Qwen3-VL-8B,作为通义系列中广受欢迎的视觉语言模型,凭借其强大的文本、图像乃至视频统一理解能力,已在多个领域展现了不凡潜力。它在文本生成、视觉推理、空间感知、长上下文处理和智能体交互方面都有显著改进,无论是在研究还是在边缘或云环境的实际部署中,都表现得游刃有余。
在这篇教程中,我将带大家用LoRA技术对Qwen3-VL-8B模型进行微调,让它能读懂复杂的电子原理图。通过训练模型理解原理图中的符号、连接和空间关系,我们能让它准确识别电路设计,甚至判断出在实际电路中应该添加哪些电子元件。
你将学到:
- 如何从Hugging Face加载数据集并进行清洗。
- 如何为训练创建一个多模态对话模板。
- 如何搭建Qwen3-VL视觉语言处理流程。
- 如何配置LoRA以实现高效训练,节省宝贵显存。
- 如何微调模型并保存检查点。
- 如何将训练好的适配器发布到Hugging Face Hub。
- 对比微调前后的模型性能。
如果你对Hugging Face还不太熟悉,DataCamp的 Hugging Face基础知识 技能路径会是一个不错的起点!
1. Qwen3-VL-8B微调环境准备
处理视觉语言模型时,GPU显存往往是决定性的瓶颈。高分辨率图像和多模态编码器能迅速消耗大量VRAM,因此,一块显存充裕的GPU是我的首选。
为了这次教程,我选用了一台配备80GB A100显卡的RunPod实例,并搭载了最新的PyTorch镜像。这个配置为训练提供了足够的VRAM空间,能够有效避免在微调过程中碰到内存瓶颈。特别要提到的,就是如果你也打算自己尝试,在选择Pod模板时,一定要注意容器和卷磁盘空间,我通常会设置到40GB,并把Hugging Face的访问令牌作为环境变量HF_TOKEN添加进去。这样能保证训练过程的顺畅。
 编辑PyTorch RunPod 配置
编辑PyTorch RunPod 配置
点击“编辑”,然后进行如下更改:
- 容器磁盘大小: 设置为 40 GB
- 卷磁盘大小: 设置为 40 GB
- 环境变量: 添加
HF_TOKEN并将其值设置为你的 Hugging Face 访问令牌(可从 Hugging Face 设置 生成)。
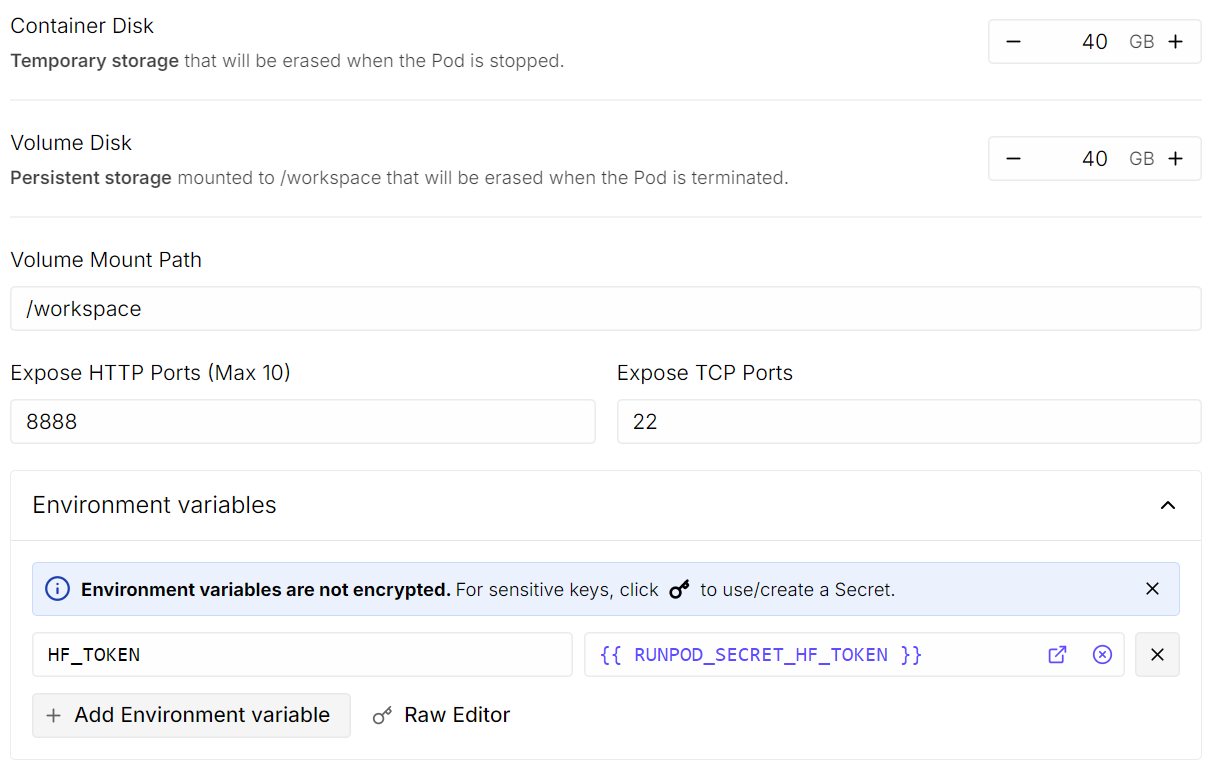 配置 RunPod 磁盘大小和环境变量
配置 RunPod 磁盘大小和环境变量
完成这些设置后,保存模板并部署Pod。
 Pod 摘要
Pod 摘要
一旦Pod运行起来:
- 打开 JupyterLab。
- 创建一个新的 Python notebook。
- 安装所需的依赖项。
要安装依赖项,请运行以下代码单元格。在 Jupyter 中,开头的感叹号表示 Notebook 将此行作为 Shell 命令执行,而不是 Python 代码。
!pip -q install -U accelerate datasets pillow sentencepiece safetensors peft
!pip install --quiet "transformers==5.0.0rc1"
!pip install --quiet --no-deps trl
!pip install --no-cache-dir flash-attn --no-build-isolation
接下来,为了确保实验的可复现性,我们会设置一个固定的随机种子,并启用A100专有的性能优化。
import torch
from transformers import set_seed
set_seed(42)
# A100: TF32 gives speedups without changing your bf16 training setup
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
