传统 RAG 系统通过语义相似度来检索文档块,这对于简单明了的问题确实管用。可一旦查询需要综合多份文档中的分散信息,或是涉及对关联概念进行推理,那向量搜索就显得力不从心了。系统往往只能检索到零碎的片段,却无法理解这些片段之间是怎样关联的。
GraphRAG 的高明之处在于它不把文档看作孤立的块。它构建了一个知识图谱,捕捉了实体及其关系。这种结构允许系统遍历连接,从而回答那些需要从多个来源整合信息的问题。可以说,这是解决基本检索局限性的高级 RAG 技术之一。
GraphRAG 是什么?
GraphRAG 是一种检索增强生成技术,它将文档表示为知识图谱,而非简单的向量嵌入。它不再是将文本打散成独立搜索的块,而是从中提取实体(比如人、组织、概念、事件)以及它们之间的关系,并将这些信息组织成相互连接的图结构。
GraphRAG 系统接下来会对这些实体应用社区发现算法,来识别相关实体的聚类,并针对这些聚类在不同层级生成摘要。当收到查询时,GraphRAG 可以选择遍历特定的实体“邻域”来回答目标明确的问题,或者对社区摘要进行“Map-Reduce”操作,以实现语料库层面的信息综合。
接下来,我们深入剖析一下其内在机制。这能帮助我们更好的了解基于图的检索为何出现,以及它弥补了哪些不足。
传统 RAG 的局限
传统 RAG 的核心问题并非检索或生成本身,而是信息的表示方式。文档被拆分成块,每个块都成了嵌入空间中孤立的向量。原始文档中存在的结构——标题、叙事流程、哪个段落引用了什么——都被抹平了。
这对于需要组合信息的问题造成了困扰。如果你问“这些文档的主要主题是什么?”,向量搜索会返回包含“主题”或相关词汇的文本块。但找到相关的片段,和理解整个语料库中的模式是两码事。系统无法大规模地整合信息,因为它只看到了零星的片段,从未见到全貌。
多跳推理也遇到了类似的瓶颈。假设某个问题的答案依赖于概念 A 与概念 B、概念 B 与概念 C 的连接。传统 RAG 会根据与查询的相似性独立检索每个块。如果 B 与问题不那么相关,它可能根本就不会被检索到,从而中断了整个推理链条。系统找到了终点,却错过了它们之间的路径。
我们还需要考虑检索与上下文的失配问题。你可以检索到二十个高度相关的文本块,但把它们一股脑儿地塞进提示词里,并不能保证 LLM 会好好利用它们。“迷失在中间(lost in the middle)”的论文显示,LLM 倾向于关注上下文窗口开头和结尾的信息,常常忽略夹在中间的内容。所以,更多地检索,并不意味着就能自动得到更好的答案。
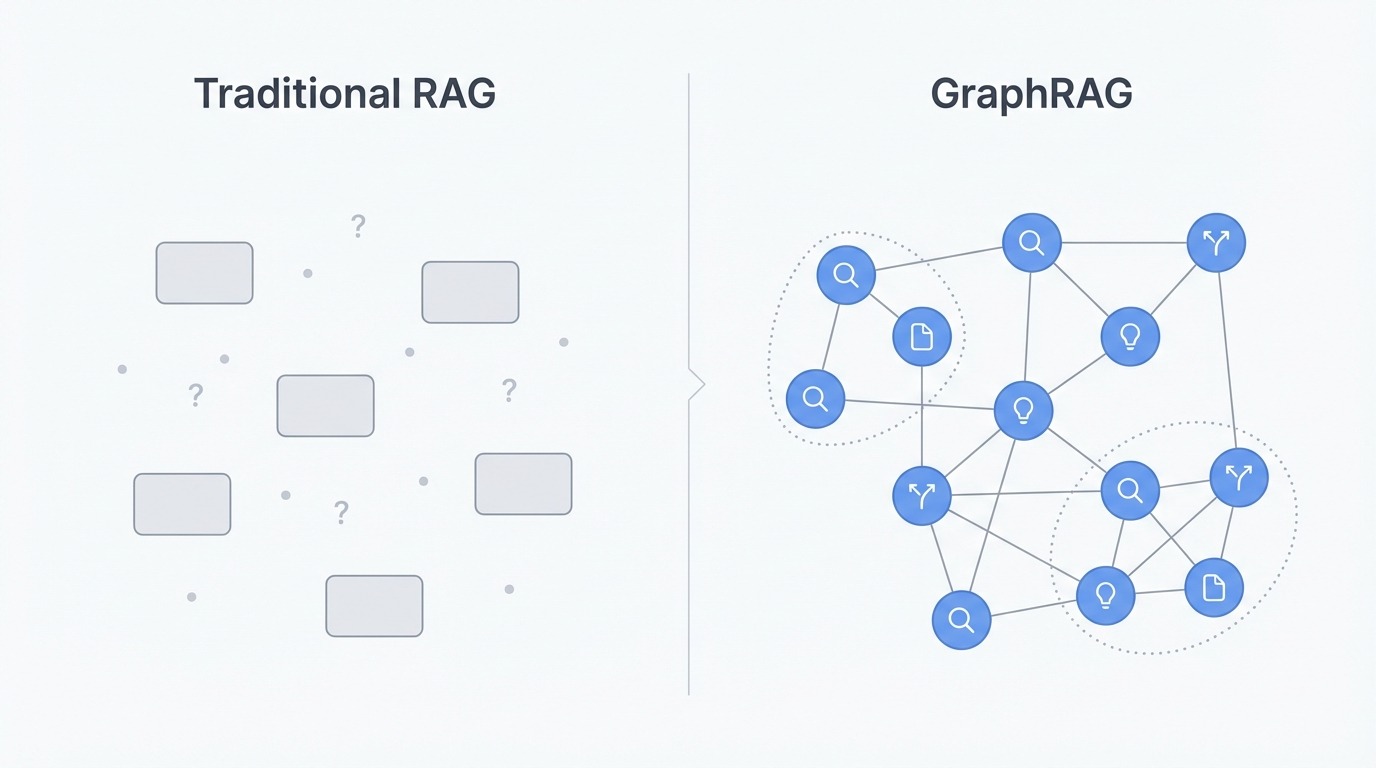 传统 RAG 与 GraphRAG 对比。图片来源:作者
传统 RAG 与 GraphRAG 对比。图片来源:作者
GraphRAG 如何解决 RAG 的局限
GraphRAG 通过彻底改变表示方式来克服这些局限。它不是使用文本块,而是构建知识图谱,其中实体成为节点,关系成为边。人物、组织、地点、概念和事件,以及它们之间的连接方式,都从原始文档中被提取出来。这样就保留了分块方法会丢失的结构。
