OpenAI 最近悄悄地向开发者平台推送了 GPT-5.1-Codex,不少开发者已经开始称它为目前最强的编码模型。和早期那些专注于代码补全的 Codex 版本不同,GPT-5.1-Codex 的设计目标直指真实的软件工程场景,尤其擅长需要长时间推理和工具协作的 Agentic 任务。
这篇文章,我们就来动手实践一下,用 OpenAI Agents 和 GPT-5.1 Codex 打造一个完整的 GitHub Issue 分析器。
这个 Agent 要能做到:
- 直接从任何 GitHub 仓库抓取指定的 Issue。
- 理解、拆解 Issue 的内容,并对其进行分类。
- 只检查仓库中相关的代码文件和目录,而不是全盘扫描。
- 在需要时,能通过 Firecrawl API 搜索外部文档或进行网页抓取。
- 最终,生成一份详尽、可执行的步骤化工程计划。
简单来说,我们要让这个 Agent 像一位资深工程师那样工作:在动手写代码之前,先调研、阅读、推理和规划。
GPT-5.1-Codex 到底强在哪?
GPT-5.1 Codex 是 GPT-5.1 的一个特化版本,它不是为简单的代码片段补全而生,而是为了处理长周期的、需要与外部工具交互的编码任务。它被专门设计用于模拟真实的软件工程工作流,这使它成为我们这个 “Issue-to-Plan” 自动化流程的理想引擎。
和通用大模型相比,Codex 理解代码库的方式更接近一个经验丰富的开发者。它会阅读 Issue,思考项目架构,定位到可能受影响的目录,然后只检查那些真正关键的文件。这种工作方式让我们的 Agent 运行得更快、更智能,也更节省成本。
GPT-5.1 Codex 的另一个优势是它与开发者工具的无缝集成能力。通过 OpenAI Agents 框架,它可以很自然地调用 GitHub CLI、Firecrawl API 等外部工具。这意味着我们的 Agent 能够按需获取 Issue、浏览项目结构、读取特定文件内容,甚至去查阅相关技术文档。
正是这种强大的代码理解能力和工具驱动的推理能力,让 GPT-5.1 Codex 成为了我们项目的支柱。它为 Agent 带来了工程直觉、结构化思维和精确性,确保最终生成的工程计划是准确且可操作的。
准备工作:搭建你的开发环境
在开始敲代码之前,先确保你的环境配置妥当。
首先,你需要安装 Git。在终端运行 git --version 检查一下。同时,你需要一个 OpenAI 开发者账户,并确保账户里至少有几美元的余额,以防 API 调用中断。
接下来,我们需要一个免费的 Firecrawl 账户来处理网页抓取和搜索。获取 API 密钥后,将它们设置为环境变量。这些 key 是你的 Agent 和 OpenAI/Firecrawl 对话的的凭证:
export OPENAI_API_KEY=sk-...
export FIRECRAWL_API_KEY="fc-..."
然后,安装项目所需的 Python 库。openai-agents 是一个轻量级的框架,这个框加让构建多 Agent 流程变得出奇的简单。firecrawl-py 则负责处理网页抓取和信息提取。
pip install openai-agents
pip install firecrawl-py
最后,确保你已经安装并配置好了 GitHub CLI。运行以下命令登录你的 GitHub 账户:
gh auth login

核心构建:代码实现拆解
我们的项目目录结构如下,所有代码都放在 src 文件夹下。tools 目录存放 Agent 可以使用的工具函数,agents_pkg 存放 Agent 的定义,而 app.py 是我们的主程序入口。
1. 定义 Agent 的“工具箱”
Agent 的能力来自于它能使用的工具。我们先来定义这些工具,它们本质上就是一些 Python 函数,通过 @function_tool 装饰器暴露给 Agent。
Firecrawl API 工具
在 src/tools/firecrawl_tools.py 文件中,我们创建两个工具:一个用于网页搜索,一个用于抓取特定 URL 的内容。这能让 Agent 在分析 Issue 时,如果遇到不熟悉的技术栈或需要查阅文档,可以自行上网学习。
# src/tools/firecrawl_tools.py
import json
import os
from agents import function_tool
from firecrawl import firecrawl
def _get_firecrawl_client():
api_key = os.getenv("FIRECRAWL_API_KEY")
if not api_key:
raise RuntimeError("FIRECRAWL_API_KEY is not set")
