最近,Google 推出的 Gemini 3 Pro 模型确实令人惊艳,它拥有百万级别的超大上下文窗口,能轻松处理海量数据集、文档、视频和代码库,一次性完成复杂任务。它不仅具备博士级的推理能力,还在文本、图像、音频、视频等多模态处理上表现出色,为我们带来了流畅的创意工作流。
在这篇文章里,我将分享如何利用 Gemini 3 API 和 LangGraph 框架,构建一个多智能体应用。这个应用能根据用户提供的 CSV 数据集,自动执行深度数据分析。
概括来说,这个多智能体应用将完成以下工作:
- 基础分析:快速了解数据集的结构和基本情况。
- 代码生成:由 Gemini 3 Pro 生成高级分析代码,包括数据可视化。
- 安全执行:在沙箱环境中运行生成的代码,并保存结果。
- 智能推理:分析并解读分析结果,提炼出关键洞察。
- PDF 报告编制:生成一份精美的 PDF 报告,包含图表和清晰的解释,让核心洞察一目了然。
如果你对构建这种智能体驱动的 AI 工作流感兴趣,我个人推荐深入了解 Google 的 Antigravity 指南以及 AI Agent Fundamentals 技能路径。
1. 搭建 Gemini 3 API 环境
首先,我们需要安装所有必需的 Python 包,以便构建我们的多智能体应用:
!pip install -q google-genai langgraph langsmith grandalf pydantic pandas matplotlib markdown2 weasyprint markdown-it-py mdit-py-plugins
这些包各司其职:
google-generativeai:这是访问 Gemini 3 Pro 官方 API 的核心库。langgraph:负责编排多智能体 AI 工作流,让各智能体能够协同工作。langsmith:一个强大的工具,用于追踪运行、监控性能和调试,提供交互式的仪表盘。grandalf:能将智能体图可视化为简洁的 ASCII 图,方便我们理解工作流。pydantic:通过严谨的数据验证,管理我们共享的工作流状态。pandas:用于快速的数据集探索和分析。matplotlib:生成漂亮的数据可视化图表。markdown2:将 Markdown 文本转换为 HTML,用于丰富报告格式。weasyprint:将 HTML/CSS 转换为专业的 PDF 报告。markdown-it-py:高级 Markdown 解析器,处理复杂格式。mdit-py-plugins:扩展markdown-it-py,支持表格、脚注等功能。
注意:本次项目我是在 Jupyter Notebook 环境中进行的。
接下来,有几步关键的准备工作:
- 访问 Google AI Studio 生成你的 API 密钥。记住,Gemini 3 Pro 模型并非免费层级可用,所以确保你的账户已开通计费功能。
- 创建一个免费的 LangSmith 账户,并生成相应的 API 密钥。
- 将这两个 API 密钥作为环境变量保存在你的本地系统中,分别命名为
LANGSMITH_API_KEY和GEMINI_API_KEY。
导入必要的 Python 包:
from google import genai
from google.genai import types
from pydantic import BaseModel
from langgraph.graph import StateGraph, END
import os, json, textwrap, traceback
from pathlib import Path
import pandas as pd
import markdown2
import weasyprint
配置 LangSmith 相关的环境变量,指定项目名称并开启追踪:
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = os.environ.get("LANGSMITH_API_KEY", "YOUR_LANGSMITH_KEY")
os.environ["LANGSMITH_PROJECT"] = os.environ.get("LANGSMITH_PROJECT", "autolab-gemini3pro")
最后,创建用于保存所有图像和 PDF 报告的文件夹:
ARTIFACTS_DIR = Path("artifacts")
ARTIFACTS_DIR.mkdir(exist_ok=True)
2. 初始化 Gemini 3 API 客户端
这一步,我们要设置 Gemini API 客户端,并将对模型的调用进行封装,让它们能在 LangSmith 中被追踪和记录。同时,我们还会提取 token 使用元数据,并以 LangSmith 友好的格式返回。
首先,通过提供 API 密钥来初始化 Gemini GenAI 客户端:
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
MODEL = "gemini-3-pro-preview"
然后,我写了一个简单的包装函数 gemini_call,用于调用 Gemini 模型,并利用 @traceable 装饰器将其注册为 LangSmith 中的 LLM 运行。
在这个函数内部,代码会将提示发送给 Gemini,并提取 token 使用详情。这些细节对于 LangSmith 的准确追踪至关重要。最后,函数会返回模型的文本输出,以及 token 统计数据和原始响应,确保这些信息在 LangSmith UI 中能准确显示。