构建好图谱后,系统会应用社区发现算法(通常是 Leiden 算法)将相关实体聚类成组。这些聚类会形成多个层级,有些紧密而具体,有些则宽泛而主题化。这些分组是根据数据中的实际连接而非文档边界或块大小形成的。
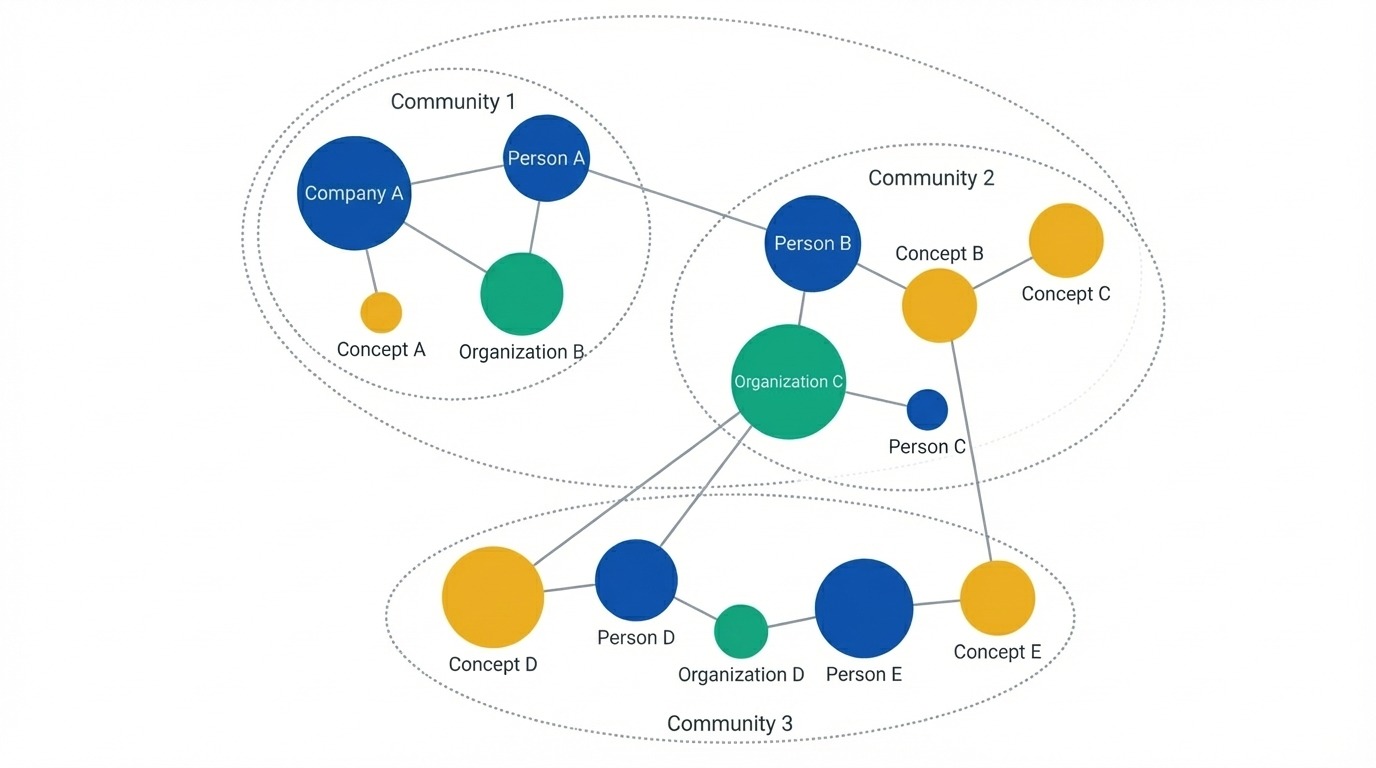 显示实体为节点的知识图谱。图片来源:作者
显示实体为节点的知识图谱。图片来源:作者
对于全局性问题,GraphRAG 会在任何用户查询到来之前,预先为每个社区生成摘要。当有人问“主要主题是什么?”时,系统不会去搜索匹配的文本。相反,它会执行 Map-Reduce 操作:每个社区摘要根据其图谱片段生成部分答案,然后所有部分答案会被组合成最终响应。这使得 GraphRAG 能够对整个语料库进行推理,而无需检索成千上万的文本块。
对于多跳问题,图遍历取代了相似度搜索。系统可以沿着边从一个实体走到另一个实体,追踪向量搜索会错过的概念链。如果 A 连接到 B,B 连接到 C,图谱知道这条路径的存在并能沿着它行进。
何时选用 GraphRAG
GraphRAG 在你的问题需要语料库级的理解时会发挥作用。如果用户经常询问大量文档集合中的主题、模式或摘要,那么基于图的检索将优于基于分块的方法。对于实体关系丰富的领域也是如此,例如公司组织结构图、研究引用网络或法律案例历史,其中追踪连接至关重要。
对于简单的事实查找(“X 的电话号码是多少?”)或小规模文档集,传统 RAG 表现良好且运行成本较低。GraphRAG 在索引时间和 LLM 调用方面都会增加开销,因此其收益需要能抵消这笔投资。我个人建议,可以先从标准的 RAG 开始,当遇到它的局限性时,再考虑转向 GraphRAG。
传统 RAG 与 GraphRAG 对比
下面的表格总结了它们之间的权衡。传统 RAG 在简单性和成本上占优,而 GraphRAG 则在需要综合分析或关联推理的问题上表现出色。
| 方面 | 传统 RAG | GraphRAG |
|---|---|---|
| 数据表示 | 孤立的文本块作为向量 | 包含实体和关系的知识图谱 |
| 结构保留 | 分块时丢失 | 通过图边保留 |
| 全局查询 | 差(检索片段,无法综合) | 强(对社区摘要进行 Map-Reduce) |
| 多跳推理 | 有限(独立块检索) | 原生(图遍历跟随连接) |
| 索引成本 | 低(仅嵌入) | 高(LLM 提取 + 嵌入 + 聚类) |
| 查询成本 | 低 | 变化(局部查询便宜,全局查询昂贵) |
| 最适用于 | 事实查找,小型语料库 | 主题性问题,关联领域 |
GraphRAG 管道
整个管道分为两个阶段:索引阶段构建图谱,查询阶段则利用它。
索引阶段
索引阶段通过五个步骤将原始文档转换为知识结构:
- 分块:将文档分割成约 300 个 token 的小块以进行处理。
- 实体和关系提取:从中提取人物、概念、组织以及它们之间的连接方式。
- 图谱构建:将提取出的信息转化为节点和边,并合并重复项。
