LangChain 作为一个开源框架,旨在简化大模型应用的开发。最近发布的 1.0 版本标志着它从一个快速迭代的实验性工具,开始走向一个更稳定、适合生产环境的核心框架。API 变得更简洁,边界更清晰,消息处理也更加标准化。
在这篇文章中,我们将动手构建一个基于 Streamlit 的“自动化会议纪要助手”。这个小工具能接收原始的会议笔记,生成简洁的摘要和待办事项(Action Items),并在你确认后,自动将纪要追加到指定的 Google Doc 中。通过这个过程,你将直观地体验到 LangChain v1 中新的 create_agent 流程、标准化的内容块(Content Blocks)以及更精简的命名空间。
LangChain v1 带来了什么变化?
如果你用过 LangChain 的早期版本(v0.x),可能会感觉它功能强大但有些杂乱。v1 版本对此做了不少改进,核心思路是提供一个更小、更稳定的 API 接口,让构建 Agent 的过程更清晰。
几个关键的改进点:
create_agent成为标准:取代了过去多种构建 Agent 的方式,提供了一个统一、清晰的入口。- 标准化的内容块 (
content_blocks):无论你用的是 OpenAI、Anthropic 还是其他模型,消息格式都保持一致,这让跨模型开发和调试变得容易多了。 - 原生结构化输出:这是我个人最喜欢的一点。你可以直接要求模型返回 Pydantic schema 那样的结构化数据,告别了繁琐、易错的正则表达式解析。
- 中间件 (Middleware):允许在 Agent 的执行循环中加入钩子,比如可以在执行危险操作前加入人工审批环节,或者在上下文过长时自动进行总结。
- 精简的命名空间:核心的
langchain包现在专注于 Agent 构建的基础模块。很多旧的、非核心的功能被移到了langchain-classic中,这让代码库更容易维护和升级。
简单来说,v1 版本降低了开发者的心智负担。你不再需要为不同模型的怪癖写一堆兼容代码,而是可以用一套统一的思路来构建应用。
实战:构建自动化会议纪要助手
接下来,我们一步步实现这个工具。它会接收原始会议笔记和一些元数据(比如标题、日期、参与人),生成一份结构化的 RecapDoc 文档,包含摘要、决议和待办事项。最后,只需一次点击,这份纪要就会被格式化并追加到你的 Google Doc 里。
Step 1: 环境准备
首先,我们需要安装一些必要的库,用于构建界面、调用 LLM、进行数据验证以及操作 Google Docs。
pip install -U streamlit langchain langchain-openai pydantic python-dotenv
pip install -U google-api-python-client google-auth google-auth-oauthlib google-auth-httplib2
同时,你需要设置你的 OpenAI API 密钥。建议使用环境变量:
export OPENAI_API_KEY='your-openai-api-key'
这些库的作用分别是:
streamlit: 用来快速搭建一个简单的 Web UI。langchain&langchain-openai: 提供 v1 的核心功能和 OpenAI 模型的接口。pydantic: 定义我们期望模型返回的数据结构,也就是所谓的“结构化输出”。python-dotenv: 在开发时方便地从.env文件加载环境变量。google-*系列库: 用于 Google Docs API 的认证和调用。
Step 2: 配置 Google Docs API
为了让程序能把纪要写入 Google Docs,我们需要进行 OAuth 认证。这个过程稍微有点繁琐,但只需要做一次。
2.1 获取 credentials.json
这个文件是你的应用访问 Google API 的钥匙。
- 创建或选择一个 Google Cloud 项目: 访问 Google Cloud Console 并创建一个新项目。
- 启用 Google Docs API: 在"API 和服务" -> “库"中,搜索 “Google Docs API” 并启用它。
- 配置 OAuth 同意屏幕:
- 在"API 和服务” -> “OAuth 同意屏幕”,选择"外部用户"。
- 填写应用的基本信息。在"测试用户"部分,添加你将用来登录的 Google 账户。开发阶段,保持"测试"模式即可。
- 创建 OAuth 客户端 ID:
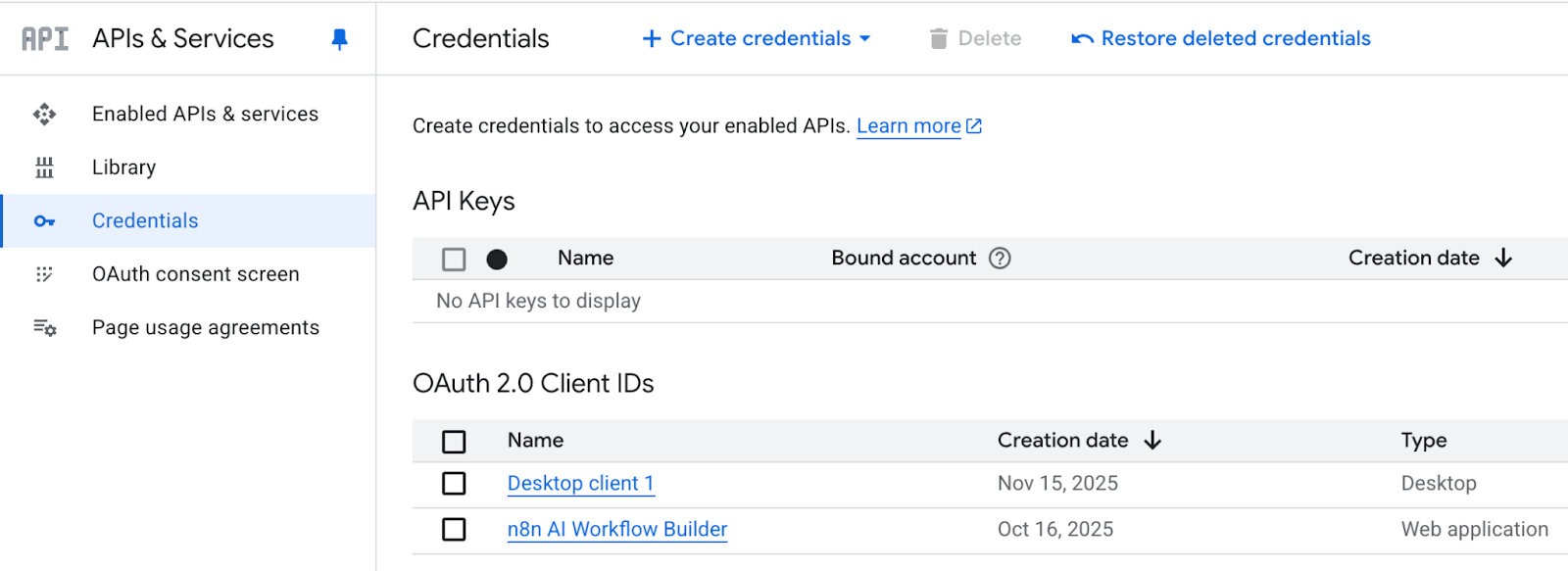
- 在"API 和服务" -> “凭据"页面,点击 “+ 创建凭据”,选择 “OAuth 客户端 ID”。
- 应用类型选择"桌面应用”。
- 创建成功后,下载生成的 JSON 文件,并将其重命名为
credentials.json,放在你的项目根目录下。
2.2 获取 Google Doc ID
你需要告诉程序要把纪要写到哪个文档里。
- 打开你的目标 Google Doc,查看浏览器地址栏。
- URL 的格式通常是
https://docs.google.com/document/d/<THIS_IS_THE_ID>/edit。 - 复制中间那段长长的字符串,这就是
DOCUMENT_ID。
2.3 关于 token.json