from langsmith import traceable
@traceable(name="gemini_generate_content", run_type="llm")
def gemini_call(prompt: str, thinking_level: str = "high"):
"""
Gemini wrapper that:
- uses correct ThinkingConfig schema
- returns LangSmith LLM-run format so token usage shows in UI
"""
resp = client.models.generate_content(
model=MODEL,
contents=prompt,
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level=thinking_level)
),
)
usage = getattr(resp, "usage_metadata", None)
token_usage = None
if usage:
token_usage = {
"prompt_tokens": usage.prompt_token_count,
"completion_tokens": usage.candidates_token_count,
"total_tokens": usage.total_token_count,
"thoughts_tokens": getattr(usage, "thoughts_token_count", None),
}
return {
"generations": [{"text": resp.text}],
"llm_output": {
"model_name": MODEL,
"token_usage": token_usage,
},
"raw_response": resp,
}
3. 为多智能体 Gemini 3 工作流构建工具
现在,我们将创建一些实用工具,它们能用于数据集检查、安全的 Python 代码执行,以及将 Markdown 报告转换为 PDF。这些工具是智能体工作流中的核心组件。
工具 1: 加载数据集
这个工具接收文件路径,然后使用 Pandas 将 CSV 文件读取成 DataFrame。接着,它会生成一份数据集摘要,包括数据集的形状、列名、每列的数据类型、缺失值百分比、前五行数据以及完整的描述性统计信息。这个摘要将作为输出,帮助智能体快速理解数据集。
def load_dataset(path: str):
df = pd.read_csv(path)
summary = {
"shape": df.shape,
"columns": list(df.columns),
"dtypes": {c: str(t) for c, t in df.dtypes.items()},
"missing_pct": df.isna().mean().to_dict(),
"head": df.head(5).to_dict(orient="records"),
"describe": df.describe(include="all").fillna("").to_dict()
}
return summary
工具 2: 安全运行 Python 代码 (简易沙箱)
这个工具负责在受限环境中安全地运行动态生成的 Python 代码。它会准备一个小的局部环境,然后用 exec 执行提供的代码。
期望的执行结果是代码返回工件路径(比如保存的图表)和元数据。
def run_python(code: str):
"""
Generated code MUST:
- save plots to ARTIFACTS_DIR
- collect paths in _artifacts (list[str])
- collect meta in _charts_meta (list[dict])
- optionally set _stdout (string)
"""
local_env = {"ARTIFACTS_DIR": ARTIFACTS_DIR}
try:
exec(textwrap.dedent(code), {}, local_env)
return {
"ok": True,
"stdout": local_env.get("_stdout", ""),
"artifacts": local_env.get("_artifacts", []),
"charts_meta": local_env.get("_charts_meta", []),
}
except Exception:
return {"ok": False, "traceback": traceback.format_exc()}
工具 3: 从 Markdown 渲染 PDF
这个工具能够将 Markdown 文本转换成格式优美的 PDF 文件。它首先构建一个支持表格、列表、任务列表和脚注的 Markdown 解析器。
然后,render_pdf 函数将 Markdown 文本转换为 HTML,并将其包裹在一个自定义 CSS 样式的模板中(控制字体、表格外观、图像大小等),接着使用 WeasyPrint 生成 PDF 文件。