- 社区发现:在多个层级对相关实体进行聚类。
- 社区摘要:为每个聚类生成文本描述。
提取步骤是 LLM 调用最集中的地方。每个文本块都会通过一个提示词进行处理,要求模型识别实体和关系。例如,“OpenAI 发布了 GPT-4”这个文本块会提取出 OpenAI 和 GPT-4 两个实体,以及它们之间的一个连接关系。同时,这个过程也会捕捉到关系的类型。由于每个文本块都需要一次 LLM 调用,因此索引是整个管道中最昂贵的部分。相比之下,查询时间会便宜很多,因为大部分繁重的工作在之前就已完成。
图谱构建处理实体解析,这往往比较棘手。“OpenAI”、“Open AI”和“这家公司”在不同文本块中可能都指的是同一个实体。系统会合并这些重复项,以创建一个干净的图谱。
社区发现应用 Leiden 算法在多个层级上找到自然的实体分组。0 级可能包含 5-10 个紧密相关的实体的小群组。更高级别则会将这些小群组归并到更广泛的主题中。比如,一个关于 AI 公司的语料库,可能会有 0 级的独立公司社区,1 级的“AI 实验室”和“芯片制造商”社区,以及 2 级涵盖整个科技生态系统的社区。然后,每个社区都会得到一个由 LLM 生成的摘要,描述该聚类代表的内容。这些摘要在任何用户查询到来之前就已经预先计算好了。
最终结果并不是一个简单的检索索引。它是一个结构化的表示:图谱加上摘要,准备好以不同的方式进行查询。
查询阶段
图谱构建完成后,查询会路由到不同的检索策略:
- 全局搜索:针对综合性问题,对社区摘要执行 Map-Reduce 操作。
- 局部搜索:针对特定查找,遍历实体邻域。
- 漂移搜索(DRIFT search):从宽泛的范围开始,然后深入到有前景的区域。
检索到的内容(摘要、实体、关系、源文本)会被组装成一个提示词,然后 LLM 生成最终答案。每种策略都服务于不同类型的查询,我们将在后面详细分解。
理解查询类型
GraphRAG 提供了三种不同的检索策略,每种都适用于不同类型的查询。选择哪种取决于你需要广泛的综合信息、特定的实体信息,还是介于两者之间的结果。
全局搜索
全局搜索回答需要理解整个语料库的问题。例如,“这份文档集合的主要主题是什么?”或“这些报告中出现了哪些模式?”这类问题,需要从所有地方聚合信息,而不是从几个匹配的文本块中检索。
它的机制是对社区摘要进行 Map-Reduce。在 Map 阶段,每个社区摘要都会独立处理:系统要求 LLM 提取相关要点并评估其重要性。在 Reduce 阶段,所有社区中评级最高的要点被聚合到一个最终的提示词中,然后 LLM 将它们综合成一个连贯的响应。
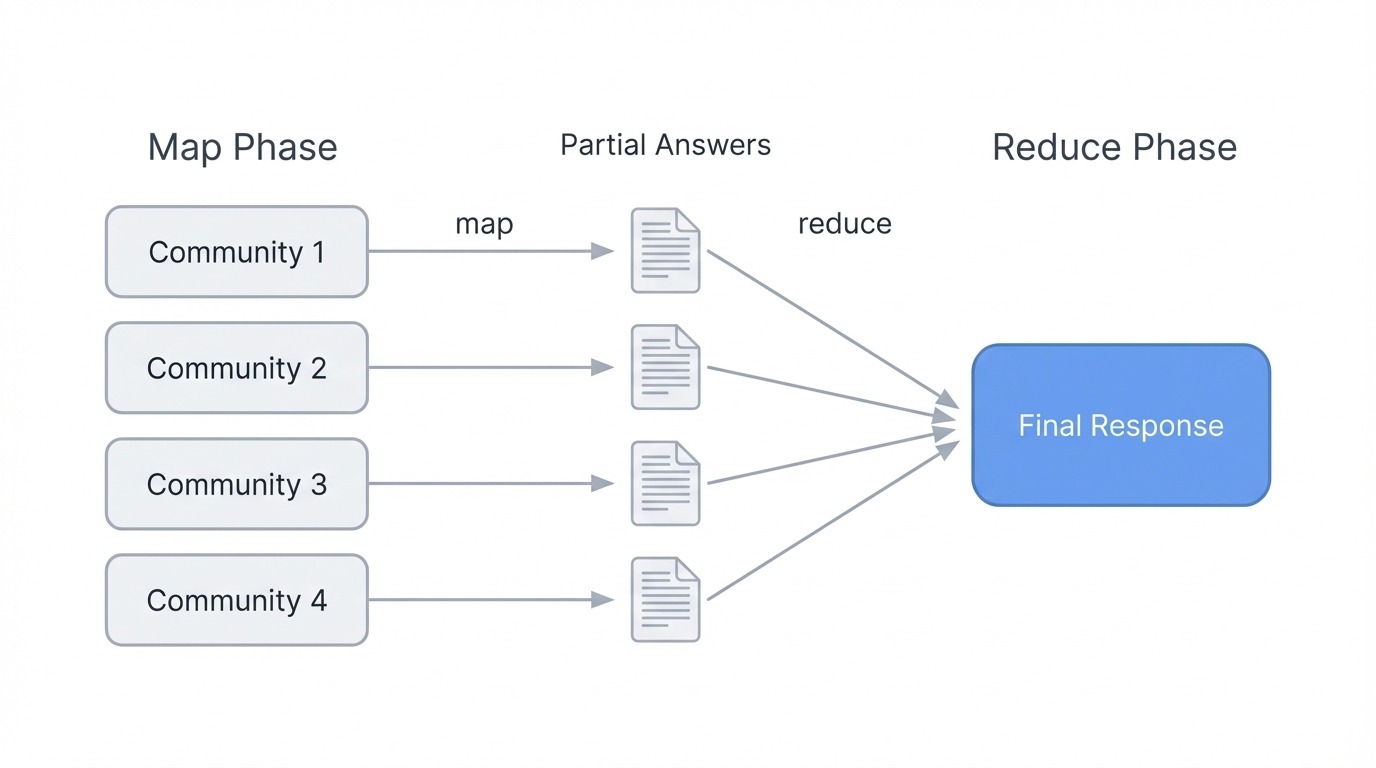 GraphRAG 使用 Map-Reduce 进行全局搜索。图片来源:作者
GraphRAG 使用 Map-Reduce 进行全局搜索。图片来源:作者
这之所以有效,是因为社区摘要本身就已捕捉了每个实体集群的含义。系统无需检索成千上万的文本块。相反,它基于预计算的描述进行推理,这些描述代表了图谱在任意层级下的结构。较低层级(更小、更紧密的社区)能给出更详细的答案,但会消耗更多的 LLM 调用。较高层级(更广泛的分组)运行速度更快,但可能会错过细微之处。
