最近 AI 圈真是热闹,DeepSeek 刚掀起波澜,阿里的 Qwen(通义千问)紧接着就发布了一系列表现惊人的模型。它们不只是单纯的聊天机器人,而是针对特定任务、能产生实际价值的工具。
今天,我们就来深入了解一下其中的 Qwen2.5-VL,一个在视觉能力上据说已经超越所有闭源模型的视觉语言模型。本文会带你一步步在自己的电脑上把它跑起来,并体验一下它的旗舰版本。
Qwen2.5-VL 简介
Qwen2.5-VL 是 Qwen 家族最新的旗舰级视觉语言模型,相比前代 Qwen2-VL 有了巨大的飞跃。它不仅能识别常见的花鸟鱼虫,还能深入分析图像中的复杂文本、图表、图标、图形和布局。
这个模型的能力远不止于此。它支持处理超过一小时的视频,能在其中定位特定事件,甚至可以生成边界框来精确定位的物体。对于需要结构化数据的场景,比如处理发票、表单和表格等扫描文档,它也能输出稳定的 JSON 格式坐标和属性,这对金融和商业领域来说相当实用。
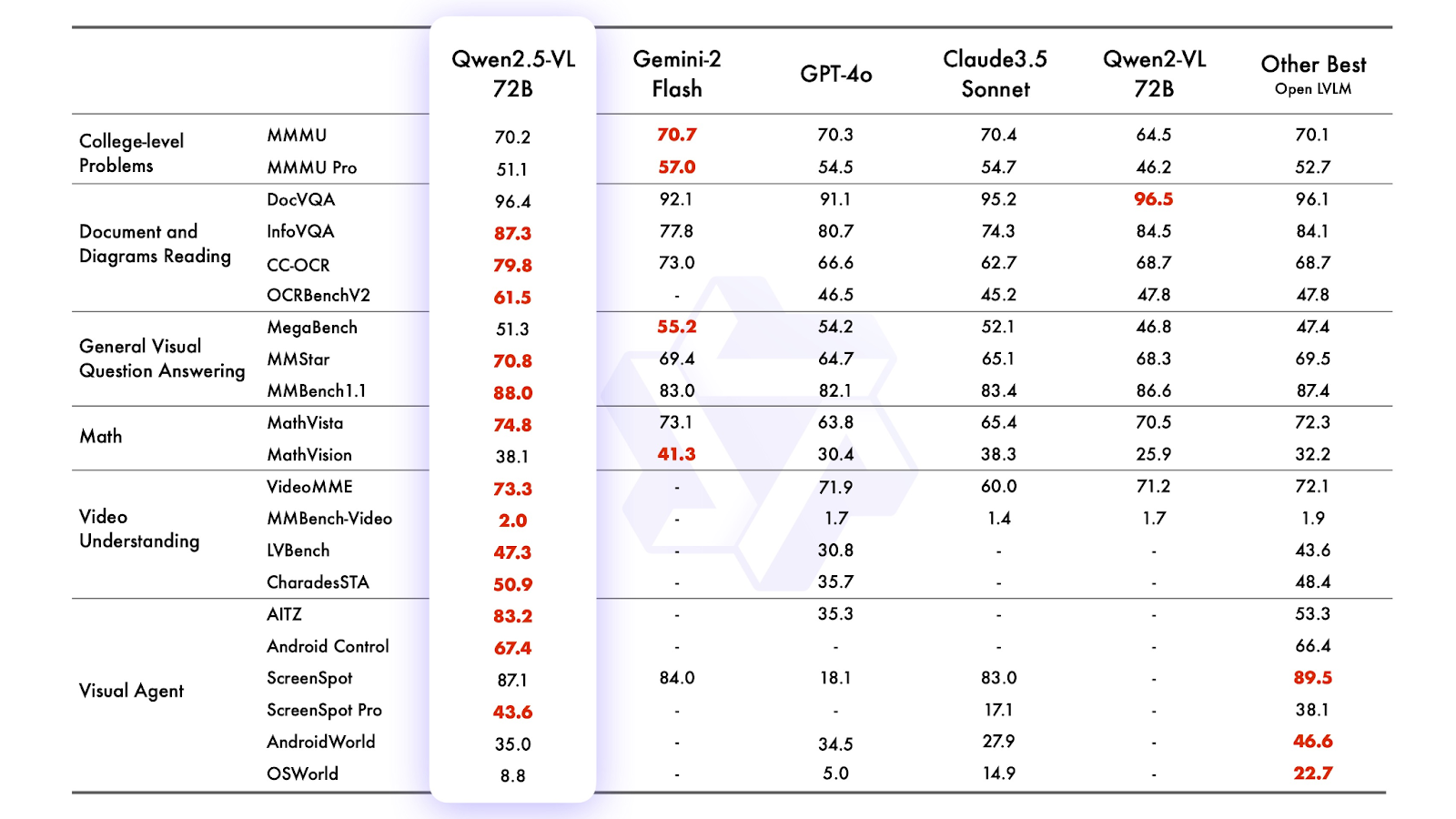
从官方给出的基准测试看,旗舰型号 Qwen2.5-VL-72B-Instruct 在多个维度上都超过了像 Gemini 2 Flash、GPT-4o 和 Claude 3.5 Sonnet 这样的顶尖模型,其实力可见一斑。
