生活节奏快,每天早上出门前都在为穿什么而发愁?想尝试新的搭配风格,却苦于没有灵感,或者不想一件件试穿?别担心,今天我要和大家聊一个非常有趣又实用的项目:如何利用最前沿的 FLUX.2-dev 模型,结合 Gradio 快速搭建一个“AI 胶囊衣橱可视化工具”。
这个工具的魔力在于,你只需上传 2 到 10 张你衣橱里的单品照片(比如衬衫、裤子、外套、鞋子),模型就会智能地采样这些单品,组合出各种混搭风格的穿搭,并以清晰的网格形式呈现给你。最终,你将得到一个交互式应用,它能让你直观地探索服装搭配的无限可能,而且整个过程由一个对 GPU 内存非常友好的扩散模型驱动。
如果你对图像深度学习背后的原理感到好奇,我个人非常推荐去学习像 PyTorch 图像深度学习这类课程,它能帮助你打下坚实的基础。
FLUX.2 是什么?
FLUX.2 并非一个单一的、庞大的模型,而是一个为兼顾图像生成质量、速度和灵活性而优化的模型家族。它引入了几项至关重要的能力,在我看来,这正是它能在当前众多文生图模型中脱颖而出得关键所在。
- 多图像引用支持:这是一个游戏规则的改变者。FLUX.2 最多可以同时以 10 张图像作为参考进行条件生成。这对于确保跨多代生成内容的产品一致性,尤其在电商或设计领域,简直太重要了。
- 图像细节与照片级真实感:相较于前代版本,FLUX.2 在精细细节和真实感方面有了显著飞跃,我甚至觉得它已经快要模糊真实照片与生成图像的界限了。
- 文本渲染能力:FLUX.2 的 Pro 和 Flex 版本特别擅长处理复杂的字体、信息图表和 UI 界面设计,这在过去是很多文生图模型的痛点。
- 增强的提示词遵循能力:模型能更好地理解并遵循结构化、多部分的提示词,当我们描述特定的姿势、光照和造型时,这种能力尤其有用。
- 世界知识与空间逻辑:FLUX.2 对现实世界中的物体、光照和构图有着更扎实的理解,这使得它生成的场景更具连贯性和逻辑性。
实际应用中,你通常会接触到 FLUX.2 的三个核心变体:

- FLUX.2-Pro:这是最高保真度的模型,速度相对较慢,但特别适合那些对图像渲染品质要求极高、而非追求快速迭代的生产级应用。
- FLUX.2-Flex:一个平衡的预设版本,在保证不错质量的同时,兼顾了延迟和显存占用。它是一个很棒的通用图像生成选项。
- FLUX.2-Dev:这是实验性版本,更方便开发者在代码层面进行调整和把玩,非常适合进行演示和原型开发。
相比于 Pro 和 Flex,Dev 版本就是为那些喜欢亲手实践和探索的人准备的,而这,也正是我们构建交互式胶囊衣橱所需要的。
为何选择 FLUX.2-Dev (4位量化)?