全局搜索在计算上比其他模式更重,因为它处理所有社区。因此,当问题确实需要语料库层面的理解而非具体事实时,才应该使用它。
局部搜索
局部搜索处理特定于实体的查询。例如,“洋甘菊有什么药用价值?”或“Acme 公司宣布了关于第三季度财报的什么消息?”这类问题,都指向了特定的实体及其相关信息。
检索过程首先是识别图谱中与查询相关的实体。这些实体成为遍历的入口点。从每个起始节点,系统会拉取连接的实体、它们之间的关系、任何相关的声明或事实,以及这些实体所属的社区报告。它还会检索与这些实体链接的原始文本块,从而为 LLM 提供结构化的图谱数据和源文本。
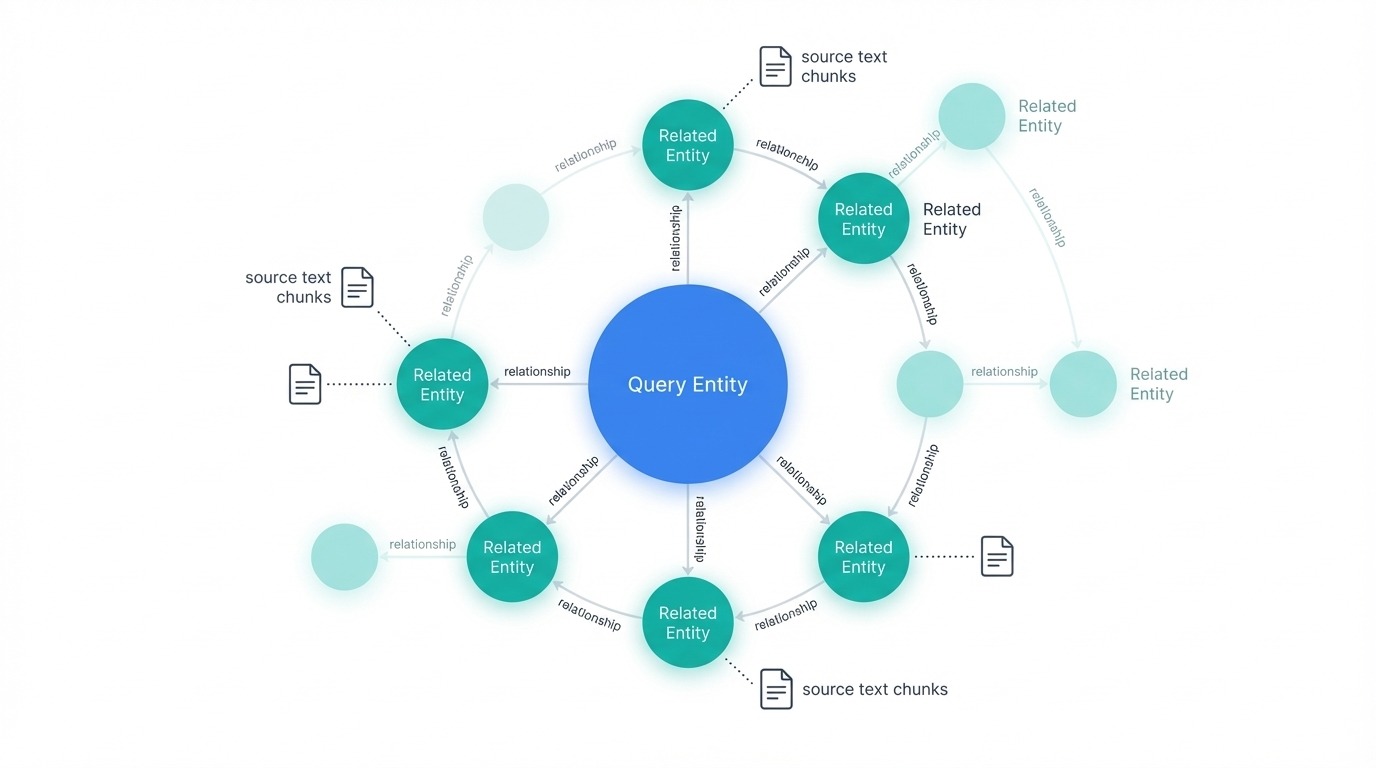 GraphRAG 局部搜索与相关节点。图片来源:作者
GraphRAG 局部搜索与相关节点。图片来源:作者
所有这些候选信息都会经过排序和筛选,以适应上下文窗口。然后,LLM 会基于检索到的内容生成答案。因为局部搜索只关注图谱的一个邻域,而不是整个图,所以它比全局搜索运行得更快、成本也更低。
当问题询问文档中提到的具体事物、人物、组织或概念时,请选择局部搜索。
DRIFT 搜索
DRIFT(Dynamic Reasoning and Inference with Flexible Traversal,灵活遍历的动态推理与推断)介于全局搜索和局部搜索之间。它处理那些既需要广泛上下文又需要具体细节的复杂查询。
这个过程分为三个阶段。首先是预处理阶段,它将查询与最具语义相关性的社区摘要进行比较,并生成初步答案以及后续问题。其次是后续阶段,它会利用这些后续问题进行局部搜索,深入到特定区域,产生中间答案和更具针对性的后续问题。第三是输出阶段,它将所有信息组合成平衡了全局洞察和局部细节的排序结果。
GraphRAG DRIFT 搜索三阶段过程。图片来源:作者
DRIFT 的有用之处在于它扩展了搜索的起点。通过从社区级上下文开始,它检索到的事实比纯粹的局部搜索更广泛。但通过局部遍历进行细化,它又避免了进行全面全局搜索的开销。
对于像“X 公司面临的挑战与更广泛的行业趋势有何关系?”这类既需要具体实体信息又需要主题背景的问题,DRIFT 是个不错的选择。
查询类型对比
| 方面 | 全局查询 | 局部查询 | DRIFT 查询 |
|---|---|---|---|
| 最适用于 | 语料库级主题和模式 | 特定实体问题 | 需要广度和特异性的复杂查询 |
| 机制 | 对社区摘要进行 Map-Reduce | 实体邻域遍历 | 预处理 → 后续 → 输出阶段 |
| 速度 | 最慢(处理所有社区) | 最快(聚焦遍历) | 中等(先宽泛,后收窄) |
| 成本 | 最高 | 最低 | 中等 |
| 示例查询 | “主要主题是什么?” | “X 公司发布了什么?” | “X 与行业趋势相比如何?” |