最后,它将 PDF 保存到工件文件夹中并返回其路径。
from markdown_it import MarkdownIt
from mdit_py_plugins.tasklists import tasklists_plugin
from mdit_py_plugins.footnote import footnote_plugin
# Create a strong markdown parser once (supports tables, lists, etc.)
md = (
MarkdownIt("commonmark", {"breaks": True, "html": True})
.enable(["table", "strikethrough"])
.use(tasklists_plugin)
.use(footnote_plugin)
)
def render_pdf(markdown_text: str):
"""
Better Markdown -> HTML -> PDF:
- proper tables
- stable lists
- centered/small images
- clean page breaks
"""
html_body = md.render(markdown_text)
html_template = f"""
<html>
<head>
<meta charset="utf-8">
<style>
body {{
font-family: Arial, sans-serif;
font-size: 12px;
line-height: 1.5;
color: #111;
}}
h1 {{ font-size: 20px; margin-bottom: 6px; }}
h2 {{ font-size: 16px; margin-top: 18px; margin-bottom: 6px; }}
h3 {{ font-size: 13px; margin-top: 12px; margin-bottom: 4px; }}
p {{ margin: 6px 0; }}
ul, ol {{
margin: 6px 0 6px 18px;
}}
li {{ margin: 2px 0; }}
table {{
width: 100%;
border-collapse: collapse;
margin: 8px 0 12px 0;
font-size: 11px;
}}
th, td {{
border: 1px solid #ccc;
padding: 6px;
text-align: left;
}}
th {{ background: #f2f2f2; }}
img {{
display: block;
margin: 8px auto 8px auto;
max-width: 70%;
height: auto;
page-break-inside: avoid;
}}
.chart-block {{
page-break-inside: avoid;
margin-bottom: 12px;
}}
code {{
background: #f6f6f6;
padding: 2px 4px;
border-radius: 4px;
font-size: 11px;
}}
pre code {{
display: block;
padding: 8px;
overflow-x: auto;
}}
</style>
</head>
<body>
{html_body}
</body>
</html>
"""
pdf_path = ARTIFACTS_DIR / "report.pdf"
weasyprint.HTML(
string=html_template,
base_url=str(ARTIFACTS_DIR.parent.resolve())
).write_pdf(str(pdf_path))
return str(pdf_path)
最后,我们将这三个函数注册为智能体可用的工具。
TOOLS = [load_dataset, run_python, render_pdf]
4. 共享图状态 (Shared Graph State)
这个 State 类定义了一个共享的对象,用于存储智能体工作流产生的所有信息:例如数据集路径、分析概况、生成的计划、代码、执行结果、洞察报告和最终报告。它还包含重试限制和错误信息,以此防止可能发生的无限循环。
class State(BaseModel):
dataset_path: str
profile: dict | None = None
plan: dict | None = None
code: str | None = None
exec_result: dict | None = None
charts_meta: list | None = None
insights: str | None = None
report_md: str | None = None
report_pdf: str | None = None
retry_count: int = 0 # NEW: stop infinite loops
last_error: str | None = None # NEW: pass traceback to coder
MAX_RETRIES = 2
5. 创建用于数据分析的 Gemini 3 API 智能体
现在,我们将着手创建一系列 AI 智能体,它们将协同工作,完成数据集分析、代码编写与执行、洞察生成,并最终制作一份 PDF 报告。
智能体 1: 数据概况与规划器 (Data Profiler and Planner)
这个智能体主要负责理解数据集并制定结构化的分析计划。它首先使用 load_dataset 工具加载数据集,获取包含形状、缺失值、列类型、描述性统计信息和示例行的数据摘要。
接着,它将这份数据集摘要连同明确的指令发送给 LLM:识别任务类型、选择目标列(如果适用)、决定需要采取的探索性步骤、提议要生成的图表,并概述建模步骤(如果数据集暗示分类或回归任务)。
LLM 会返回一个 JSON 结构来表示这份计划,智能体随后解析它。如果 JSON 解析失败,则回退到存储原始文本。
最后,它将数据集概况和生成的计划都保存到共享状态中,确保后续的智能体拥有所需的全部信息。
@traceable(name="profiler_agent")
def profiler_agent(state: State):
profile = load_dataset(state.dataset_path)
prompt = f"""
You are the Data Profiler Agent.
Produce a JSON analysis plan with:
- task_type: "classification"|"regression"|"eda_only"
- target_column (if any)
- eda_steps (list)
- charts_to_make (list) # 5-10 max, most informative
- baseline_model_steps (list if modeling)
- risks_or_data_issues (list)
Dataset profile:
{json.dumps(profile, indent=2)}
"""
resp = gemini_call(prompt, thinking_level="high")
text = resp["generations"][0]["text"]
try:
plan = json.loads(text)
except:
plan = {"raw_plan": text}
state.profile = profile
state.plan = plan
return state
智能体 2: 代码编写器 (Code writer)
这个智能体负责将分析计划转化为可执行的 Python 代码。它接收数据集概况、分析计划,以及任何之前的执行错误。基于所有这些上下文,它要求 LLM 只输出 Python 代码。
提示中包含了严格的要求:加载数据集、严格遵循计划、生成所有指定的图表、将图表保存到 ARTIFACTS_DIR、追踪路径和图表元数据、捕获控制台输出、保存后关闭图表,以及(如果涉及建模)计算建模指标。
这确保了代码在沙箱中是可重现且安全的。生成的结果存储在 state.code 中,等待执行器运行。
@traceable(name="code_writer_agent")
def code_writer_agent(state: State):
prompt = f"""
You are the Code Writer Agent.
Write Python code ONLY (no markdown).
