Sora 2 的 API 在九月底发布后,开发者社区就一直在期待它的正式上线。现在,这个时刻终于来了。我第一时间上手体验了一下,这篇文章就是把我踩过的坑和总结的经验分享给大家,希望能帮你快速掌握如何用 Python 来驾驭这个强大的 AI 视频生成工具。
准备工作:获取 API 密钥
要和 OpenAI API 打交道,第一步总是获取 API 密钥。直接去 OpenAI 官网的 API key 页面 创建一个新的密钥就行。
这个密钥是你账户的唯一凭证,得妥善保管。我习惯在项目根目录下创建一个 .env 文件,把密钥存进去,格式如下:
OPENAI_API_KEY=<你的API密钥粘贴在这里>
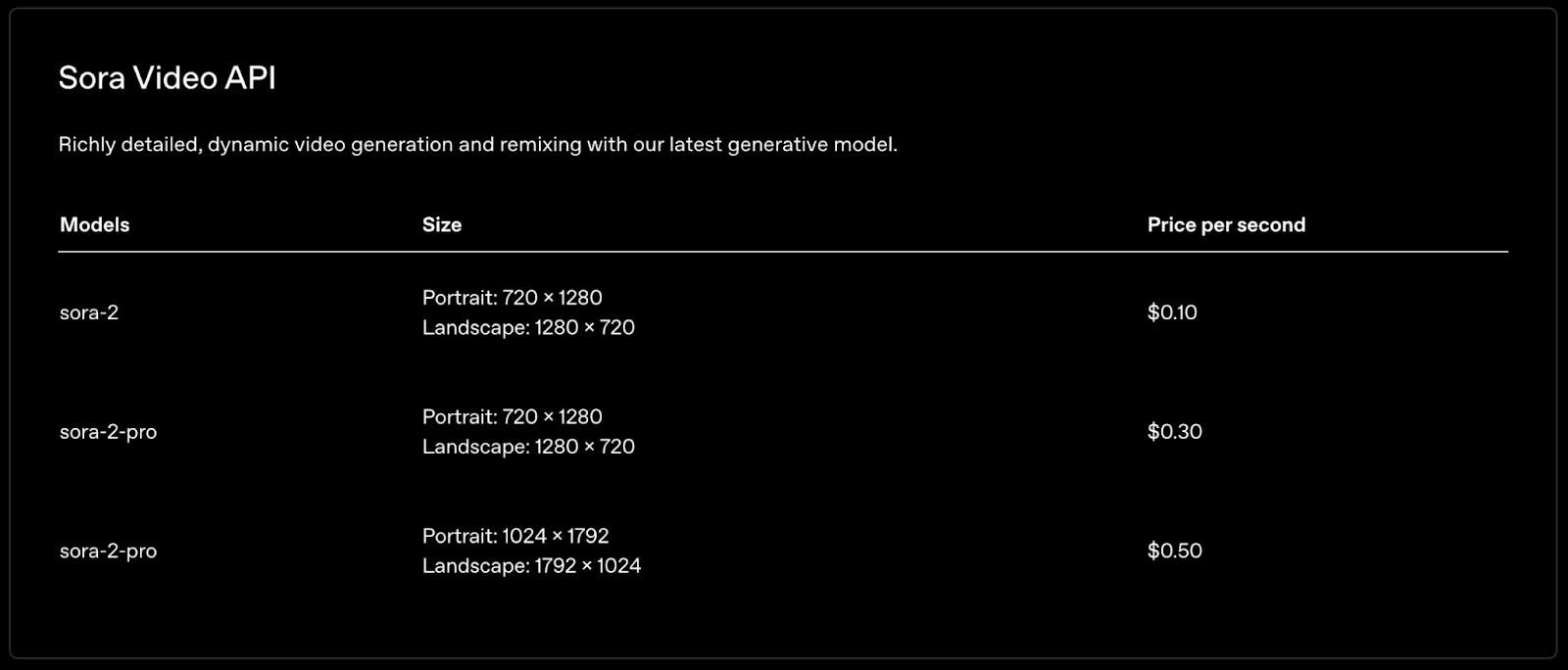
请注意,调用 Sora 2 API 是要花钱的。在开始之前,确保你的 OpenAI 账户里有足够的余额。下面是 Sora 2 每秒视频的定价,心里好有个数:
Python 生成 Sora 2 视频的基础流程
我们用官方的 openai Python 包来和 API 交互。因为 Sora 2 API 比较新,所以最好确保你的包是最新版本。
pip install --upgrade openai
接下来,我们创建一个 generate_video.py 脚本。
首先是导入必要的库。os 用来读取环境变量,dotenv 负责加载 .env 文件,openai 则是主角。
import os
from openai import OpenAI
from dotenv import load_dotenv
import time
# 加载环境变量
load_dotenv()
# 初始化 OpenAI 客户端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
一切就绪后,就可以通过 client.videos.create 方法发起一个视频生成请求了。
video_job = client.videos.create(
prompt="一只猫和一只狗在跳舞",
)
print(video_job.id)
这里有个关键点:这个调用不会立刻返回视频文件。视频生成是个耗时任务,所以 API 的设计是异步的。它会立即返回一个任务对象(我这里叫 video_job),里面包含了这次任务的唯一标识符 id。
这个 id 至关重要,我们后续需要用它来查询生成进度和下载最终的视频。
追踪视频生成进度
因为是异步的,我们就需要一个机制来不断查询任务状态。这可以通过 client.videos.retrieve() 函数实现。
job_id = "your_video_job_id" # 替换成上一步获取的 ID
job = client.videos.retrieve(job_id)
status = job.status
progress = job.progress
print(f"Status: {status}, {progress}%")
为了方便,我封装了一个轮询函数,它会每隔一段时间检查一次任务状态,直到视频生成完成或超时。
def wait_for_video_to_finish(video_id, poll_interval=5, timeout=600):
"""
轮询任务状态,直到视频就绪或超时。
"""
elapsed = 0
while elapsed < timeout:
job = client.videos.retrieve(video_id)
status = job.status
