollama
response = ollama.chat(model='llama3.1', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
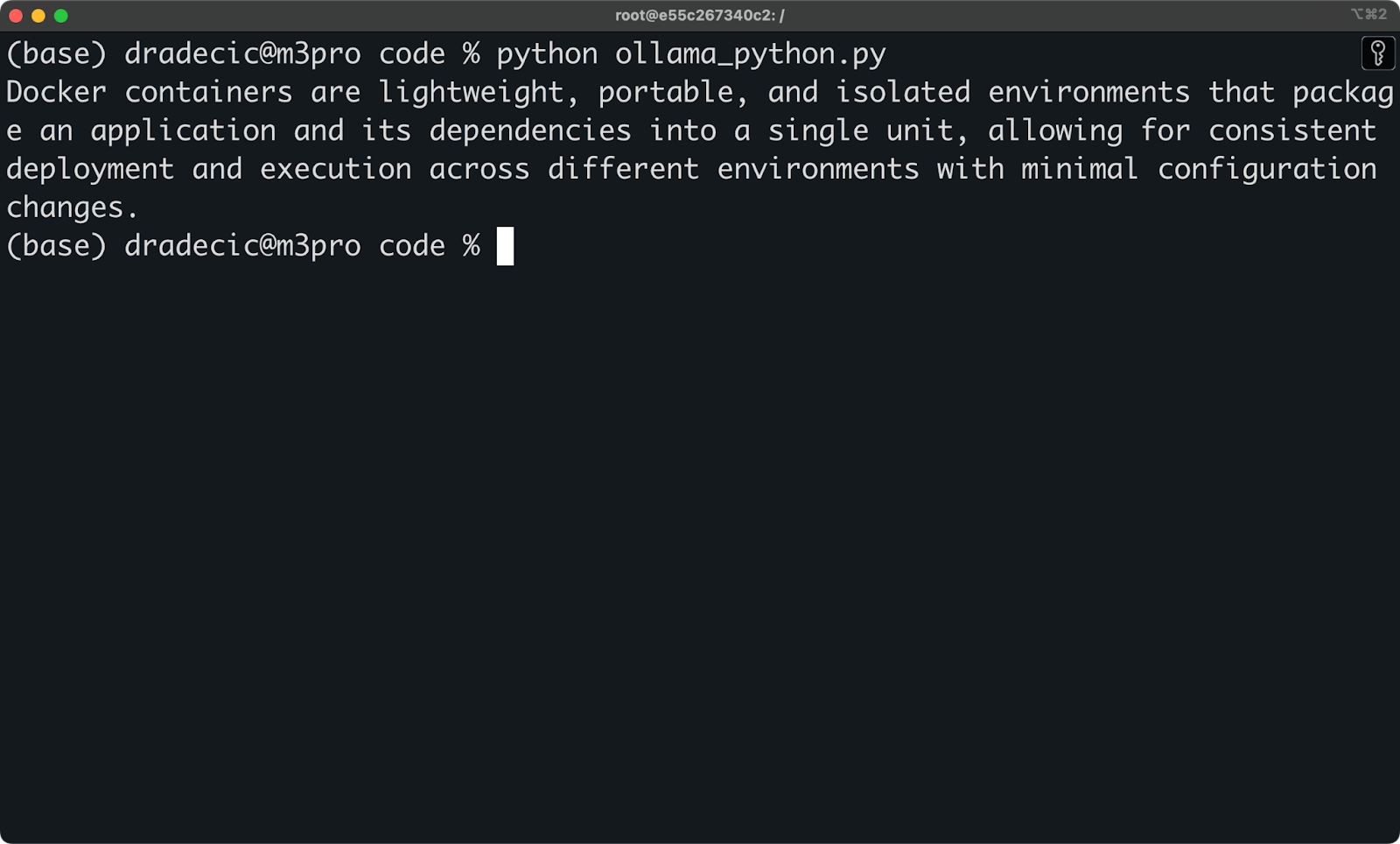
使用 Python 访问 Ollama
这使得 Ollama 非常适合作为本地应用程序的后端。你可以构建聊天界面、代码补全工具或文档分析系统,它们可以与你的容器化 LLM 对话,而无需将数据发送到外部服务。
对于更复杂的工作流,LangChain 集成也开箱即用:
from langchain_community.llms import Ollama
from langchain_core.prompts import ChatPromptTemplate
llm = Ollama(model="llama3.1")
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Respond in markdown."),
("human", "{question}"),
])
chain = prompt | llm
response = chain.invoke({"question": "Why is the sky blue?"})
print(response)
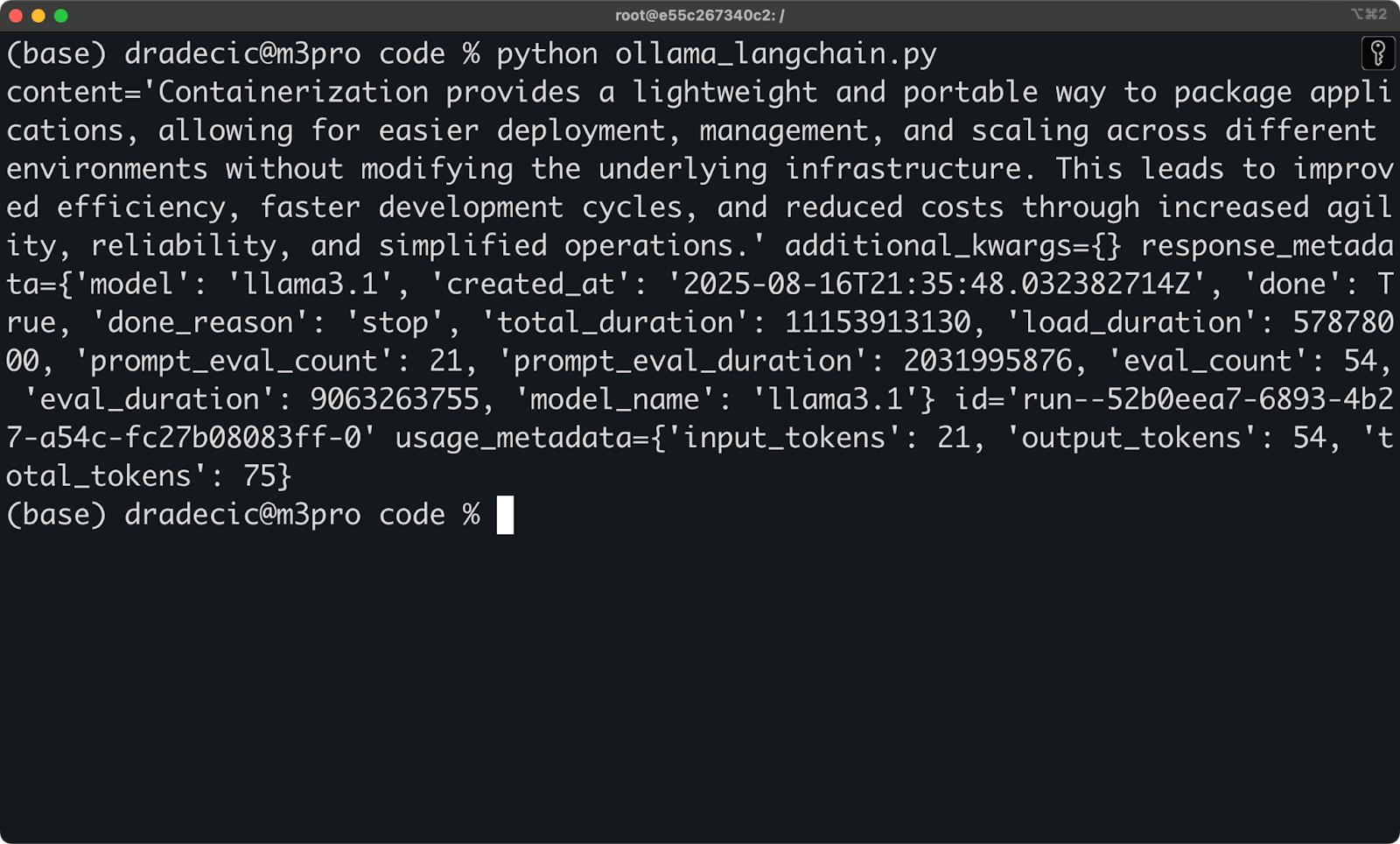
使用 LangChain 访问 Ollama
你将获得本地 LLM 的所有强大功能,同时享受 HTTP 请求的简洁性。
你是否曾好奇 LLM 应用程序是如何部署的?请阅读我们关于 使用 Docker 部署 LLM 应用程序 的分步指南。
性能考量:硬件要求与 Docker 开销
本地 LLM 需要强大的硬件才能良好运行,而 Docker 会增加一些自身的开销。
CPU 与 GPU 的性能差异巨大。Ollama 可以在纯 CPU 系统上运行,但推理速度会很慢,简单响应可能需要 30 秒以上。使用现代 GPU,相同的查询可在 5 秒内完成。NVIDIA GPU 表现最佳,但 Apple Silicon Macs 的性能也很好,且可能更具性价比。