在带 GPU 的笔记本上本地运行 Qwen2.5-VL
好了,理论说得差不多了,我们来动手实践。下面介绍几种在本地运行 Qwen2.5-VL 得方法,这些方案都来自官方的 GitHub 仓库。我们要做的就是配置好环境,解决一些常见的小问题,然后把 Web 应用跑起来。
方法一:直接运行 Web 应用
这是最直接的方式,适合想快速上手的朋友。
1. 克隆代码库
首先,打开你的终端,克隆官方的 GitHub 仓库并进入项目目录:
git clone https://github.com/QwenLM/Qwen2.5-VL
cd Qwen2.5-VL
2. 安装依赖
使用 pip 安装 Web Demo 所需的依赖包:
pip install -r requirements_web_demo.txt
3. 【关键】更新 PyTorch
为了确保 GPU 兼容性,强烈建议安装最新支持 CUDA 的 PyTorch、TorchVision 和 TorchAudio。即使你已经安装了 PyTorch,也最好执行一遍更新,这能避免很多奇怪的运行时错误。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
4. 更新 Gradio
旧版本的 Gradio 可能会导致连接或 UI 相关的问题。我们把它也更新到最新版:
pip install -U gradio gradio_client
5. 启动 Web Demo
现在,一切就绪。我们来运行 Web Demo。这里推荐使用较小的 3B 模型 (Qwen/Qwen2.5-VL-3B-Instruct),这个版本对显存要求不高,在 8GB VRAM 的笔记本上也能跑得动。虽然 7B 模型也可能可以运行,但响应速度会慢很多。
python web_demo_mm.py --checkpoint-path "Qwen/Qwen2.5-VL-3B-Instruct"
终端会先下载模型文件,然后加载处理器和模型。成功后,你会看到一个本地 URL,比如 http://127.0.0.1:7860。
在浏览器中打开这个地址,就能看到 Gradio 的界面了。
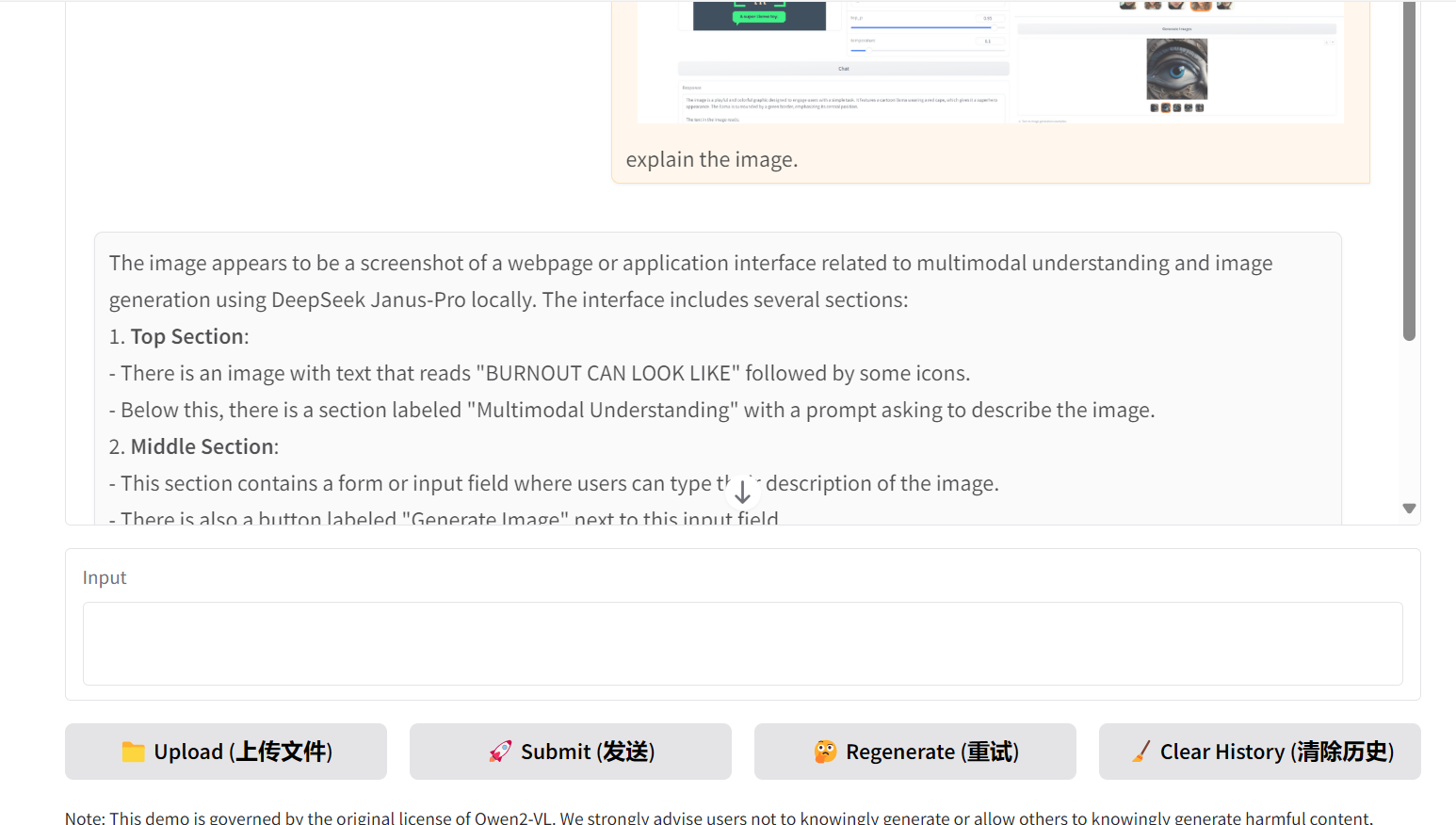
你可以上传一张包含文字和多个图表的复杂图片,让模型解释它。即便只是 3B 的小模型,它也能识别出图像中相当复杂的细节,效果很不错。
当然,不上传图片也可以直接和它对话,这时它就和一个普通的大语言模型一样工作。