第一次运行程序并尝试写入 Google Doc 时,它会自动打开一个浏览器窗口,要求你授权。授权成功后,会在本地生成一个 token.json 文件,用于后续的免密访问。如果需要更换账户或重新授权,删掉这个文件再来一次就行。
Step 3: 引入必要的模块
在写逻辑之前,我们先导入所有需要的库。
import os
import io
import json
from datetime import date
from typing import List, Optional
import streamlit as st
from pydantic import BaseModel, Field
from dotenv import load_dotenv
# LangChain v1 的核心组件
from langchain.agents import create_agent
from langchain.messages import SystemMessage, HumanMessage
from langchain.chat_models import init_chat_model
# Google Docs API 相关
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
Step 4: 定义结构化输出
这是确保 LLM 输出可靠的关键一步。我们用 Pydantic 定义一个数据模型,告诉 LLM 我们需要什么格式的数据。这个模型定义的好坏,直接决定了后面处理数据的难易程度。
class ActionItem(BaseModel):
owner: str = Field(..., description="负责人")
task: str = Field(..., description="简短、具体的任务描述")
due_date: str = Field(..., description="ISO 格式日期 (YYYY-MM-DD) 或自然语言描述,如 '下周五'")
class RecapDoc(BaseModel):
title: str
date: str
attendees: List[str]
summary: str
decisions: List[str]
action_items: List[ActionItem]
通过 LangChain v1 的 with_structured_output(RecapDoc),我们可以直接让模型返回一个符合这个结构的 Python 对象,非常方便。
Step 5: 设计系统提示(System Prompt)
系统提示为我们的 AI 助手设定了基本规则和行为模式。
SYSTEM_PROMPT = """你是一个严谨的助手,负责生成简洁、信息含量高的会议纪要。
请返回一个结构化的 RecapDoc,包含:
- title, date, attendees
- 简要总结 (3–6句话)
- 明确的决议 (项目符号格式)
- action_items (每项包含 owner, task, due_date)
规则:
- 只包含笔记或用户输入中明确支持的信息。
- 待办事项要具体,有明确的负责人和截止日期。
- 如果某项信息未知,请明确写 "未知",不要杜撰。
"""
Step 6: Google OAuth 辅助函数
这个函数封装了与 Google API 认证的所有逻辑,包括首次授权、刷新 token 等。
SCOPES = ["https://www.googleapis.com/auth/documents"]
def get_google_docs_service(
credentials_path: Optional[str],
token_path: str = "token.json",
use_secrets: bool = False
):
creds = None
if use_secrets:
# (此部分为 Streamlit Cloud 部署时使用,本地开发可忽略)
try:
if "google_credentials_json" in st.secrets:
with open("credentials_temp.json", "w") as f:
f.write(st.secrets["google_credentials_json"])
credentials_path = "credentials_temp.json"
except Exception:
pass
if os.path.exists(token_path):
creds = Credentials.from_authorized_user_file(token_path, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception:
pass # 如果刷新失败,则重新走授权流程
if not creds or not creds.valid:
if not credentials_path or not os.path.exists(credentials_path):
raise RuntimeError(
"缺少 Google OAuth 凭据。请提供 'credentials.json' 文件。"
)
flow = InstalledAppFlow.from_client_secrets_file(credentials_path, SCOPES)
creds = flow.run_local_server(port=0)