Previous error to fix (if any):
{state.last_error}
HARD REQUIREMENTS:
1. Load dataset from: {state.dataset_path}
2. Follow the plan exactly.
3. Create ALL charts in charts_to_make.
4. Save every chart in ARTIFACTS_DIR with filenames like:
ARTIFACTS_DIR / "chart_01_<short_name>.png"
5. Track saved plot paths in _artifacts (list[str]).
6. Track chart metadata in _charts_meta (list[dict]) with:
{{
"title": "<human readable chart title>",
"filename": "artifacts/chart_01_x.png",
"description": "<what this plot shows (1-2 sentences)>",
"one_liner": "<ONE line insight from the chart>"
}}
The one_liner MUST be a single sentence, max ~20 words.
7. Store useful console output in _stdout.
IMPORTANT:
- import matplotlib.pyplot as plt
- plt.close() after saving each plot
- ensure _artifacts and _charts_meta exist even if empty
- if modeling, add baseline metrics to _stdout
Dataset profile:
{json.dumps(state.profile, indent=2)}
Analysis plan:
{json.dumps(state.plan, indent=2)}
Return ONLY executable python code.
"""
resp = gemini_call(prompt, thinking_level="high")
state.code = resp["generations"][0]["text"]
return state
智能体 3: 执行器 (带自动重试) (Executor with auto-retry)
这个智能体使用隔离的 run_python 沙箱运行由代码编写器生成的 Python 代码。它会捕获执行结果、图表元数据、标准输出以及任何生成的工件。
如果代码成功运行,结果会被存储,工作流正常推进。如果失败,智能体则增加重试计数器,并存储堆栈跟踪信息,以便代码编写器在下一次尝试时修复错误。
通过 MAX_RETRIES 来限制循环次数,这个智能体可以避免无限循环,并提供必要的反馈信号,以实现自我修正。
@traceable(name="executor_agent")
def executor_agent(state: State):
result = run_python(state.code)
state.exec_result = result
state.charts_meta = result.get("charts_meta", [])
if not result["ok"]:
state.retry_count += 1
state.last_error = result.get("traceback", "Unknown error")
return state
智能体 4: 洞察编写器 (Insights writer)
这个智能体负责解释整个分析结果。它接收数据集概况、执行输出和图表元数据,然后生成人类可读的分析洞察。
它会指示 LLM 生成结构化的洞察:对于每个图表,产生两个要点和一个潜在风险,然后生成一组有限的总体洞察。
这个智能体必须确保没有空的项目,没有重复的观点,并且洞察必须具体到当前数据集,而非泛泛而谈。
最终的洞察报告存储在 state.insights 中,成为最终报告阶段的输入。
@traceable(name="insights_agent")
def insights_agent(state: State):
prompt = f"""
You are the Insights Agent.
HARD REQUIREMENTS:
- No empty bullets.
- No repeated bullets.
- Be specific to this dataset and these charts.
- Output format:
### Chart Insights
For each chart in charts_meta:
- **<title>**
- Takeaway 1 (one sentence)
- Takeaway 2 (one sentence)
- Caveat/Risk (one sentence)
### Overall Insights
- 3-5 bullets max, each one sentence.
Inputs:
Profile:
{json.dumps(state.profile, indent=2)}
Execution result:
{json.dumps(state.exec_result, indent=2)}
Charts meta:
{json.dumps(state.charts_meta, indent=2)}
"""
resp = gemini_call(prompt, thinking_level="high")
state.insights = resp["generations"][0]["text"]
return state
智能体 5: 报告生成器 → PDF (Report builder → PDF)
这是最终的合成智能体。它利用管道的全部输出:概况、洞察、图表元数据、执行日志,精心制作一份完整、清晰的 Markdown 报告。
提示中强制执行严格的格式规则:不重复标题、保持一致的间距、每个图表以标准化的 HTML 块形式精确显示一次、并且将洞察信息清晰地整合进去。
一旦 Markdown 生成完毕,智能体就会调用 render_pdf 工具,使用 WeasyPrint 将其转换为精美的 PDF。Markdown 文本和 PDF 路径都存储在共享状态中,从而完成了整个分析工作流。
@traceable(name="report_agent")
def report_agent(state: State):
prompt = f"""
You are the Report Agent.
Create a neat Markdown report (HTML allowed).
HARD REQUIREMENTS:
- Do NOT repeat section titles or chart titles.
- Do NOT output empty bullet points. If a bullet would be empty, skip it.
- Keep spacing consistent: one blank line between sections.
- Use charts_meta as the ONLY source of charts.
- Include EVERY chart, exactly once, in the same order as charts_meta.