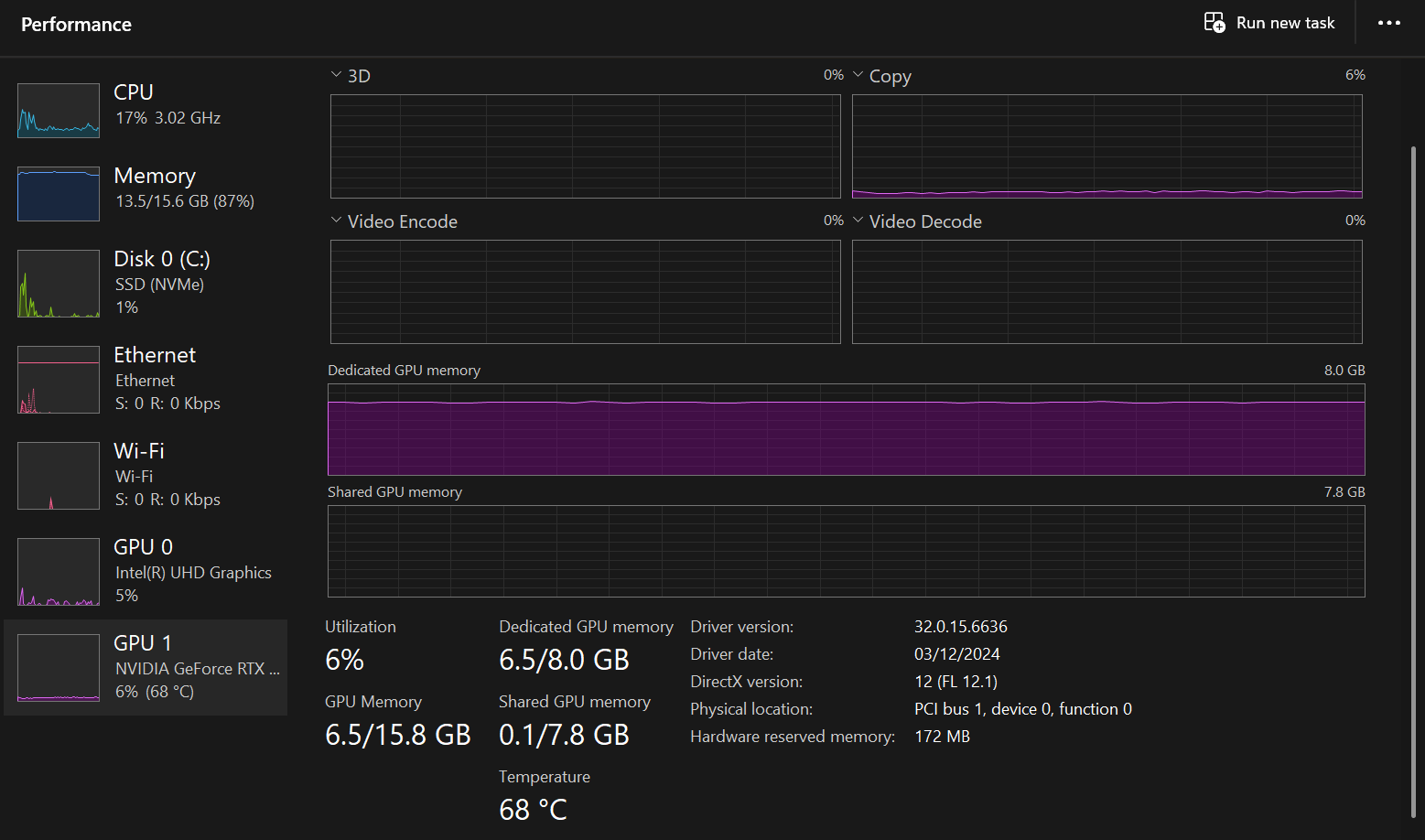
这时打开任务管理器看看性能,你会发现 GPU 利用率可能只有 6% 左右,说明运行非常流畅。
方法二:尝试实验性的视频流应用
代码库里还有一个实验性的流式视频聊天 Demo,在 web_demo_streaming 目录下。它能让你通过摄像头和模型实时互动。
进入该目录,用同样的方式启动应用:
cd web_demo_streaming/
python app.py --checkpoint-path "Qwen/Qwen2.5-VL-3B-Instruct"
如果你的 GPU 性能足够好,这个应用会跑得很顺畅。授权浏览器访问你的摄像头,就可以开始提问了。
方法三:使用 Docker Desktop(最稳定)
要说最省心、最稳定的本地运行方式,还得是 Docker。Qwen 团队已经提供了预构建的 Docker 镜像,里面配置好了所有环境。
- 安装 Docker Desktop:如果还没安装,去 Docker 官网 下载并安装。
- 运行 Docker 容器:使用官方提供的
qwenllm/qwenvl镜像。下面这条命令会下载镜像、安装驱动并启动一个交互式终端。