with open(token_path, "w") as token:
token.write(creds.to_json())
return build("docs", "v1", credentials=creds)
Step 7: Markdown 渲染器和文档追加工具
我们需要两个辅助函数:一个将 RecapDoc 对象转换成 Markdown 格式的文本,另一个负责将文本追加到 Google Doc 的末尾。
def recap_to_markdown(recap: RecapDoc) -> str:
lines = [
f"# {recap.title} — {recap.date}",
"",
f"**参与人:** {', '.join(recap.attendees) if recap.attendees else '未知'}",
"",
"## 摘要",
recap.summary.strip(),
"",
"## 决议",
]
if recap.decisions:
for d in recap.decisions:
lines.append(f"- {d}")
else:
lines.append("- 无记录")
lines.append("")
lines.append("## 待办事项")
if recap.action_items:
for ai in recap.action_items:
lines.append(f"- **{ai.owner}** — {ai.task} _(截止日期: {ai.due_date})_")
else:
lines.append("- 无记录")
return "\n".join(lines)
def append_plaintext_to_doc(docs_service, document_id: str, text: str):
doc = docs_service.documents().get(documentId=document_id).execute()
# 找到文档末尾的索引
end_index = doc.get("body", {}).get("content", [])[-1]["endIndex"]
requests = [
{
"insertText": {
"location": {"index": end_index - 1},
"text": text + "\n"
}
}
]
return docs_service.documents().batchUpdate(
documentId=document_id,
body={"requests": requests}
).execute()
Step 8: 核心的纪要生成器
这个函数是应用的大脑。它接收用户输入,调用 LLM,并返回一个我们定义好的 RecapDoc 对象。
def generate_recap(model_name: str, notes: str, title: str, date_str: str, attendees_csv: str) -> RecapDoc:
model = init_chat_model(model=model_name)
# 关键一步:绑定结构化输出
structured_llm = model.with_structured_output(RecapDoc)
attendees_list = [a.strip() for a in attendees_csv.split(",")] if attendees_csv.strip() else []
user_prompt = (
"你将收到会议笔记和一些元数据。\n\n"
f"标题: {title or '未知'}\n"
f"日期: {date_str or '未知'}\n"
f"参与人: {attendees_list if attendees_list else '未知'}\n\n"
"笔记:\n"
f"{notes.strip()}\n"
)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=user_prompt)
]
try:
recap = structured_llm.invoke(messages)
except Exception as e:
st.error(f"生成纪要时出错: {e}")
# 如果出错,返回一个空的 RecapDoc 以免 UI 崩溃
recap = RecapDoc(
title=title or "未知",
date=date_str or "未知",
attendees=attendees_list,
summary=f"生成摘要时出错: {str(e)}",
decisions=[],
action_items=[]
)
return recap
Step 9: Streamlit UI 界面
最后,我们用 Streamlit 把所有部分串联起来,构建一个简单易用的界面。
def main():
load_dotenv()
st.set_page_config(page_title="会议纪要助手 (LangChain v1)", layout="wide")
st.markdown("<h1 style='text-align: center;'>会议纪要助手 (LangChain v1)</h1>", unsafe_allow_html=True)