- For each chart output EXACTLY this block:
<div class="chart-block">
<h3>Chart {{i}}: {{title}}</h3>
<img src="{{filename}}" alt="{{title}}">
<p><b>What it shows:</b> {{one_liner}}</p>
</div>
Where:
- title, filename, one_liner come from charts_meta
- one_liner must be ONE sentence, max ~20 words.
Sections:
1. Dataset Overview (short)
2. Data Quality Notes (bullets)
3. Exploratory Analysis (chart-by-chart blocks only, no extra chart titles)
4. Modeling Results (if any; use a markdown table)
5. Key Insights (use insights text)
6. Recommendations / Next Steps (bullets)
Inputs:
Profile: {json.dumps(state.profile, indent=2)}
Exec stdout: {state.exec_result.get("stdout","")}
Exec ok: {state.exec_result.get("ok")}
Traceback (if any): {state.exec_result.get("traceback","")}
Charts meta:
{json.dumps(state.charts_meta, indent=2)}
Insights:
{state.insights}
Return ONLY the Markdown report.
"""
resp = gemini_call(prompt, thinking_level="low")
state.report_md = resp["generations"][0]["text"]
state.report_pdf = render_pdf(state.report_md)
return state
6. 构建多智能体图 (Multi-Agent Graph)
最后一步,我们要将所有智能体组合成一个状态驱动的图,构建出完整的多智能体工作流。我们使用一个共享的 State 模型来创建 StateGraph,确保每个智能体在工作流推进过程中都能与同一个不断演变的状态对象进行交互。各个组件,如概况分析器、代码编写器、执行器、洞察编写器和报告生成器,都被添加为图中的独立节点,代表管道中的特定阶段。
工作流总是从概况分析器智能体开始,它被指定为入口点。这保证了整个过程始于对数据集的全面理解和分析计划的生成。
接下来,我们建立边来定义流程。在概况分析之后,输出会导向代码编写器,然后代码编写器再将结果传递给执行器。这里的关键逻辑在于执行器之后的条件路由。
一个辅助函数 retry_or_continue 会检查执行结果。如果代码成功执行,工作流将继续流向洞察智能体。如果执行失败但仍有重试次数,它会循环回代码编写器进行自动修正。
如果已经没有重试次数了,它会绕过进一步的分析,直接进入报告生成器,这样可以防止系统陷入无休止的循环。这些条件边被整合到执行器节点中,使得工作流能够根据执行的成功或失败进行自适应调整。
最终,图将洞察阶段连接到报告阶段,再从报告阶段连接到工作流的终点。整个图被编译成一个可执行的结构,并生成一个 ASCII 图表来可视化流程。
这个多智能体图精心编排了整个自适应分析管道,实现了错误恢复、分步协调以及智能体间的平滑过渡。
g = StateGraph(State)
g.add_node("profiler", profiler_agent)
g.add_node("code_writer", code_writer_agent)
g.add_node("executor", executor_agent)
g.add_node("insights", insights_agent)
g.add_node("report", report_agent)
g.set_entry_point("profiler")
g.add_edge("profiler", "code_writer")
g.add_edge("code_writer", "executor")
def retry_or_continue(state: State):
# success path
if state.exec_result and state.exec_result.get("ok"):
return "insights"
# stop retrying after MAX_RETRIES
if state.retry_count >= MAX_RETRIES:
return "report"
return "code_writer"
g.add_conditional_edges(
"executor",
retry_or_continue,
{"code_writer": "code_writer", "insights": "insights", "report": "report"}
)
g.add_edge("insights", "report")
g.add_edge("report", END)
graph = g.compile()
print(graph.get_graph().draw_ascii())
这段代码会打印出类似下面的 ASCII 图,直观展示了智能体之间如何进行流转:
+-----------+
| __start__ |
+-----------+
*
*
*
+-----------+
| profiler |
+-----------+
*
*
*
+-------------+
| code_writer |
+-------------+
.
.
.
+-----------+
| executor |
+-----------+
.. ..
.. ..
. ..
+-----------+ .
| insights | ..
+-----------+ ..
** ..
** ..
* .
+--------+
| report |
+--------+
*
*
*
+---------+
| __end__ |
+---------+
7. 运行完整的 Gemini 3 API 数据分析管道
要运行完整的管道,你只需提供数据集路径,创建一个初始的 State 对象,然后调用编译好的图。这里,我们以 Boston Housing 数据集为例。
DATASET_PATH = "/work/housing.csv" # <-- change this
state = State(dataset_path=DATASET_PATH)
out = graph.invoke(state)
一旦被调用,这个多智能体系统就会自动执行完整的分析:分析数据集概况、生成计划、编写并执行 Python 代码、提取洞察,并生成 Markdown 和 PDF 两种格式的报告。
你会看到类似这样的输出:
--- Modeling Baseline Results ---
Dataset Shape: (489, 4)
Linear Regression -> RMSE: 82,395.54, R2: 0.6911
Random Forest -> RMSE: 56,931.38, R2: 0.8525
Observations: Random Forest typically outperforms Linear Regression due to capturing non-linear relationships (e.g., LSTAT).