原生的 FLUX.2 系列已经足够强大,但结合 FLUX.2-Dev 与 4 位(bit)量化技术,我们的这个演示项目将变得更易于运行、迭代和扩展。以下是我认为选择它的几个关键理由:
- 专为实验而生: Dev 版本能够直接与我们自定义的 Python 逻辑、多图像条件生成以及 Gradio UI 无缝衔接,无需过多额外的代码。这在快速原型开发时,可是大大地节省时间。
- 显存轻松管理: 4 位量化将模型参数的显存占用,与 FP16/BF16 相比,足足减少了大约 3 到 4 倍。这意味着我们可以在一张 A100 GPU 上,轻松运行:
- 3×3 的图像批次。
- 20-30 个扩散步。
- 像 512×384 到 768×512 这样的中高分辨率。
- 而不会遇到恼人的显存溢出(OOM)错误。
- 快速迭代效率: 因为模型更轻量,我们得以反复调整种子、扩散步数、引导比例、网格大小和分辨率,并快速重新生成衣橱搭配网格。这对于找到最佳效果的参数组合至关重要。
- 交互式网格的优秀质量: 即使是 Dev 版本,模型也展示了生成影棚级时尚照片的能力,保持了光照一致性和逼真的织物细节。这正是我们 3×3 穿搭网格所追求的,而非仅仅一张精美的主图。当然了,实际效果会因你的参考图和提示词有所不同,要得到高质量输出,往往还需要细心进行提示工程、精心挑选参考图像(保持一致的光照、角度和背景),甚至可能需要后期过滤。
简而言之,FLUX.2-Dev (4位量化) 为我们提供了一个在显存、速度和质量之间取得完美平衡的组合,是构建交互式胶囊衣橱工具的理想选择。
FLUX.2 演示概览:胶囊衣橱可视化工具
这一部分,我们将动手实现一个基于 FLUX.2 模型,并用 Gradio 应用封装起来的胶囊衣橱可视化工具。从宏观上看,这个应用主要完成三件事:
- 接收多张衣物图片作为参考。
- 构建一个结构化的提示词,引导 FLUX.2-dev 生成包含这些特定单品的全套时尚穿搭照。
- 通过随机组合每块“瓦片”中的衣物,生成一个穿搭网格,你可以调整网格大小(行 × 列)、扩散步数和引导比例。
下面的视频展示了整个工作流程的一个简化版本。(实际生成过程可能需要几分钟,视频已加速处理以作演示)。
第 1 步:环境配置
首先,我们需要安装最新版本的 diffusers 库,它能直接从 GitHub 获取,还有其他一些必要的依赖项。
!pip install -q "git+https://github.com/huggingface/diffusers.git@main" \
"transformers>=4.44.0" accelerate safetensors bitsandbytes gradio pillow
接着,我们需要登录 Hugging Face,这样才能拉取 4 位量化的 FLUX.2-dev 模型权重。
from huggingface_hub import login
login()
当系统提示时,输入你的 Hugging Face Token 并登录。登录成功后,快速检查一下 CUDA 是否可用以及正在使用哪块 GPU。
import torch, diffusers, bitsandbytes as bnb
print("diffusers:", diffusers.__version__)
print("CUDA available:", torch.cuda.is_available())
!nvidia-smi
如果你在 nvidia-smi 的输出中看到了你的 GPU,并且 CUDA available: True,那就说明一切准备就绪,可以继续了。
第 2 步:加载 FLUX.2-dev (4位量化) 模型
现在,我们从 diffusers/FLUX.2-dev-bnb-4bit 仓库加载 4 位量化的 FLUX.2-dev 组件。
from diffusers import Flux2Pipeline, Flux2Transformer2DModel
from transformers import Mistral3ForConditionalGeneration
import torch
bnb_repo = "diffusers/FLUX.2-dev-bnb-4bit"
torch_dtype = torch.bfloat16
device = "cuda"
print("Loading 4-bit transformer...")
transformer = Flux2Transformer2DModel.from_pretrained(
bnb_repo,
subfolder="transformer",
torch_dtype=torch_dtype,
device_map="auto",
)
print("Loading 4-bit text encoder...")
text_encoder = Mistral3ForConditionalGeneration.from_pretrained(
bnb_repo,
subfolder="text_encoder",
torch_dtype=torch_dtype,
device_map="auto",
)
print("Building Flux2 pipeline...")