RAM 要求随模型大小而变化。像 Llama3.1 8B 这样的小型模型至少需要 8GB 系统 RAM,而更大的 70B 版本则需要 64GB 或更多。模型在使用时会一直加载在内存中,因此你无法在只有 8GB RAM 的机器上运行 13B 模型。
磁盘空间会迅速增加。每次模型下载都会占用数 GB 的磁盘空间:
- 7B 参数模型:4-8GB
- 13B 参数模型:8-16GB
- 70B 参数模型:40-80GB
多个模型版本和量化(quantization)会迅速增加存储需求。如果存储空间不足,你可以将模型卸载到外部硬盘。
Docker 容器的计算开销很小,但存储开销值得关注。基础 Ollama 镜像不到 1GB,但模型会持久化在 Docker 数据卷中。如果你正在构建预加载模型的自定义镜像,预计每个镜像都会比基础镜像大几 GB。
然而,Docker 中的内存分配可能需要关注。默认情况下,Docker Desktop 会限制容器内存。对于更大的模型,你可能需要增加这些限制,或者在运行容器时使用 --memory 标志。
硬件瓶颈通常是 RAM,而非 CPU 或磁盘速度。
流行用例:Docker + Ollama 的应用场景
Docker + Ollama 组合为你提供了 AI 能力,同时能保护数据隐私,并将 LLM 推理成本精确控制为零(不计电费和维护成本)。
本地 AI 助手是这种设置大放异彩的领域。你可以创建完全在本地机器上运行的代码补全工具、文档生成器或写作助手。无需 API 成本,没有速率限制,数据不会离开你的网络。只需将你的编辑器或 IDE 指向 localhost:11434 即可开始构建。
私有 RAG(Retrieval Augmented Generation)流水线的部署也变得更加容易。
你可以将公司文档加载到矢量数据库中,然后使用 Ollama 来回答相关问题。整个知识库都保留在内部,这对于不能接触外部 API 的法律、金融或专有信息至关重要。
离线聊天机器人开发允许你在没有互联网依赖的情况下进行对话式 AI 的原型设计和测试。这非常适合边缘部署、隔离网络环境或连接不可靠的情况。无论你是在线还是在 30,000 英尺的高空飞行,你的机器人都能以相同的方式工作。
在云部署之前进行模型实验可以节省金钱和时间。你可以在本地测试不同的模型、提示和配置,然后再投入昂贵的云推理。你可以在不烧掉 API 积分的情况下,基准测试性能、调整参数和验证输出。
