最近我在网上看到了一篇来自 Google 的有趣论文,名为 Prompt Repetition Improves Non-Reasoning LLMs。标题基本上概括了整篇论文的内容,而且摘要也没多长!
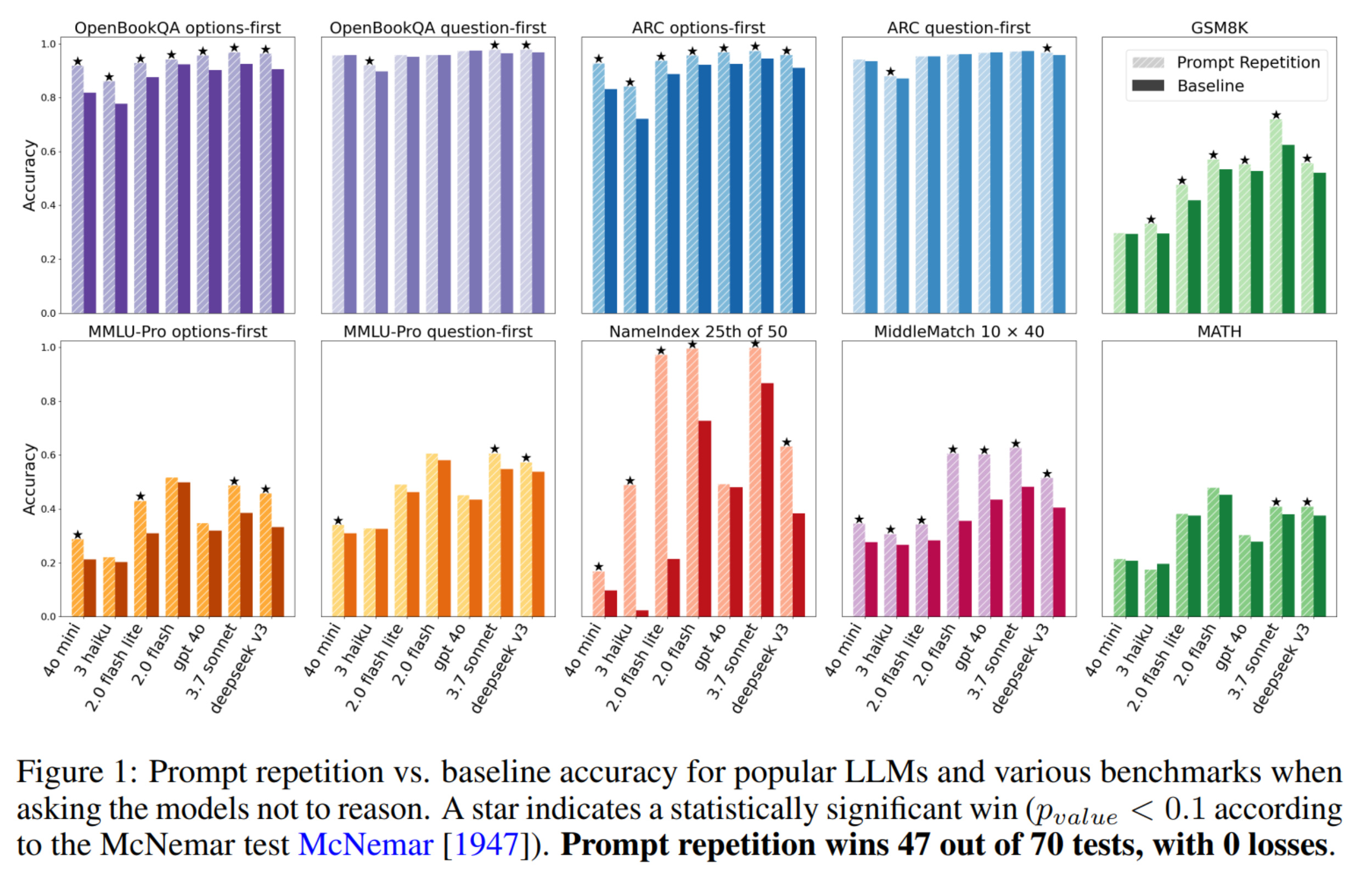
对我来说,有趣的是尽管人们在改进大语言模型(LLM)方面投入了大量工作,这种小技巧居然仍然有效。这向我证明了当前的 LLM 还有多大的改进空间。
我的观点是,想要获得这种性能提升,本来不应该需要重复提示词或者在推理上浪费 token。如果移除对提示词的因果限制,同样可以实现类似的提升。例如,在预训练期间,可以允许上下文的前半部分关注该范围内的任何 token,同时我们尝试预测后半部分。
实际上,这几乎就是 Katz 等人在他们的论文 Segment-Based Attention Masking for GPTs 中所做的事情。如果能在他们的模型中看看重复提示词是否依然能带来提升,会很有意思——不过从逻辑上讲,大家通常会认为这起不到什么作用。
关于
📬 关注我获取更多资讯

📢 公众号

💬 个人号