
前言:探索 Gemini 原生的图像与视频理解能力
Google Gemini 模型家族凭借其原生的多模态(multimodal)和长文本处理(long-context)能力,为众多 Google 产品(如 NotebookLM 和 Google 智能镜头)提供了强大的技术支持,同时也为广大开发者开辟了构建创新应用的无限可能。
本文将重点介绍七个基于 Gemini API 的图像与视频处理应用场景。这些示例主要基于 Gemini 1.5 Pro,这是我们在图像与视频理解方面性能最强的模型。当然,我们也鼓励开发者根据任务的复杂性,尝试使用性价比更高的 Gemini 1.5 Flash 或 Gemini 1.5 Flash-8B 模型。希望这些案例能为你带来启发,激发更多基于视觉功能的开发灵感。
场景一:生成详尽的图像描述
Gemini 模型不仅能精确描述图像内容,还能回答关于图像的提问,并进行逻辑推理。开发者可以通过提示词(Prompt)灵活控制描述的长度、语气和格式,从而使模型输出完美契合特定应用场景的需求。
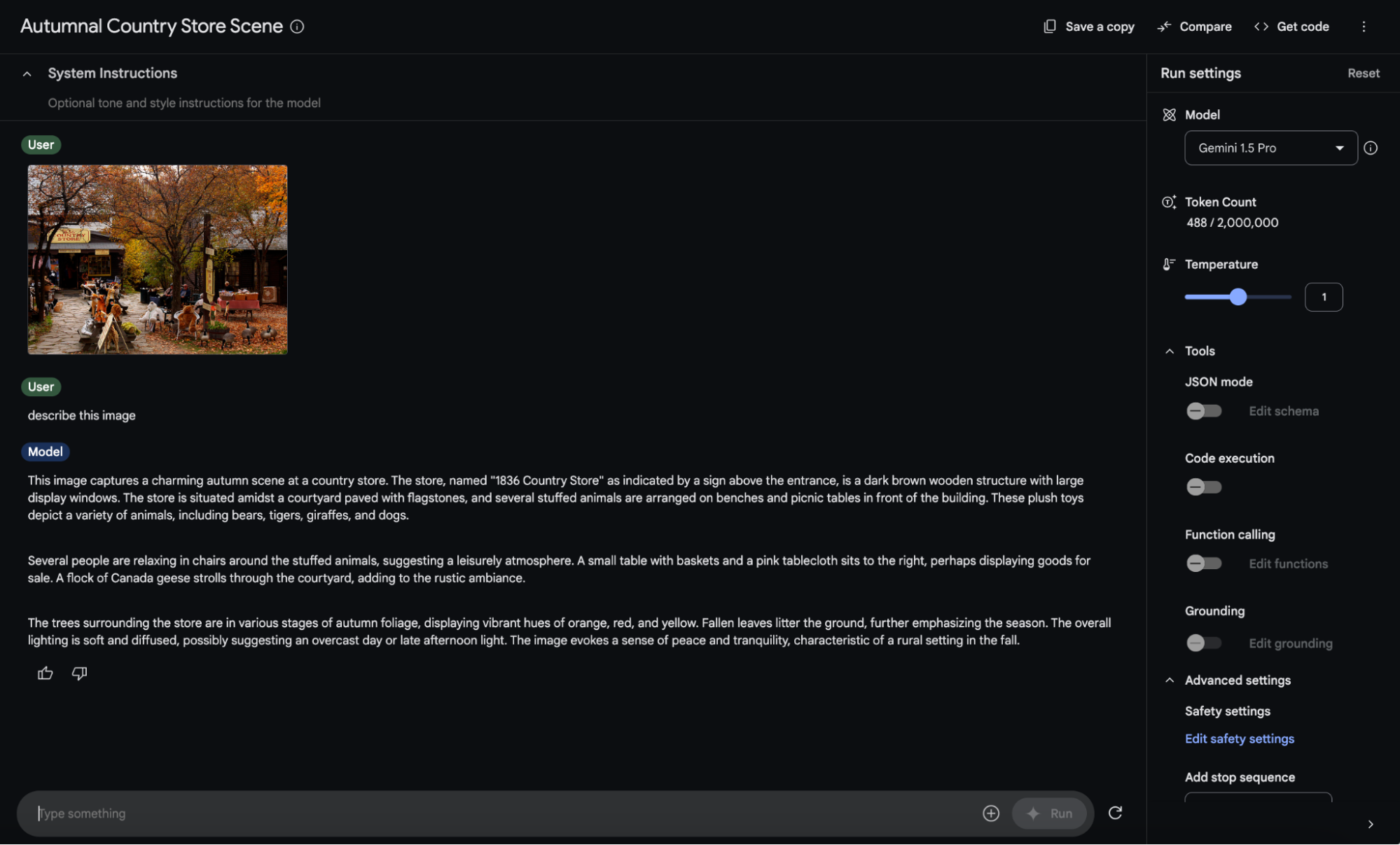
场景二:长篇 PDF 文档的深度理解与数据提取
Gemini 能够处理并理解超过 1,000 页的 PDF 文档。其原生的视觉功能使其可以准确地转录表格、解析复杂的多列布局、理解图表、草图、示意图甚至是手写文本。更强大的是,它能整合这些文本和视觉信息,完成端到端的复杂任务。
在下面的示例中,我们向 Gemini 提供了 Alphabet 过去 15 个季度的财报(总计 152 页),并要求它完成以下任务:
- 从所有文档中提取 Google 的季度收入数据。
- 创建一个 Markdown 表格来汇总这些数据。
- 使用
matplotlib编写 Python 代码,将收入和季度环比增长情况进行可视化。
提示 (Prompt) 1:
以下是过去 15 个季度的收入报告。
- 用 Markdown 格式生成一个表格,展示从“截至 2021 年 3 月 31 日的季度”到“截至 2024 年 9 月 30 日的季度”期间每个季度的总收入情况。一共应有 15 个季度。