运行完成后,你可以打开 LangSmith 仪表盘,导航到“autolab-gemini3pro”项目。每一次智能体运行都会在那里显示。
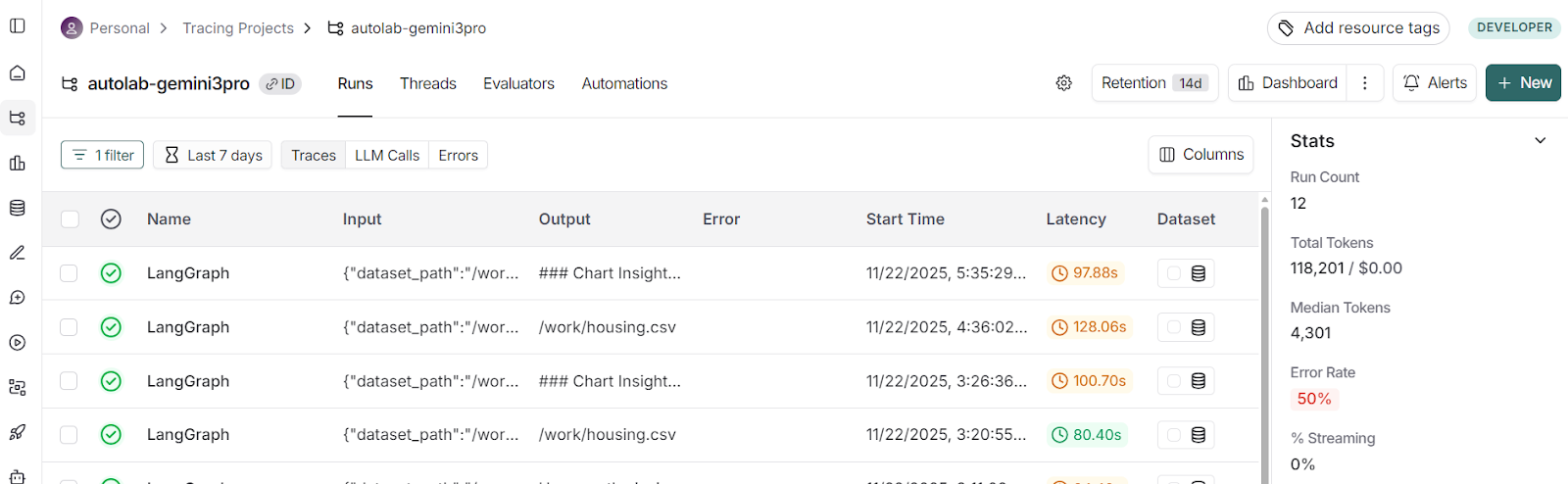
点击最近的一次运行,切换到“Waterfall”视图,会显示每一步的时间线:智能体花了多长时间以及使用了哪些工具。

你可以点击任何智能体来检查其详细信息:
- 它收到的提示
- 模型的准确生成内容
- 工具执行详情
- 返回的工件、图表和追踪记录
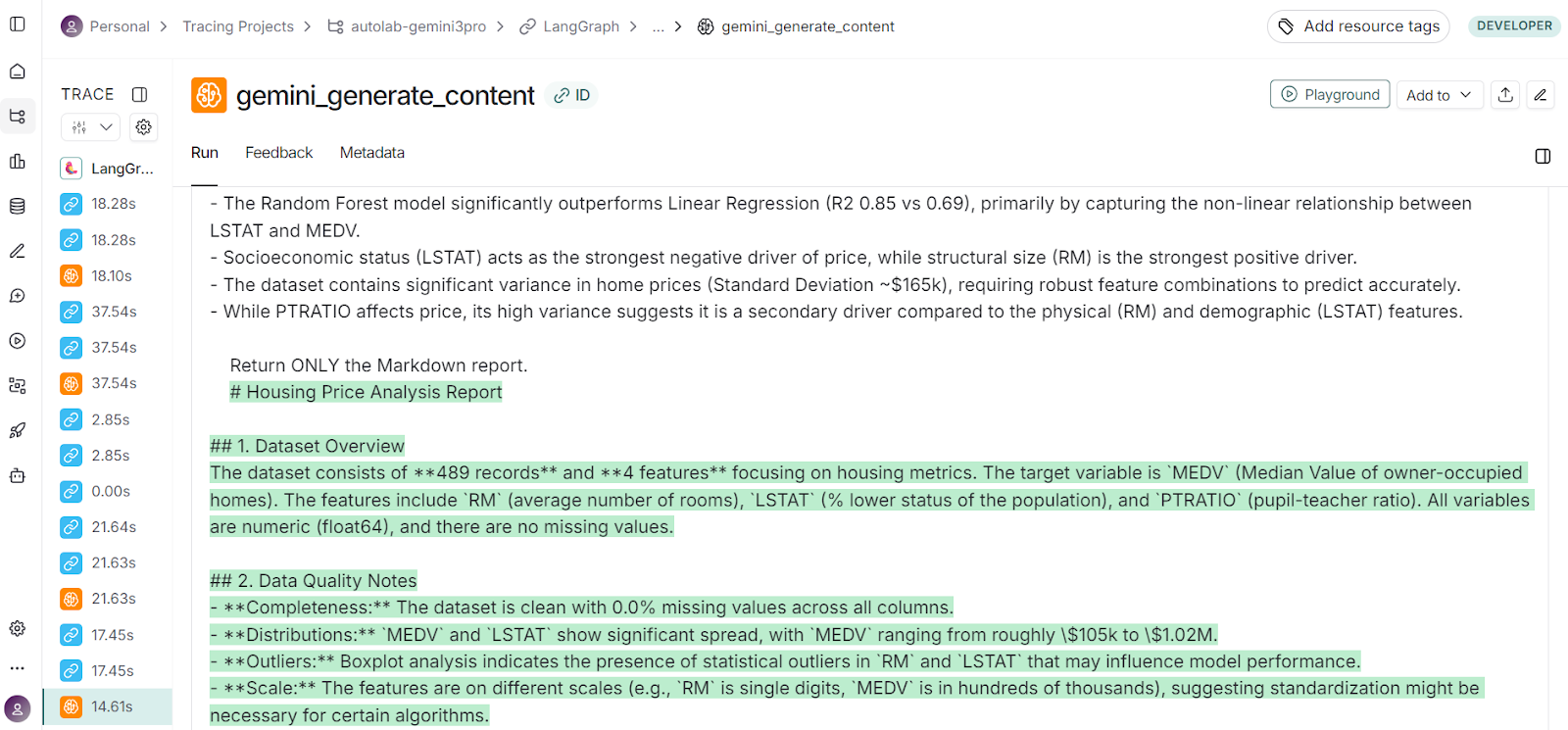
在我看来,LangSmith 在整个工作流的改进中起到了关键作用。你现在看到的是最终版本,但要让这个项目完美运行,我着实尝试了好多次,而 LangSmith 正是帮助我调试智能体问题的得力助手。
8. 显示报告 Markdown 和 PDF
多智能体工作流完成后,你可以在 Jupyter Notebook 中直接查看生成的 Markdown 报告。
Markdown 版本对于快速审阅分析、阅读洞察和检查报告结构非常有用,而且无需离开你的工作区。
print(out["report_md"][:2000])
你会看到报告的初步 Markdown 内容:
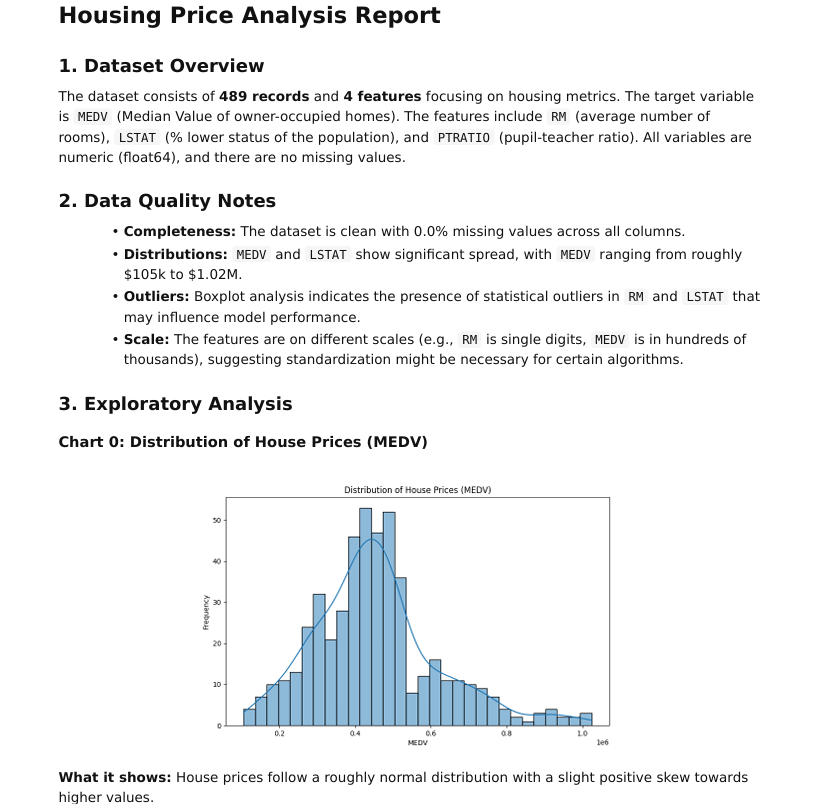
# Housing Price Analysis Report
## 1. Dataset Overview
The dataset consists of **489** records and **4** features focusing on housing metrics. The target variable is `MEDV` (Median Value of owner-occupied homes). The features include `RM` (average number of rooms), `LSTAT.................`