GraphRAG 也提供了一种基本的向量搜索作为备用,用于那些图遍历会显得大材小用的简单查询。不过,在大多数用例中,选择全局、局部或 DRIFT 已经能满足你的需求了。
实现 GraphRAG
本节将通过 Microsoft 的参考实现,来构建一个 GraphRAG 系统。我们将使用少量 Paul Graham 关于创业公司的文章作为语料库,以保持示例的可运行性,并控制成本。如果你是知识图谱与检索系统结合的新手,可以先看看知识图谱 RAG 教程,了解其基础概念。
安装和设置
创建一个项目目录并用 uv 初始化,然后安装 graphrag 包。这个库的依赖项相当多(包括 PyTorch 在内有 237 个包),所以安装可能需要五分钟左右:
mkdir ragtest && cd ragtest
uv init
uv add graphrag
graphrag init --root .
这会生成项目结构:
ragtest/
├── .env # API key configuration
├── settings.yaml # Pipeline settings
├── prompts/ # LLM prompt templates
│ ├── extract_graph.txt
│ ├── summarize_descriptions.txt
│ └── ...
└── input/ # Your source documents go here
prompts/ 目录包含了 GraphRAG 用于实体提取和摘要的模板。你可以根据领域特定需求进行定制,不过默认设置对于一般文本来说已经很不错了。
准备文档
将文本文件添加到 input/ 目录。本教程中,我们将使用 Paul Graham 关于创业公司的三篇随笔。他的网站使用极简的 HTML,内容被 <font> 标签包裹,所以一个简单的解析器就能干净地提取文本:
import urllib.request
from html.parser import HTMLParser
class TextExtractor(HTMLParser):
def __init__(self):
super().__init__()
self.text = []
self.in_font = False
def handle_starttag(self, tag, attrs):
if tag == 'font':
self.in_font = True
def handle_endtag(self, tag):
if tag == 'font':
self.in_font = False
def handle_data(self, data):
if self.in_font:
self.text.append(data)
essays = {
"startupideas": "http://paulgraham.com/startupideas.html",
"do_things_that_dont_scale": "http://paulgraham.com/ds.html",