团队也使用 Docker 和 Ollama 的这种设置来完成以下工作:
- 需要大量合成文本的训练数据生成
- 在内部处理敏感材料的内容审核
- 重视可复现性和隔离性的研究环境
- 无需外部依赖即可工作的演示应用程序
你将获得企业级的 AI 能力,而无需支付企业级的账单。
提示、限制与故障排除
在 Docker 中运行 Ollama 时,有一些注意事项可能会让你遇到麻烦。
GPU 支持需要额外的设置。官方的 Ollama Docker 镜像支持 NVIDIA GPU,但你需要首先安装 NVIDIA Container Toolkit,并在运行容器时传递 --gpus all 标志:
docker run -d --name my-ollama.docker -p 11434:11434 -v ollama:/root/.ollama --gpus all ollama/ollama
如果没有这个设置,Ollama 将回退到纯 CPU 模式,虽然可以工作但速度会慢得多。如果你使用的是 Apple Silicon MacBook,则无需担心此问题。
文件权限问题可能会导致 Docker 数据卷的麻烦。如果你挂载宿主目录而不是使用命名数据卷,Ollama 可能由于权限不匹配而无法写入模型文件。使用 -v ollama:/root/.ollama 这样的命名数据卷可以完全避免此问题。
模型在重启间的缓存通过正确的数据卷挂载自动工作。你下载的模型会持久化在 Docker 数据卷中,因此停止和启动容器不会要求重新下载所有内容。但如果你不小心删除了数据卷或忘记了 -v 标志,你将丢失所有模型。
请记住以下快速修复方法:
- 容器无法启动?检查端口 11434 是否已被占用。
- 模型下载缓慢?验证你的互联网连接和 Docker 分配的资源。
- API 请求超时?为大型模型增加 Docker 的内存限制。
- 未检测到 GPU?验证 NVIDIA 驱动程序和 Container Toolkit 安装。
最常见的问题是忘记挂载数据卷,然后疑惑模型为何消失不见。
总结
Docker 让本地运行 LLM 变得简单、可移植且整洁。
你将获得隐私保护设计,你的数据永远不会离开你的机器。你将获得可预测的成本,没有意外的 API 账单或速率限制。你将完全控制你的 AI 技术栈,避免供应商锁定和对互联网的依赖。