# --- 配置 ---
model_name = os.getenv("LC_MODEL", "gpt-4o-mini")
# 把这里换成你自己的 Google Doc ID
document_id = "YOUR_GOOGLE_DOC_ID_HERE"
credentials_path = os.getenv("GOOGLE_CREDENTIALS_JSON", "credentials.json")
st.subheader("在这里贴入你的会议笔记")
colL, colR = st.columns([2, 1])
with colL:
notes = st.text_area("笔记内容", height=300, placeholder="把你的原始笔记粘贴到这里...")
with colR:
title = st.text_input("会议标题")
date_str = st.date_input("会议日期", value=date.today())
attendees_csv = st.text_input("参与人 (用逗号分隔)")
# --- 状态管理 ---
if "recap" not in st.session_state:
st.session_state.recap = None
if "markdown_text" not in st.session_state:
st.session_state.markdown_text = None
# --- 按钮与逻辑 ---
col1, col2, col3 = st.columns([1, 1, 2])
with col1:
generate_btn = st.button("生成纪要")
with col2:
append_btn = st.button("追加到 Google Doc", disabled=(st.session_state.recap is None))
if generate_btn:
if not notes.strip():
st.error("请输入一些笔记内容。")
st.stop()
with st.spinner("正在生成纪要..."):
recap = generate_recap(
model_name=model_name,
notes=notes,
title=title,
date_str=str(date_str),
attendees_csv=attendees_csv,
)
st.session_state.recap = recap
st.session_state.markdown_text = recap_to_markdown(recap)
st.rerun()
if append_btn and st.session_state.recap is not None:
with st.spinner("正在写入 Google Doc..."):
try:
service = get_google_docs_service(credentials_path=credentials_path)
final_text = (
f"\n\n===== {st.session_state.recap.title} — {st.session_state.recap.date} =====\n\n"
+ st.session_state.markdown_text
)
append_plaintext_to_doc(service, document_id, final_text)
st.success("纪要已成功追加到 Google Doc!")
except Exception as e:
st.exception(e)
# --- 预览区域 ---
if st.session_state.recap is not None:
st.markdown("---")
st.markdown("### 纪要预览")
st.markdown(st.session_state.markdown_text)
if __name__ == "__main__":
main()
将以上代码保存为 app.py,然后在终端运行:
streamlit run app.py
你现在应该能在浏览器中看到你的应用了!

从 v0 迁移的一些思考
如果你正在使用旧版 LangChain,升级到 v1 还是需要一些工作的。create_agent 取代了旧的 Agent 模式,很多类的导入路径也变了。我的建议是,把这次升级看作一次重构的机会,而不是简单的替换。
- 拥抱结构化输出:尽可能用 Pydantic 模型来定义你期望的输出。这会让你的代码更健壮,也更容易测试。
- 清理依赖:检查你的代码,看看是否还在使用那些被移到
langchain-classic的旧组件。如果可能,尽量用 v1 的新组件来替代它们。 - 小步快跑:先从一个小功能或一个独立的 Agent 开始迁移。在不进行充分测试的情况下,不要一次性升级整个项目。
总结
LangChain v1 感觉更像一个为工程师打造的生产力框架,而不仅仅是一个 AI 研究工具。通过这个会议纪要助手的例子,我们可以看到,create_agent、结构化输出和标准化的消息格式等特性,确实让构建可靠、可维护的 AI 应用变得更加直接。这个工具的的用处在于,它不仅仅是一个 demo,更是一个可以实际应用到日常工作流中的实用模板。
关于
关注我获取更多资讯