"startup_growth": "http://paulgraham.com/growth.html"
}
for name, url in essays.items():
with urllib.request.urlopen(url) as response:
html = response.read().decode('utf-8')
parser = TextExtractor()
parser.feed(html)
text = ' '.join(parser.text)
with open(f"input/{name}.txt", "w") as f:
f.write(text)
print(f"Saved {name}.txt ({len(text.split())} words)")
Saved startupideas.txt (3000 words)
Saved do_things_that_dont_scale.txt (3000 words)
Saved startup_growth.txt (3000 words)
总共有大约 9,000 字,来自三篇主题相关的文章,这足够看到有意义的实体关系,又不会产生过高的 API 成本。
配置管道
编辑 .env 文件,添加你的 OpenAI API 密钥:
GRAPHRAG_API_KEY=your-openai-api-key-here
默认的 settings.yaml 文件可以直接使用,但你可能想调整模型。该文件默认使用的是 gpt-4o-mini,它在成本和质量之间取得了平衡。查看完整的配置参考获取所有可用选项:
models:
default_chat_model:
type: openai_chat
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: gpt-4o-mini
model_supports_json: true
concurrent_requests: 25
default_embedding_model:
type: openai_embedding
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: text-embedding-3-small
配置中其他值得注意的设置:
chunks:
size: 1200 # Tokens per chunk
overlap: 100 # Overlap between chunks
extract_graph:
entity_types: [organization, person, geo, event]
max_gleanings: 1 # Additional extraction passes
cluster_graph:
max_cluster_size: 10
运行索引管道
使用以下命令构建知识图谱:
graphrag index --root .