pipe = Flux2Pipeline.from_pretrained(
bnb_repo,
transformer=transformer,
text_encoder=text_encoder,
torch_dtype=torch_dtype,
).to(device)
pipe.set_progress_bar_config(disable=False)
print("Loaded. Example param device:", next(pipe.transformer.parameters()).device)
一旦所有依赖都安装好,我们就能使用 diffusers 库来加载 FLUX.2,并将其与 transformers 库中的 Mistral 3 文本编码器配对。这里有几个核心组件值得我们注意:
Flux2Transformer2DModel:这是核心的、类似 U-Net 的 Transformer,负责图像的去噪过程,这里我们加载的是它的 4 位量化版本。Mistral3ForConditionalGeneration:这个模型作为文本编码器,它的作用是将你的文字提示转化为扩散过程所需的条件信号。Flux2Pipeline:它将 Transformer、文本编码器以及其他支持组件整合到一个单一的、可调用的接口中,简化了图像生成过程。
在我看来,使用 device_map="auto" 和 torch_dtype=torch.bfloat16 是一个很聪明的做法。它既能让我们在不同的 GPU 配置下保持灵活性,又能有效地控制显存占用,一举两得。
第 3 步:图像预处理
我们的应用允许用户上传多张衣橱图片。为此,我们需要一些实用工具来完成两个任务:
- 将 Gradio 返回的文件对象转换为 PIL 图像。
- 将它们缩放到一个适合作为条件输入的尺寸。
import gradio as gr
import random, json
from typing import List, Union
from PIL import Image
MAX_REFS = 10
def files_to_pil(files: List[Union[str, dict]]) -> List[Image.Image]:
images = []
for f in files:
path = f.get("name") if isinstance(f, dict) else f
if not path:
continue
img = Image.open(path).convert("RGB")
images.append(img)
return images
def preprocess_refs(refs: List[Image.Image], max_size: int = 512) -> List[Image.Image]:
processed = []
for img in refs:
img = img.convert("RGB")
img.thumbnail((max_size, max_size), Image.LANCZOS)
processed.append(img)
return processed
上面这段代码定义了两个关键的辅助函数。
files_to_pil()函数会接收 Gradio 返回的文件对象,从中提取文件路径,并将每个文件作为 RGB 格式的PIL.Image打开。preprocess_refs()函数则负责将这些图像重新调整大小,确保它们的最大边不超过 512 像素,同时保持宽高比。这对于兼顾生成速度和显存使用都是非常重要的考量。
此外,我们还通过 MAX_REFS = 10 对参考图像的数量设了个上限,避免一次性传入过多图片导致条件集过载。
第 4 步:构建穿搭提示词
我们不只是简单地发送一个扁平的文本提示词,而我们构建了一个结构化、类似 JSON 的提示词,它详细描述了:
- 摄影棚的布景
- 模特和她的姿态
- 搭配的衣物单品(与参考图像关联)
- 光照、氛围和相机信息
def build_outfit_prompt(outfit_indices: List[int], labels: List[str]) -> str:
item_phrases = [
f"wardrobe piece {labels[idx]} from reference image {idx+1}" for idx in outfit_indices
]
outfit_items_str = ", ".join(item_phrases)
mistral_prompt = """A professional full-body studio photograph of a high-end fashion editorial shoot, set against a flawless seamless neutral gray backdrop (#f5f5f5) in a controlled studio environment. The scene is bathed in soft, diffused three-point lighting (key, fill, and subtle rim) that eliminates harsh shadows, ensuring even illumination across the subject while preserving dimensionality and texture.
At the center of the frame stands a full-body adult model, exuding quiet confidence in a relaxed yet poised stance—one foot slightly forward, weight balanced, body angled subtly to the right. The model’s expression is natural, with a neutral gaze directed just off-camera, evoking a modern, minimalist lookbook aesthetic.
The outfit—meticulously styled and tailored—is the focal point, captured with ultra-realistic 8K resolution and razor-sharp detail. Fabrics display tactile depth: the weave of knits, the drape of silks, the sheen of leathers, and the crispness of cotton are all rendered with commercial-grade precision. The shallow depth of field (50mm prime lens, f/2.8) keeps the subject in crystalline focus while softly blurring the backdrop, emphasizing the outfit’s textures and proportions.
The composition adheres to classic fashion photography rules: vertical framing, ample headroom, and a slightly dynamic angle (eye-level) that flatters the model’s posture. The color palette is controlled and sophisticated, dominated by the outfit’s hues against the neutral gray, with subtle tonal contrasts to highlight layers and accessories.