docker run --gpus all --ipc=host --network=host --rm --name qwen2 -it qwenllm/qwenvl:2-cu121 bash
进入容器后,你可以按照方法一的步骤来启动 web_demo_mm.py。
在线体验旗舰版 Qwen2.5-VL
如果你的本地硬件有限,又想体验最强版本 Qwen2.5-VL 72B Instruct 的威力,可以直接访问通义千问的在线聊天网站。
创建一个账户,在模型选择列表中找到对应的视觉模型,然后就可以像使用 ChatGPT 一样上传图片并和它对话了。
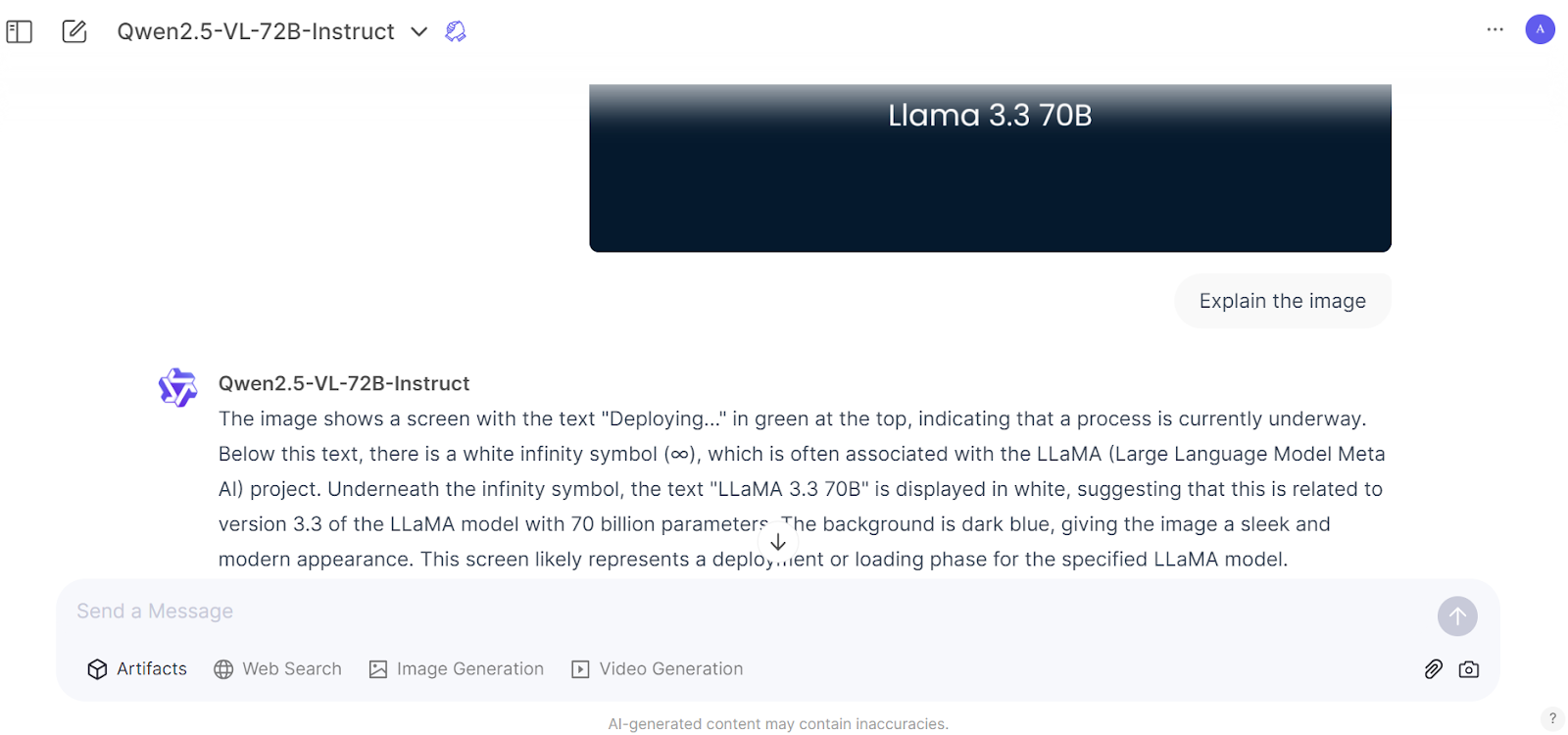
旗舰版的响应速度很快,分析也极其精准,值得花点时间去感受一下顶级 AI 模型的水平。
结语
Qwen2.5-VL 的出现,再次证明了顶尖 AI 模型的创新并非某个国家或地区的专利。这个模型不仅准确度高,而且提供了便捷的本地部署方式,让开发者可以基于它来打造自己的 AI 工具,实现各种自动化任务。
通过这篇教程,我们了解了 Qwen2.5-VL 的强大能力,并动手在本地成功运行了它。对于开发者和技术爱好者来说,能把这种级别的模型放在自己的机器上随意“折腾”,是一件非常有价值也很有趣的事。
关于
关注我获取更多资讯