除了 Markdown,工作流还会生成一份精美的 PDF 报告。PDF 会自动保存在 artifacts 文件夹中,你可以通过以下方式查看其路径:
print("PDF saved at:", out["report_pdf"])
输出会显示 PDF 的保存路径:
PDF saved at: artifacts/report.pdf
生成的 PDF 报告非常完善,包含了分析的所有关键组成部分:叙述性解释、视觉渲染的图表、图表解读、建模总结以及最终建议。
这使得它非常适合与团队成员、主管或客户分享,尤其是在你需要一份整洁、可直接演示的报告时。
总结思考
在完成这个项目的过程中,我真真切切感受到了现代 AI 模型和基于图的智能体工作流发展到了何等程度。就在不久前,哪怕是构建一个带有多个工具的单一智能体,也需要耗费数天时间进行调优、调试,还得应对各种不可预测的行为。
如今,有了像 Gemini 3 Pro 这样的模型,整个系统能够理解数据集、生成精确的代码、执行分析、解读可视化结果,并以惊人的可靠性组装出精美的报告。
在这个项目中,我们构建了一个完整的、多智能体的数据分析应用。它能够接收任何 CSV 数据集,执行端到端的探索性分析,运行基线模型,生成洞察,并制作一份格式完整的 PDF 报告。
这个项目由五个协同工作的智能体组成:概况与规划、代码生成、带重试机制的执行、洞察生成和报告制作。同时,它依赖三个核心工具:数据集加载、安全代码执行和Markdown 到 PDF 渲染。