管道会通过实体提取、图谱构建和社区发现等步骤处理文档:
├── Loading Input (InputFileType.text) - 3 files loaded (0 filtered) ───
├── create_base_text_units
├── create_final_documents
├── extract_graph
├── finalize_graph
├── create_final_entities
├── create_final_relationships
├── create_final_text_units
├── create_base_entity_graph
├── create_communities
├── create_final_communities
├── create_community_reports
├── generate_text_embeddings
⠋ GraphRAG Indexer
├── All workflows completed successfully
每一步都建立在前一步的基础上。extract_graph 阶段会进行大部分的 LLM 调用,而 create_communities 则应用 Leiden 算法来聚类相关实体。
通过这三篇文章,索引大概在两分钟内完成。你可以通过加载 parquet 文件或检查行数来查看结果:
- 3 篇文档共 12 个文本块
- 74 个实体(人物、组织、概念)
- 89 种实体间关系
- 不同层级的 12 个社区
输出结果以 parquet 文件的形式保存在 output/ 目录下:
output/
├── documents.parquet
├── entities.parquet
├── relationships.parquet
├── text_units.parquet
├── communities.parquet
├── community_reports.parquet
└── lancedb/ # Vector embeddings
Parquet 格式使得所有数据都具有良好的可移植性。你可以用 pandas 加载这些文件来检查实体、浏览关系或调试提取问题。整个项目目录小到足以进行版本控制(这个语料库不到 10MB),只需排除包含 API 密钥的 .env 文件。
通过 CLI 进行查询
GraphRAG 提供了三种查询模式。我们来一一尝试。
全局搜索用于主题性问题:
graphrag query \
--root . \
--method global \
--query "What are the main themes and lessons about startups in these essays?"
SUCCESS: Global Search Response:
The essays present several interconnected themes about startups:
**Growth as the defining characteristic**: A startup isn't just a new company—it's
specifically designed for rapid growth. This growth orientation shapes everything
from idea selection to daily decision-making. The essays suggest using weekly
growth rate as a compass for all strategic choices.
**The power of doing unscalable things**: Counterintuitively, successful startups
often begin with manual, labor-intensive approaches. Stripe's founders would
physically set up new users on the spot. Airbnb's founders went door-to-door
recruiting hosts. These unscalable tactics bootstrap the initial user base.
**Ideas emerge from problems, not brainstorming**: The best startup ideas come
from founders solving their own problems or noticing gaps while "living in the
future." Deliberately trying to generate ideas tends to produce plausible-sounding
but ultimately weak concepts.
**User relationships matter early**: Early users provide irreplaceable feedback.
Founders should go beyond standard customer service to create exceptional
experiences, gathering insights that shape the product.
这个响应综合了三篇文章的主题,这在传统 RAG 中需要检索和处理许多文本块才能实现。全局搜索从社区摘要中提取信息,提供了一个连贯的、高层次的视图。
局部搜索用于特定实体问题:
graphrag query \
--root . \
--method local \
--query "What role does Y Combinator play according to these essays?"
SUCCESS: Local Search Response:
Y Combinator functions as both an accelerator and a testing ground for startup
principles. According to the essays, YC provides:
**Funding and validation**: YC offers initial funding that lets founders focus
on building rather than fundraising. The program validates ideas through its
selection process.
**Growth measurement framework**: YC tracks startups by weekly growth rate,
with 5-7% weekly growth considered good and 10% exceptional. This metric-driven
approach forces founders to confront whether they're making real progress.
**Network effects**: B2B startups at YC gain immediate access to hundreds of
potential customers—other YC companies. Stripe leveraged this extensively in
its early days.
**Demo Day as forcing function**: The program's structure, culminating in Demo
Day presentations to investors, creates urgency that pushes founders to ship
and iterate quickly.
局部搜索从 Y Combinator 实体开始遍历图谱,引入了增长指标、Stripe 和 Demo Day 等相关概念。答案紧密围绕文章中关于 YC 的实际描述,而非一般性知识。
DRIFT 搜索用于需要广度和特异性的问题:
graphrag query \
--root . \
--method drift \
--query "How do the essays describe the relationship between startup ideas and user problems?"