Every element—from the studio-quality lighting to the catalog-ready styling—conveys luxury, clarity, and commercial appeal, designed to showcase the outfit as a covetable, high-end ensemble."""
prompt_dict = {
"scene": mistral_prompt,
"subjects": [
{
"description": (
"The model is styled in an outfit composed of: "
+ outfit_items_str
+ ". Each garment should closely match the color, fabric, and key design details of its reference image."
)
}
]
}
return json.dumps(prompt_dict)
build_outfit_prompt() 函数在这里完成了三件重要的事情:
- 首先,它利用
outfit_indices和labels来生成诸如“来自参考图像 1 的衣橱单品 1”这样的短语,并将它们拼接成一个字符串,描述这套特定穿搭中选定的服装。 - 其次,它将这些服装信息嵌入到一个自然语言的
mistral_prompt中,这个长提示词精心定义了影棚环境、灯光设置、相机镜头、景深等等。 - 最后,我们将所有信息封装到一个包含
scene和subjects字段的prompt_dict字典中,然后将其序列化为 JSON 字符串,作为单一提示词传递给扩散管道。
从概念上讲,我们把每一张上传的衣橱图片都视为一个“衣橱单品 i”,并要求模型“使用衣橱单品 1、衣橱单品 3 和衣橱单品 4 组合一套穿搭”,同时要尽可能保留每个单品的颜色、面料和关键设计细节。我个人觉得这种方式比直接用一句话描述要精确的多。
注意:由于我们的管道中使用了 Mistral 模型作为文本编码器,我甚至用 Mistral 来协助起草了这个长长的影棚描述提示词(即 mistral_prompt),通过 Meta-prompting 的方式。这样做的好处是,可以保持提示词的风格与编码器“预期”的风格保持一致,并且方便我们在代码中直接调整措辞。
第 5 步:生成衣橱网格
这个演示的核心功能体现在 capsule_fn 函数中,它负责:
- 接收用户上传的图片和 UI 参数。
- 为网格中的每个“瓦片”随机选择衣橱单品的子集。
- 调用 FLUX.2-dev 管道生成多张图片。
- 最后,将所有图片组合成一个单一的网格。
def make_grid(images: List[Image.Image], rows: int, cols: int) -> Image.Image:
w, h = images[0].size
grid = Image.new("RGB", (cols * w, rows * h), (255, 255, 255))
for idx, img in enumerate(images):
r, c = divmod(idx, cols)
grid.paste(img, (c * w, r * h))
return grid
def capsule_fn(files, rows, cols, height, width, steps, guidance, seed):
if not files or len(files) < 2:
return None