- 为 Google 的每项产品/服务(“Google 搜索”、“YouTube 广告”、“Google 网络”、“Google 订阅、平台与设备”、“Google Cloud”以及“其他项目”)生成一个各季度总收入情况的表格,总共涉及 15 个季度。在输出内容中以多个表格的形式展示(每个表格呈现 4 个季度的数据)。请注意,在 2023 年第三季度及之前,“Google 订阅、平台与设备”被称作“Google 其他”项目。
模型响应 (部分):
以下是您需求的表格:
**1. 按季度划分的总收入(单位:百万美元)**
| 季度截至 | 年份 | 总收入 |
|---|---|---|
| 3 月 31 日 | 2021 | 55,314 |
| 6 月 30 日 | 2021 | 61,880 |
| 9 月 30 日 | 2021 | 65,118 |
| ... | ... | ... |
| 9 月 30 日 | 2024 | 88,268 |
**2. 按 Google 产品/服务划分的收入(单位:百万美元)**
**2021 第一季度至第四季度**
| 季度截至 | Google 搜索 | YouTube 广告 | Google 网络 | Google 其它 | Google Cloud | 其他项目|
|---|---|---|---|---|---|---|
| 2021 年 3 月 31 日 | 31,879 | 6,005 | 6,800 | 6,494 | 4,047 | 198 |
| 2021 年 6 月 30 日 | 35,845 | 7,002 | 7,597 | 6,623 | 4,628 | 192 |
| ... | ... | ... | ... | ... | ... | ... |
提示 (Prompt) 2:
利用生成的表格编写 Matplotlib 代码,以柱状图的形式将这些收入情况进行可视化呈现。在 x 轴上绘制时间(按时间顺序排列 15 个季度),在 y 轴上绘制每个时间段的总收入以及每项产品和服务的收入。不要给用户留下需要填补的代码部分。不考虑“其他项目”,并且要确保各柱形间距相等。
代码生成的图表:

提示 (Prompt) 3:
很好!现在,您能否生成一个展示各个产品领域收入环比增长情况的图表?x 轴应代表时间(15 个季度中的每一个季度),y 轴应代表收入增长百分比,图表还上应包含 6 条线。即便变量值之前已经定义过,在代码中依然要将其保留。不考虑“其他项目”。
收入环比增长的定义为:(本季度收入 - 上一季度收入)/ 上一季度收入。
代码生成的图表:

场景三:真实世界文档的智能推理
Gemini 1.5 模型能够理解并从现实世界的各类文档中提取信息,例如收据、标签、标识牌、便条、白板草图和个人记录等。以下示例展示了 Gemini 如何从一张收据图像中提取用户自定义的字段,并将其格式化为 JSON 对象返回。

场景四:网页数据的自动化提取
Gemini 模型可以直接从网页的屏幕截图中提取数据,并以 JSON 等结构化格式返回。这种能力使其能够像人类一样实时“看到”并理解页面内容(包括网页上的图像和视频),为构建网络数据 API、自动化浏览代理等应用提供了可能。
以下示例展示了 Gemini 如何将 Google Play 图书页面的信息转换为结构化的 JSON 输出。
提示 (Prompt):
从此网页中提取每一本图书的相关信息,并返回一个 JSON 对象列表,其中每个 JSON 对象包含:
- 图书名称
- 作者
- 星数
- 价格
仅输出您在网页中看到的信息。

模型响应 (部分):
[
{
"name": "Warriors: A Starless Clan #6",
"author": "Erin Hunter",
"stars": null,
"price": "$14.95"
},
{
"name": "In Too Deep: A Reacher Novel",
"author": "Lee Child",
"stars": 4.7,
"price": "$16.95"
},
{
"name": "The Waiting: A Ballard and Bosch Novel",
"author": "Michael Connelly",
"stars": 4.8,
"price": "$16.95"
},
...
]
场景五:灵活的目标检测
你可以使用 Gemini 来检测图像中的目标,并为其生成边界框(Bounding Box)坐标。与专用的目标检测模型相比,Gemini 的优势在于其灵活性:当需要根据用户定义的复杂标准进行推理和查找目标时,它表现得更加出色。
提示 (Prompt) 及响应:

Gemini 会检测图像中的每个对象,并在响应中输出其边界框坐标。下图展示了利用这些坐标绘制出的边界框效果。

场景六:视频摘要与转录
Gemini 能够处理长达 90 分钟的视频,同时分析视频帧和音频轨道。利用这一功能,你可以实现:
- 生成视频的转录稿和摘要。
- 从日常场景的录像中提取结构化数据。
- 就视频内容进行问答。
- 识别并检索视频中的关键时刻。
以下是使用 Gemini 为一段技术讲座视频生成摘要笔记的示例。
提示 (Prompt):
为该视频生成能让高中生理解的技术讲座笔记。请务必遵循以下指示:
- 结合音频和每张幻灯片图像中展示的信息来撰写笔记。当用到幻灯片中的信息时,需清晰注明,并留意幻灯片上提供的图表并加以描述。
- 为讲座的各部分创建明确的章节。
- 完整地涵盖视频从始至终的全部内容。
模型响应 (部分):
# 在大型在线服务中实现快速响应时间
Jeff Dean, Google
## 简介
Web 应用的快速响应时间对于提升交互性、流畅性和用户体验至关重要。当服务需要联系大量服务器(大规模扇出)来满足用户请求时,保持应用的快速性能尤具挑战性。例如,Google 搜索结果页通常需要从数千台服务器获取信息。
...
## 延迟容忍技术
Jeff 描述了两种最小化延迟波动的技术:
### 跨请求适应
* 收集系统统计数据,如延迟率、后端性能等。
* 采取行动改善未来请求的延迟,例如通过负载均衡。
* 这类操作的时间尺度通常在几十秒到几分钟。
### 请求内适应
* 在单个高级请求内部,应对缓慢的子系统。
* 这类操作通常是即时的,在用户等待请求完成时发生。
...
场景七:从视频中提取结构化信息
Gemini 能够从视频中提取信息,并以列表、表格或 JSON 对象等结构化格式输出。这在零售、交通、家庭安保等领域用于实体检测、从屏幕录制中提取非结构化数据,或进行内容编目等任务时非常实用。

请注意:由于当前视频处理的采样率为 1 FPS(每秒一帧),模型偶尔可能会遗漏视频中的某些内容。我们正在努力为视频启用更高帧率的采样功能。因此,我们建议在必要时对这些用例的输出结果进行验证。
开始使用
想要开始基于 Gemini API 进行视觉功能开发吗?请访问我们的开发者指南以轻松上手。你也可以加入我们的开发者论坛,与其他开发者交流,讨论你的应用案例,还有机会获得来自 Gemini API 团队成员的专业指导。
关于
关注我获取更多资讯