return firecrawl(api_key=api_key)
@function_tool
def firecrawl_search(query: str, limit: int = 3) -> str:
"""
运行 Firecrawl 搜索与 Issue 或技术栈相关的文档。
Args:
query: 搜索查询(通常基于 Issue 标题、框架或错误信息)。
limit: 返回结果的最大数量。
Returns:
Firecrawl 搜索结果的 JSON 字符串。
"""
client = _get_firecrawl_client()
results = client.search(query=query, limit=limit)
return json.dumps(results)
@function_tool
def firecrawl_scrape(url: str) -> str:
"""
使用 Firecrawl 抓取单个 URL 以进行更深入的研究。
Args:
url: 要抓取的 URL(文档、博客、其他仓库的 README 等)。
Returns:
从 Firecrawl 抓取到的页面内容(markdown/结构化)的 JSON 字符串。
"""
client = _get_firecrawl_client()
result = client.scrape(url=url, params={"formats": ["markdown"]})
return json.dumps(result)
GitHub CLI 工具
接下来,在 src/tools/github_tools.py 中,我们封装 GitHub CLI 的功能。这些工具是 Agent 与代码库交互的眼睛和手。
get_github_issue: 获取指定 Issue 的详细信息。list_repo_files_gh: 列出仓库中的文件。关键在于,我们让 Agent 可以通过path_prefixes和extensions参数进行过滤,避免扫描整个项目,从而节约成本和时间。get_repo_file_gh: 读取单个文件的内容。
# src/tools/github_tools.py
import base64
import json
import subprocess
from typing import List, Optional
from agents import function_tool
@function_tool
def get_github_issue(repo: str, issue_number: int) -> str:
"""使用 GitHub CLI 获取一个 GitHub issue。"""
try:
result = subprocess.run(
[ "gh", "issue", "view", str(issue_number), "--repo", repo, "--json", "number,title,body,labels,url,author,createdAt,state,assignees" ],
capture_output=True, text=True, check=True,
)
return result.stdout
except subprocess.CalledProcessError as e:
return json.dumps({ "error": "Failed to fetch issue via GitHub CLI", "stderr": e.stderr, "repo": repo, "issue_number": issue_number })
@function_tool
def list_repo_files_gh(repo: str, max_files: int = 80, extensions: Optional[List[str]] = None, path_prefixes: Optional[List[str]] = None) -> str:
"""使用 GitHub CLI 列出远程仓库中的相关文件。"""
# ... 省略实现细节,主要是调用 gh api repos/{repo}/git/trees/HEAD?recursive=1 并进行过滤 ...
# ... full implementation in the original article ...
pass
@function_tool
def get_repo_file_gh(repo: str, path: str, ref: str = "", max_chars: int = 8000) -> str:
"""使用 GitHub CLI 从远程仓库读取文件内容。"""