SUCCESS: Drift Search Response:
The essays establish a direct link between viable startup ideas and genuine user
problems through several mechanisms:
**Organic discovery over invention**: Rather than brainstorming ideas, founders
should notice problems they personally experience. Microsoft, Apple, Google, and
Facebook all started this way—founders building something they themselves needed.
**The "well" vs "shallow hole" distinction**: Good ideas serve a small number of
users who desperately need the solution (a narrow, deep well) rather than many
users with mild interest (a broad, shallow hole). Depth of need matters more
than breadth of appeal initially.
**Feedback loops as validation**: Engaging directly with early users reveals
whether the problem is real and the solution fits. This feedback shapes the
product more than any amount of planning.
**Problem-first, solution-second**: The essays warn against "sitcom startup
ideas"—概念 that sound plausible but don't address real pain points. A
social network for pet owners sounds reasonable but lacks urgent demand.
DRIFT 从社区层面的创业理念上下文开始,然后深入到像“井”类比和情景喜剧创意等具体例子。结果融合了主题洞察和源文本中的具体细节。
通过 Python 进行编程访问
对于生产系统,我建议直接使用 Python API。这个过程分为三部分:加载配置、加载索引数据和运行查询。
首先,通过加载环境变量和解析设置文件来设置配置:
import os
import yaml
from pathlib import Path
from dotenv import load_dotenv
from graphrag.config.create_graphrag_config import create_graphrag_config
ROOT_DIR = Path(".")
# Load environment variables and config
load_dotenv(ROOT_DIR / ".env")
with open(ROOT_DIR / "settings.yaml") as f:
yaml_content = f.read()
yaml_content = os.path.expandvars(yaml_content) # Expand ${VAR} references
settings = yaml.safe_load(yaml_content)
config = create_graphrag_config(values=settings, root_dir=str(ROOT_DIR))
接下来,从 parquet 文件加载所有索引数据。GraphRAG 将实体、关系、社区和文本块分开存储:
import pandas as pd
output_dir = ROOT_DIR / "output"
entities = pd.read_parquet(output_dir / "entities.parquet")
communities = pd.read_parquet(output_dir / "communities.parquet")
community_reports = pd.read_parquet(output_dir / "community_reports.parquet")
text_units = pd.read_parquet(output_dir / "text_units.parquet")
relationships = pd.read_parquet(output_dir / "relationships.parquet")
print(f"Loaded {len(entities)} entities, {len(relationships)} relationships")
Loaded 74 entities, 89 relationships
最后,使用异步 API 运行查询。local_search 函数接受所有数据帧以及查询参数:
import asyncio
from graphrag.api import local_search
async def run_query(query: str):
response, context = await local_search(
config=config,
entities=entities,
communities=communities,
community_reports=community_reports,
text_units=text_units,
relationships=relationships,
covariates=None,
community_level=2,
response_type="Multiple Paragraphs",
query=query,
)
return response
query = "What advice do the essays give about finding startup ideas?"
response = asyncio.run(run_query(query))
print(response)
The essays provide several valuable insights into finding startup ideas:
Focus on Growth: A startup is designed to grow quickly. Founders should commit
to seeking ideas that can scale significantly, as this distinguishes startups
from ordinary businesses.
Identify Unmet Needs: Successful startups arise from recognizing problems that
need solving. Founders who can see different problems, particularly those
addressable through technology, are more likely to develop effective solutions.
Leverage Personal Insights: Many successful startups originate from the unique
insights of their founders, often stemming from personal experiences or
frustrations. This personal connection leads to more authentic solutions.
Explore Overlooked Markets: Founders should think outside the box and explore
markets that may be overlooked. Successful startups often emerge from ideas
that seem obvious to the founders but aren't yet recognized broadly.
Python API 让你能够完全控制加载哪些数据、查询哪个社区层级以及如何格式化响应。对于需要自定义检索逻辑或与现有系统集成的应用程序,这是必经之路。
结语
传统 RAG 好用,但终有其极限。当用户询问主题或模式,而你只得到一堆松散相关的文本块而非连贯的答案时,你就知道碰到瓶颈了。这正是 GraphRAG 致力于解决的问题,它用带有预计算社区摘要的知识图谱,替代了简单的文本块。
不过,成本是实实在在的。索引过程会消耗大量的 LLM 调用,全局搜索也不便宜。对于小型文档集合或简单查询,还是坚持使用向量搜索吧。
但如果你的语料库中实体之间存在丰富的关联,并且你的用户关心这些关联,那么 GraphRAG 会带来可观的回报。根据你的查询类型选择相应的检索策略:全局搜索适用于主题,局部搜索适用于特定实体,DRIFT 搜索则适用于两者兼顾的情况。一旦你操作过一次,它的实现其实并不复杂,而且 parquet 输出让整个过程易于检查和调试。
关于
关注我获取更多资讯