images = files_to_pil(files)
images = images[:MAX_REFS]
refs = preprocess_refs(images, max_size=512)
labels = [f"wardrobe piece {i+1}" for i in range(len(refs))]
random.seed(int(seed))
tiles = []
num_tiles = rows * cols
for i in range(num_tiles):
k = min(len(refs), random.randint(2, 3))
outfit_idxs = random.sample(range(len(refs)), k=k)
prompt = build_outfit_prompt(outfit_idxs, labels)
generator = torch.Generator(device=device).manual_seed(int(seed) + i)
out = pipe(
prompt=prompt,
image=refs,
height=height,
width=width,
num_inference_steps=steps,
guidance_scale=guidance,
generator=generator,
)
tiles.append(out.images[0])
grid = make_grid(tiles, rows, cols)
return grid
上面这两个函数构成了胶囊衣橱演示的核心引擎。
make_grid()函数会创建一个足够大的空白画布来容纳rows × cols的布局,然后将每张生成的穿搭图片粘贴到正确的位置,最终生成一张完整的网格图像。capsule_fn()函数则负责将用户的衣橱图片作为参考进行预处理,为每个瓦片随机挑选 2 到 3 件单品,构建结构化的穿搭提示词,并调用 FLUX.2 管道,使用选定的分辨率、步数、引导比例和种子进行生成。它会收集所有生成的瓦片,并将其传递给make_grid()函数,这样用户就能看到一个由混搭穿搭组成的最终网格。
第 6 步:Gradio UI 界面
这一步是将胶囊衣橱的核心引擎与 Gradio 应用连接起来。用户通过界面上传衣橱图片,选择网格和生成设置,最终获得一个组合好的穿搭网格。
inputs = [
gr.File(file_types=["image"], file_count="multiple", label="Wardrobe pieces (2–10 images)"),
gr.Slider(1, 4, value=2, step=1, label="Grid rows"),
gr.Slider(1, 4, value=2, step=1, label="Grid cols"),
gr.Slider(384, 896, value=512, step=64, label="Image height"),
gr.Slider(256, 640, value=384, step=64, label="Image width"),
gr.Slider(10, 30, value=16, step=2, label="Diffusion steps"),
gr.Slider(1.0, 7.0, value=2.5, step=0.5, label="Guidance scale"),
gr.Number(value=42, precision=0, label="Seed")
]
iface = gr.Interface(
fn=capsule_fn,