progress = job.progress
print(f"Status: {status}, {progress}%")
if status == "completed":
print("视频生成完成!")
return job
if status == "failed":
raise RuntimeError(f"视频生成失败: {job.error.message}")
time.sleep(poll_interval)
elapsed += poll_interval
raise RuntimeError("轮询超时")
这个函数有三个参数:video_id 是任务ID,poll_interval 是查询间隔(秒),timeout 是最长等待时间。
下载视频
当 wait_for_video_to_finish 函数成功返回后,就说明视频已经准备好了。这时我们就可以用 client.videos.download_content() 来下载它。
def download_video(video_id):
"""
根据视频 ID 下载视频并保存为 mp4 文件。
"""
response = client.videos.download_content(
video_id=video_id,
)
video_bytes = response.read()
with open(f"{video_id}.mp4", "wb") as f:
f.write(video_bytes)
print(f"视频已下载并保存为 {video_id}.mp4")
完整的生成工作流
把上面的步骤串起来,一个完整的视频生成工作流就成型了:
# 1. 发起生成请求
prompt = "一只猫和一只狗在跳舞"
video_job = client.videos.create(prompt=prompt)
video_id = video_job.id
print(f"已开始生成视频,ID 为 {video_id}")
# 2. 等待生成完成
wait_for_video_to_finish(video_id)
# 3. 下载视频
download_video(video_id)
进阶玩法:自定义视频参数
create 方法除了 prompt,还支持其他参数来精细控制输出结果,比如:
model: 使用的模型,默认为sora-2,还有更强的sora-2-pro。resolution: 视频分辨率,默认为720x1280。duration: 视频时长(秒),默认为 4 秒。
下面是不同模型支持的参数选项(加粗的是默认值):

为了方便在命令行里直接指定这些参数,我们可以用 Python 内置的 argparse 库来改造脚本,把它变成一个更实用的命令行工具。完整的代码可以在 GitHub 仓库 找到。
改造后,我们可以这样运行脚本:
python generate_video_pipeline.py \
--prompt "一个狗狗家庭在开车" \
--model sora-2-pro \
--size 1280x720 \
--seconds 8
Prompt 的艺术:如何写出好提示词
OpenAI 官方提供了一份相当详尽的 Sora 2 Prompt 指南。我个人觉的,核心思想可以总结为以下几点:
- 具体且视觉化:用“霓虹灯下的潮湿柏油路”代替“一条美丽的街道”。
- 像写剧本一样思考:描述镜头(广角、特写)、光线、主体,并为每个镜头设计一个清晰的动作。
- 保持动作简洁:一个主体动作 + 一个镜头移动,效果最好。
- 利用图像参考:如果想固定风格或构图,提供一张参考图是最好的方式。