# ... 省略实现细节,主要是调用 gh api repos/{repo}/contents/{path} 并解码内容 ...
# ... full implementation in the original article ...
pass
注:为简洁起见,list_repo_files_gh 和 get_repo_file_gh 的完整代码已省略,你可以在项目源码中找到它们。
2. 设计核心大脑——Planner Agent
工具箱有了,现在需要给 Agent 一个大脑。我们在 src/agents_pkg/planner_agent.py 中定义我们的 Issue Planner Agent。
这是整个项目的核心。我们通过 instructions 参数(也就是 Prompt)来塑造 Agent 的行为模式和思考方式。我们告诉它,它是一位资深软件工程师,目标是生成一份清晰的执行计划。
特别地,我们强调了它的工作流程和策略:
- 要节约成本:不要扫描整个项目。
- 先理解问题:首先调用
get_github_issue。 - 推理先行:根据 Issue 内容,推断出可能相关的代码目录。
- 精准搜索:使用
list_repo_files_gh并带上path_prefixes参数来缩小范围。 - 深入研究:只对筛选出的几个关键文件调用
get_repo_file_gh。 - 寻求外援:如果需要,使用 Firecrawl 工具搜索文档。
- 结构化输出:最后,按照指定的格式输出执行计划。
# src/agents_pkg/planner_agent.py
from agents import Agent
from tools.github_tools import get_github_issue, list_repo_files_gh, get_repo_file_gh
from tools.firecrawl_tools import firecrawl_search, firecrawl_scrape
def build_planner_agent() -> Agent:
"""
Issue Planner agent,它会:
- 读取 GitHub issue
- 推理仓库的哪些部分是相关的
- 使用 GitHub CLI 在线检查一小部分文件
- 使用 Firecrawl 进行外部研究
- 输出一个具体的、分步的执行计划
"""
return Agent(
name="Issue Planner",
instructions=(
"你是一名资深软件工程师。\n"
"目标:根据给定的 GitHub issue 和在线仓库(结构+文件),加上可选的外部研究,"
"生成一份清晰的、分步的执行计划来解决该 issue。\n\n"
"重要策略(要聪明一点):\n"
"- 要有选择性,注意成本。不要扫描整个项目。\n"
"- 首先,深入阅读 issue,推断它影响了系统的哪个部分。\n"
"- 根据这个推理,确定一小部分路径前缀和文件类型。\n\n"
"推荐工作流程:\n"
"1. 调用 get_github_issue(repo, issue_number) 来完全理解问题。\n"
"2. 从 issue 中推断出一小部分可能包含相关代码的路径前缀,例如 ['src/', 'app/']。\n"
"3. 调用 list_repo_files_gh,并设置 path_prefixes 为你推断的路径列表。\n"
"4. 从返回的文件列表中,挑选最多约 5-15 个最可能相关的关键文件。\n"
"5. 只对这些选定的文件调用 get_repo_file_gh(repo, path=...) 来检查具体实现。\n"
"6. 如果需要框架或库的上下文,使用 firecrawl_search 和 firecrawl_scrape。\n\n"
"输出格式(执行计划):\n"
"在你获得足够上下文后,输出一个简洁但具体的计划,包含以下部分:\n"
" - 问题摘要\n"
" - 项目/代码库理解\n"
" - 关键文件/组件\n"
" - 分步实施计划\n"
" - 测试策略\n"
" - 边缘情况、风险和开放问题\n"
),
tools=[
get_github_issue,
list_repo_files_gh,
get_repo_file_gh,
firecrawl_search,
firecrawl_scrape,
],
model="gpt-5.1-codex",
)
3. 构建 CLI 应用入口
最后,我们在 src/app.py 中创建一个命令行界面,将所有部分串联起来。这个文件负责处理用户输入、调用 Agent、以流式方式打印 Agent 的思考过程和最终结果,并将其保存到 Markdown 文件中。
流式输出(Streaming)非常重要,它能让我们实时看到 Agent 的“心路历程”:它在想什么(Reasoning)、它在调用哪个工具(Tool Call),这让整个过程不再是一个黑盒。
# src/app.py
import argparse
import asyncio
# ... 其他导入 ...
from agents import Runner
from agents_pkg.planner_agent import build_planner_agent
async def main() -> None:
"""应用程序的主入口点。"""
args = parse_args() # 解析命令行参数 --repo 和 --issue
repo, issue_number = get_user_input(args) # 获取用户输入
validate_environment() # 检查 API Key
agent = build_planner_agent()
user_prompt = build_user_prompt(repo, issue_number) # 构建初始提示
markdown_file = setup_output_file(repo, issue_number) # 设置输出文件路径
print(f"\n🔍 正在分析 {repo}#{issue_number}...\n")
# 以流式方式运行 Agent
try:
final_output = await run_agent_with_streaming(agent, user_prompt, repo, issue_number)
except Exception as e:
# ... 错误处理与降级运行 ...
pass
# 将输出保存到文件
save_output_to_file(markdown_file, repo, issue_number, final_output)
if __name__ == "__main__":
asyncio.run(main())
注:完整的 app.py 包含许多处理流式事件、格式化输出的辅助函数,这里只展示了主流程。
效果演示:让 Agent 跑起来
你可以通过两种方式运行这个应用。
交互模式:不带任何参数运行,程序会提示你输入仓库名和 Issue 编号。
python src/app.py
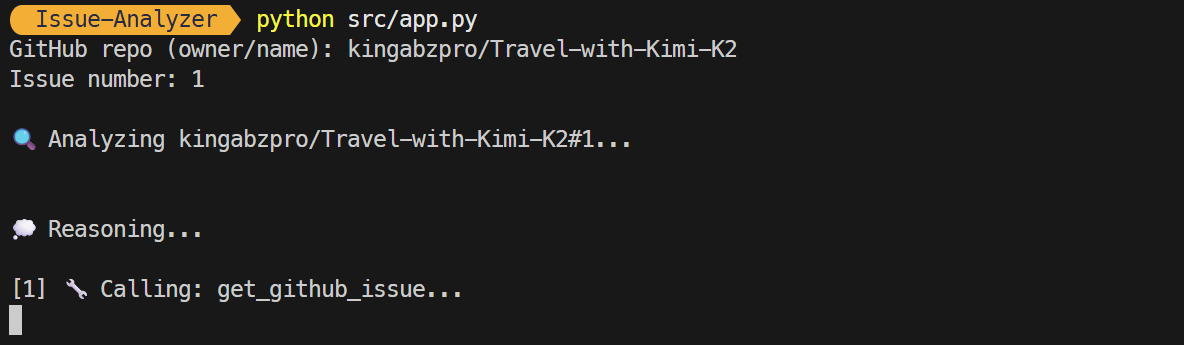
CLI 模式:直接在命令中提供参数。
python src/app.py --repo kingabzpro/Travel-with-Kimi-K2 --issue 1
程序启动后,你会看到 Agent 的实时工作流,包括它的推理步骤和工具调用。
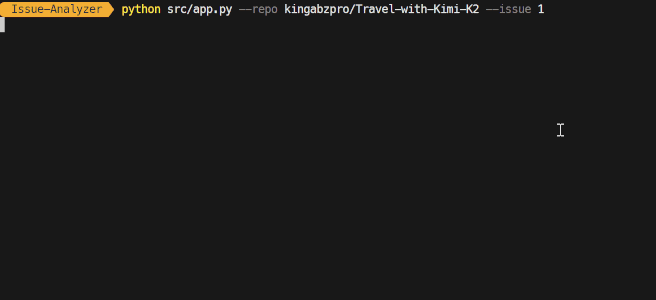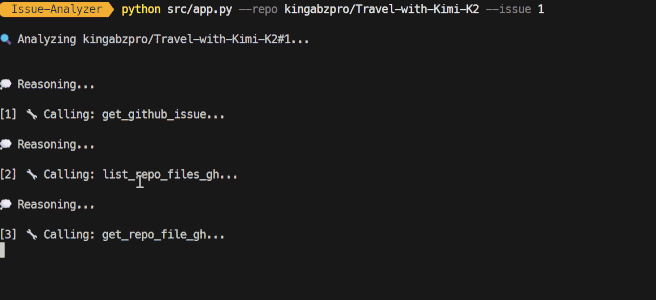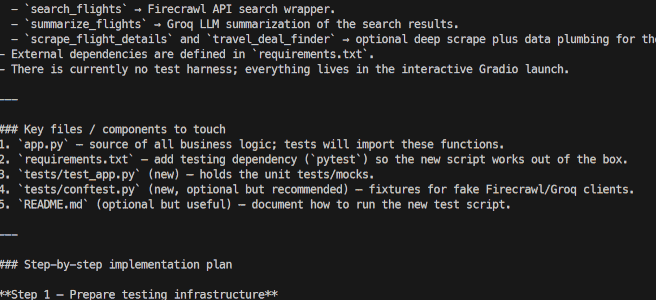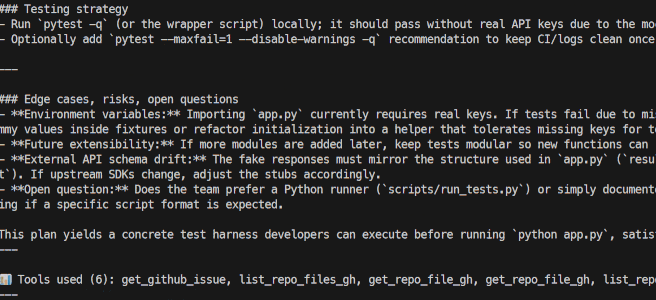
几秒钟后,它会生成一份详细的报告,并保存在 output 文件夹下的一个 Markdown 文件中。
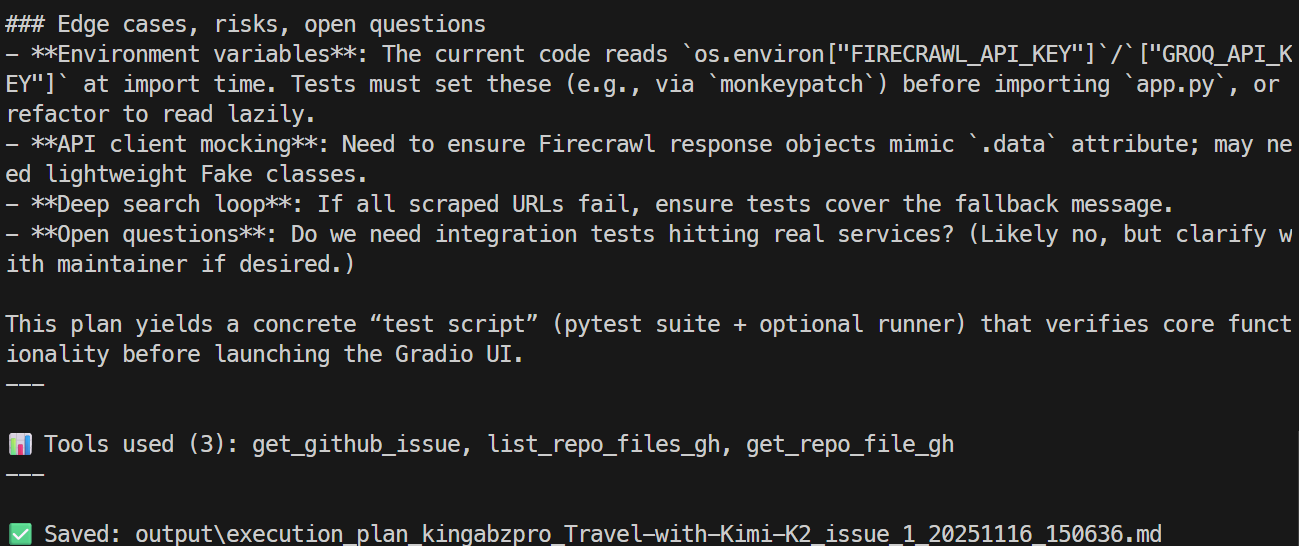