inputs=inputs,
outputs=gr.Image(type="pil", label="Capsule wardrobe grid"),
title="Capsule Wardrobe Visualizer – FLUX.2-dev (4-bit)",
description="Upload 2–10 product images; mix & match outfits using FLUX.2-dev with multi-image reference.",
)
iface.launch(share=True, debug = True)
我们构建 Gradio 应用的过程如下:
inputs列表定义了应用所有的交互式控件。其中“Wardrobe pieces”是一个多文件上传组件,用于上传 2 到 10 张服装或产品图片,而“Grid rows”和“Grid cols”滑块则设置了网格的形状,进而决定了每批生成多少套穿搭。- “Image height”和“Image width”滑块控制着每个瓦片的分辨率,更高分辨率当然会消耗更多的显存和时间。
- “Diffusion steps”滑块决定了模型运行多少步去噪过程(通常 16-24 步是一个不错的默认值),而“Guidance scale”则控制着模型在多大程度上遵循文本提示词,又在多大程度上依赖参考图。
gr.Interface调用将这些输入与capsule_fn函数连接起来,并声明了一个gr.Image类型的输出。最后的launch(share=True, debug=True)调用会启动 Gradio 服务器,生成一个可公开分享的链接用于演示,并在控制台启用调试日志,方便我们诊断问题。
界面启动后,你可以这样操作:
- 上传一小部分衣物单品(比如 2 件衬衫、2 条裤子、1 件外套、1 双鞋)。
- 选择一个 3x3 或 2x2 的网格,分辨率设为 512x384,步数大约 20 步,引导比例设为 2.5。
- 点击 Submit,然后看着网格被填充上编辑风格的图片。
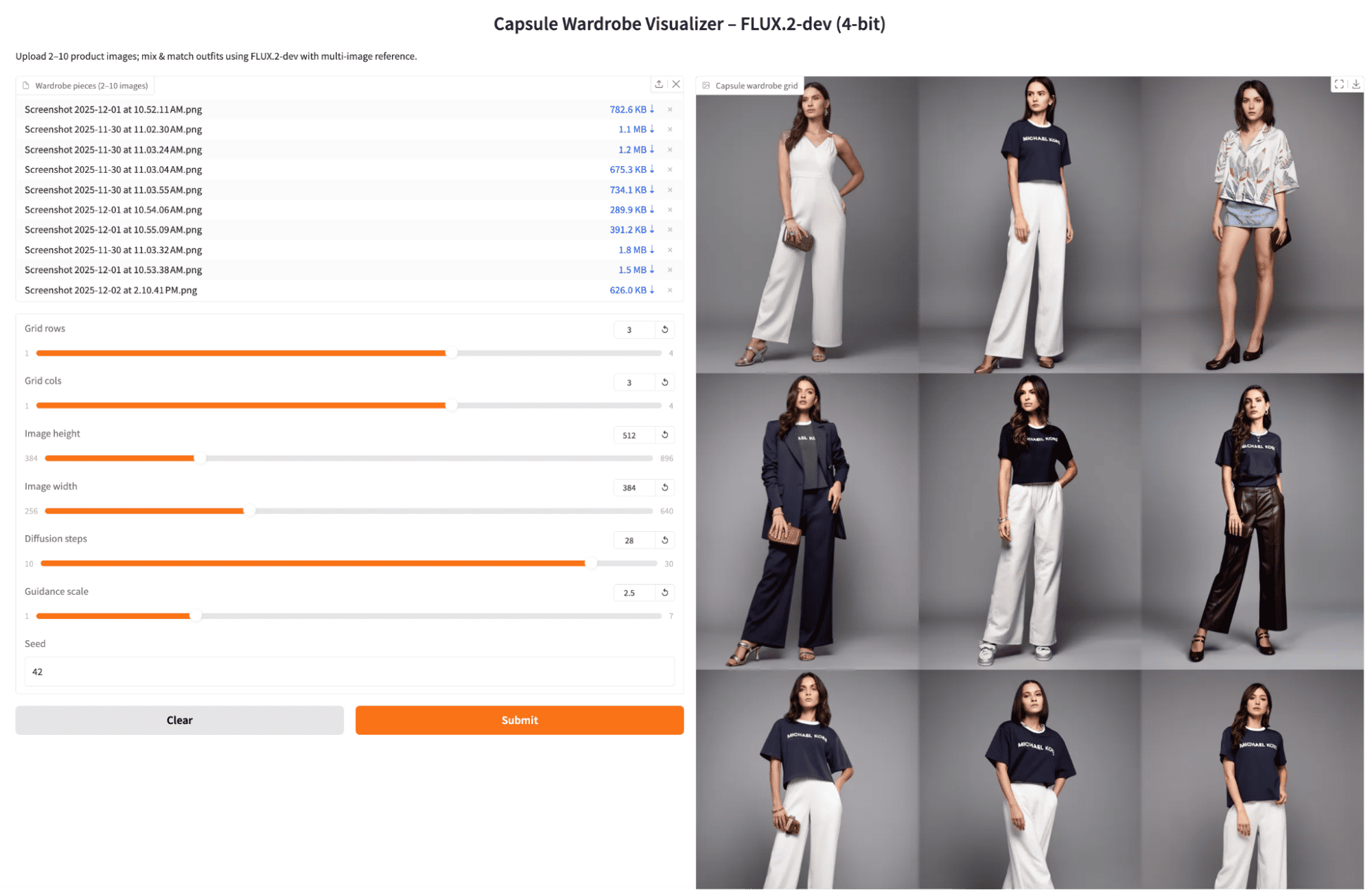
FLUX.2 示例与观察
为了更好地理解 FLUX.2-dev 在实际应用中的表现,我用最终的应用跑了几组小实验。我调整了扩散步数和引导比例,也尝试了同件衣服的多角度图片,以及每件独一无二的衣服只给一张图片这两种情况,目的就是看看模型能产生多少种搭配变化。
- 扩散步数和引导比例主要影响速度和锐度,对显存影响不大。将扩散步数从 28 增加到 30,引导比例从 2.5 提升到 5.0,显存占用基本保持不变,但每批次生成会稍微慢一点,不过生成的穿搭会更清晰。当然,理论上,如果把步数设得很高(比如 50 步),网格的整体观感会有明显改变,并且延迟也会更高,同时能获得更高质量的输出。
- 在 A100 上,4 位量化模型表现得相当舒适。使用 4 位量化的 FLUX.2-dev 模型,在 512x384 分辨率下生成 3x3 的网格,大约 20-28 步,运行起来感觉既快又安全,非常适合单 GPU 的演示。如果你能用上 H100,并且可以加载原始(未量化)的模型,通常能在相似的延迟下获得更高的图像质量。当然,实际效果还会因你的显存大小和批次大小而异。
示例 1:同一件衣服多角度视图,默认设置
我首先上传了同一套衣服从不同角度拍摄的几张照片,保持了默认的扩散步数和适中的引导比例。模型生成了光照一致、织物细节逼真的影棚照,最终的穿搭给人一种像是围绕同一套胶囊系列进行变化的感受。
示例 2:同一件衣服多角度视图,更高扩散步数