官方给出的模板也很有参考价值:
[用自然语言描述场景。描述角色、服装、布景、天气等细节。描述得越详细,生成的视频就越接近你的设想。]
摄影:
镜头: [取景和角度,例如:广角全景镜头,平视]
氛围: [整体基调,例如:电影感的紧张,俏皮悬疑,奢华的期待感]
动作:
- [动作1: 一个清晰、具体的节奏或手势]
- [动作2: 片段内的另一个独特节奏]
- [动作3: 另一个动作或对话]
对话:
[如果镜头中有对话,在此处添加简短自然的台词,或作为动作列表的一部分。保持简短以匹配片段长度。]
在命令行里输入这么长的 prompt 太麻烦了。所以,我给脚本加了个小功能:如果 prompt 参数以 .txt 结尾,就直接读取文件内容作为 prompt。
# ... 省略 argparse 设置代码
args = parser.parse_args()
prompt = args.prompt
if prompt.endswith(".txt"):
with open(prompt, "rt") as f:
prompt = f.read()
# 后续调用生成函数...
图生视频:用图像参考提升一致性
要根据一张图片生成视频,我们可以使用 input_reference 参数。这对于保持角色或场景的一致性非常有用。
代码实现很简单,就是读取图片文件并传给 API:
with open("reference_image.jpeg", "rb") as f:
video_job = client.videos.create(
prompt="两个人背对背走开",
input_reference=f
)
# ... 后续流程不变
这里有一个不大不小的坑:参考图片的尺寸必须和你要生成的视频分辨率完全一致。
如果尺寸不匹配,API 会报错。为了解决这个问题,我们可以用 Pillow 库在上传前自动调整图片尺寸。这使得我们必需要先安装它:
pip install Pillow
然后在代码里加入预处理逻辑,这样就不用手动去改图了,非常方便。
踩坑与吐槽
在体验过程中,我也遇到了一些问题,这里也一并分享出来。
视频参考功能暂未开放
API 虽然支持 input_reference 传入视频,但我每次尝试时都会收到一个错误:
Video inpaint is not available for your organization
看样子,视频到视频的编辑功能(Video Inpainting)目前还不是对所有开发者开放,我们只能再等等。
过于严格的审核系统
这一点我必须得吐槽一下。我经常遇到请求被审核系统拦截的情况,返回的错误信息也很模糊:
RuntimeError: Video generation failed: Your request was blocked by our moderation system.
我能理解这类工具需要强大的审核机制,以防被滥用。但在我的测试中,很多完全正常的 prompt 和我自己的照片都被拦截了,而且错误信息里完全没说具体是哪里违规了。这导致我最初的一些创意想法根本无法实现,体验不是很好。希望 OpenAI 后续能优化审核算法的精度。
总结
Sora 2 的 API 为 AI 视频创作打开了一扇新的大门。通过这篇指南,你应该已经掌握了用 Python 调用它来生成视频的完整流程,包括一些高级技巧和实用窍门。
虽然目前 API 还处在早期阶段,有些功能(比如视频编辑)尚未完全开放,审核系统也有些过于敏感,但它的潜力是巨大的。希望这篇文章能帮你少走一些弯路,更快地将你的创意变为现实。
关于
关注我获取更多资讯