打开这个文件,你就能看到一份由 AI 生成的、结构清晰的工程计划。

未来展望:从“规划师”到“执行者”
目前我们的 Agent 是一个出色的“规划师”,但它的潜力远不止于此。Agentic 工作流的真正魅力在于端到端的自动化。以下是一些可以扩展的方向:
-
自动创建分支和 PR:让 Agent 在生成计划后,继续执行。它可以自动创建新分支,根据计划修改代码,然后使用
gh pr create命令提交一个 Pull Request,甚至还能自动生成 PR 描述和关联 Issue。 -
批量问题分析:扩展 Agent 的能力,使其可以一次性分析多个 Issue,对整个项目积压(backlog)进行分类、识别重复项,并评估复杂度。
-
PR 前的测试与验证:在提交 PR 之前,增加一个验证 Agent。它可以负责运行单元测试、检查代码格式、进行静态分析,确保提交的代码是干净、安全且不会破坏现有功能的。
总结
通过这个项目,我们可以看到 GPT-5.1 Codex 和 openai-agents 库的强大之处。构建一个复杂、多步骤的 Agent 其实比想象中要简单。核心在于:定义好你的工具,并用清晰的指令告诉模型何时以及如何使用它们。
我个人认为,这类 Agentic 工作流代表了 AI 辅助开发的未来方向。它不再是简单的代码补全,而是真正地将 AI 作为一个能够独立思考和执行任务的“初级工程师”或“技术助理”集成到开发流程中。这让开发者可以把更多精力放在更高层的架构设计上,而不是重复性的编码劳动,这再未来会越来越普遍。
关于
关注我获取更多资讯