设置只需几分钟。
拉取镜像,运行容器,下载模型,然后你就可以开始构建了。无论你是原型化 AI 助手、运行私有 RAG 流水线,还是仅仅实验不同的模型,这种组合都能在你的笔记本电脑上提供企业级的能力。
现在就去试试吧。选择一个适合你硬件的模型,启动 Ollama 容器,然后开始构建一些东西。入门门槛几乎不存在。
接下来,我们推荐你设置并在本地运行 DeepSeek R1 with Ollama。
Ollama Docker 常见问题解答
我需要强大的 GPU 才能通过 Docker Ollama 运行本地 LLM 吗?
虽然你可以在纯 CPU 系统上运行 Ollama,但性能会较慢——简单响应大约需要 30 秒以上。使用现代 GPU,相同的查询可在 5 秒内完成。NVIDIA GPU 表现最佳,但 Apple Silicon Mac 的性能也很好,并且可能更具性价比。真正的瓶颈通常是 RAM——小型模型至少需要 8GB,而大型 70B 参数模型则需要 64GB 或更多。
我可以将 Docker Ollama 与我现有的应用程序集成吗?
当然可以。Ollama 提供了一个在 http://localhost:11434 监听的标准 REST API,因此你可以使用简单的 HTTP 请求将其与任何应用程序集成。它与 Python、LangChain 和其他开发框架无缝协作。你可以构建聊天界面、代码补全工具或 RAG 流水线,它们可以与你的本地 LLM 通信,而无需将数据发送到外部服务。
本地模型需要多少磁盘空间?
模型存储需求因大小而异——7B 参数模型需要 4-8GB,13B 模型需要 8-16GB,70B 模型可能需要 40-80GB 的磁盘空间。多个模型版本和量化会迅速增加这些存储需求。如果本地存储成为问题,你可以将模型卸载到外部硬盘,Docker 数据卷也使得模型存储位置的管理变得容易。
如果我在运行 Docker 容器时忘记了数据卷映射会发生什么?
如果没有使用 -v ollama:/root/.ollama 进行正确的数据卷映射,当容器停止或重启时,你将丢失所有下载的模型。这意味着你每次都必须重新下载多 GB 的模型,这会浪费带宽和时间。务必使用命名数据卷来持久化你的模型,这是新用户最常犯的错误之一。
关于
关注我获取更多资讯