最终的结果是一个清晰、自动化的分析流程,能够产出专业、叙述性强且辅以可视化的报告。这无疑为数据分析领域带来了效率和可能性的大幅提升。
Gemini 3 API 常见问题
Gemini 3 API 的上下文窗口大小是多少?
Gemini 3 API 支持高达约一百万个 token 的上下文窗口,使其能够单次处理大型数据集、长篇文档或完整的代码库。我们仍建议监控 token 使用情况,以便控制成本并避免截断。
thinking_level 参数如何影响 Gemini 3 API 的性能?
thinking_level 参数控制 Gemini 3 API 中推理深度与速度和成本之间的权衡。将其设置为 high 会触发更彻底的推理(适用于复杂工作流),而设置为 low 则优先考虑更快的响应和更低的 token 消耗。
Gemini 3 API 的定价和速率限制详情是怎样的?
Gemini 3 Pro 采用基于 token 的计费方式:你需为输入和输出 token 付费。更大的提示或多模态输入会增加 token 计数,从而提高成本。速率限制因账户层级而异,因此在生产环境中,追踪使用情况并设置警报至关重要。
Gemini 3 API 支持哪些输入格式?
Gemini 3 API 支持多种输入格式——文本、图像、音频和视频——实现了真正的多模态推理。你可以混合使用多种格式(例如,一个数据集加上一张图表图像),但非文本输入通常会消耗更多 token,因此需相应规划。
Gemini 3 API 的主要限制有哪些,我应该如何管理它们?
尽管 Gemini 3 API 功能非常强大,但它仍面临实际限制:大上下文可能会增加延迟和成本,并且模型输出可能需要人工验证。在进行合规性检查之前,不应发送敏感数据;生成的代码或分析在部署之前都应该进行沙箱验证的的。
关于
关注我获取更多资讯