接下来,我使用了相同的参考图片,但将扩散步数增加到了 28(并略微调整了引导比例)。网格图片变得更清晰、更精致了一些,但仍然集中于重新组合那几件核心衣物。代价是每批次的生成时间有了一个不大但可感知再增加。
实验 3:每件独一无二的衣服只给一张图片
最后,我为每件不同的衣服只上传了一张产品照,并生成了另一个 3x3 的网格。结果,不同单元格之间的穿搭组合变得更加多样化,以有趣的方式混搭了不同的上衣和下装。虽然仍有少量重复出现,但整体而言,这个网格更接近一个真正的胶囊衣橱,在相同的种子和设置下产生了更多元化的组合。

总结
在我看来,4 位量化形式的 FLUX.2-dev 模型在图像应用领域表现得相当出色。在这篇教程中,我们不仅搭建了一个基于 diffusers 库的 4 位 FLUX.2-dev 管道,还实现了一个将衣物单品作为条件提示的多图像参考工作流,并将所有这些功能封装成一个 Gradio 应用。
最终,我们有了一个强大的胶囊衣橱可视化工具,它既可以作为时尚电商工具的原型,也可以单纯地作为一种趣味方式,来重新混搭你自己的衣橱。基于这个基础,你完全可以将相同的管道集成到更广阔的智能体系统中,比如一个能够根据着装规范或天气推荐穿搭的 LLM,又或者直接与一个真实的商品目录后端进行连接。未来的可能性真是无穷啊!
FLUX.2 常见问题
我能在本地不依赖 Mistral 文本编码器来使用 FLUX.2-Dev (4位量化) 管道吗?
当然可以。 FLUX.2 支持通过 Hugging Face 的文本编码服务进行远程文本编码,这能显著降低本地显存占用。你可以不加载本地的 Mistral3ForConditionalGeneration,而是直接传递从远程编码器获得的 prompt_embeds。这对于显存较小的 GPU(比如 RTX 4090 或移动 GPU)来说,简直是福音。
如何格式化或准备我的衣橱参考照片才能获得最佳效果?
虽然模型能接受各种图像,但若想获得更好的效果,我个人建议遵循以下几点:
- 衣物照片最好是在干净的背景下拍摄。
- 图像光照充足,大致为正面拍摄。
- 服装不要被严重遮挡。
- 所有物品的构图风格应保持相似(例如,居中拍摄的产品照)。
FLUX.2 能确保穿搭总包含一件上衣、一件下装和一双鞋吗?
默认情况下是不能的。 模型本身并不理解“服装类别”这样的概念,除非你在应用中明确地对其进行编码并强制执行选择逻辑。
你可以通过以下方式来强制实现这种结构:
- 使用像“来自参考图像 1 的上衣”、“来自参考图像 2 的下装”这样的标签。
- 或者,在
capsule_fn中加入基于规则的选择逻辑。
如何防止生成的图像中衣物混淆或变形?
多图像参考模式确实可能导致物品混淆,特别是当:
- 衣物看起来很相似时,
- 你传递了过多的参考图片(比如 8-10 张),
- 或者你的提示词过于模糊。
要减少混淆,你可以尝试:
- 每个瓦片使用更少的参考图像(最多 2-3 张)。
- 在提示词中加入更强的描述,比如“清晰分明的层次”、“不混淆”、“保留轮廓”。
- 确保参考照片在形状/颜色上有着明显的区别。
FLUX.2 究竟能处理多少张参考图片,且不影响质量?
FLUX.2 最多支持 10 张参考图片,但质量并不是线性提升的。 我个人实际经验告诉我:
- 1-4 张参考图 → 对每个单品的还原度非常高。
- 5-7 张参考图 → 精细细节的匹配度可能会有所减弱。
- 8-10 张参考图 → 混淆或模糊物品边界的风险会更高。
这主要是因为 FLUX 的多图像条件生成模块如何将视觉嵌入融合到去噪 Transformer 中。你传递的嵌入越多,Transformer 需要协调的空间和风格线索就越多,这也就容易导致它犯迷糊。
关于
关注我获取更多资讯