print("CUDA:", torch.cuda.is_available(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
print("bf16 supported:", torch.cuda.is_available() and torch.cuda.is_bf16_supported())
运行结果通常如下:
CUDA: True NVIDIA A100 80GB PCIe
bf16 supported: True
2. 从 Hugging Face 下载 Open Schematics 数据集
现在,我们从 Hugging Face Hub 加载 Open Schematics 数据集。这个数据集包含了电子原理图图像以及描述每个电路的丰富元数据,非常适合用于视觉语言模型的训练。
import torch
from datasets import load_dataset
DATASET_ID = "bshada/open-schematics"
ds_all = load_dataset(DATASET_ID, split="train")
print(ds_all)
加载后的数据集信息大致如下:
Dataset({
features: ['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'],
num_rows: 84470
})
这个数据集包含了超过8.4万个样本,每个样本都将原理图图像与结构化信息(如元件列表、JSON和YAML等机器可读格式)配对。这为我们提供了丰富的数据来训练模型。
3. 探索数据集结构
为了更好地理解数据集的组成,我通常会检查单个样本。
# quick peek
ex = ds_all[0]
print("\nSample keys:", ex.keys())
print("name:", ex.get("name"))
print("type:", ex.get("type"))
print("components_used:", (ex.get("components_used") or [])[:10])
print("has schematic:", bool(ex.get("schematic")))
print("has json/yaml:", bool(ex.get("json")), bool(ex.get("yaml")))
print("image:", ex.get("image"))
输出结果:
Sample keys: dict_keys(['schematic', 'image', 'components_used', 'json', 'yaml', 'name', 'description', 'type'])
name: TiebeDeclercq/Uart-programmer
type: .kicad_sch
components_used: ['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C']
has schematic: True
has json/yaml: True True
image: <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=1123x794 at 0x7FBC6FD060F0>
这证实了每个样本都包含了一张高分辨率的原理图图片、一个元件列表以及电路的结构化表示。
我们现在可以直接在 Jupyter notebook 中渲染原理图图片。
ex.get("image")
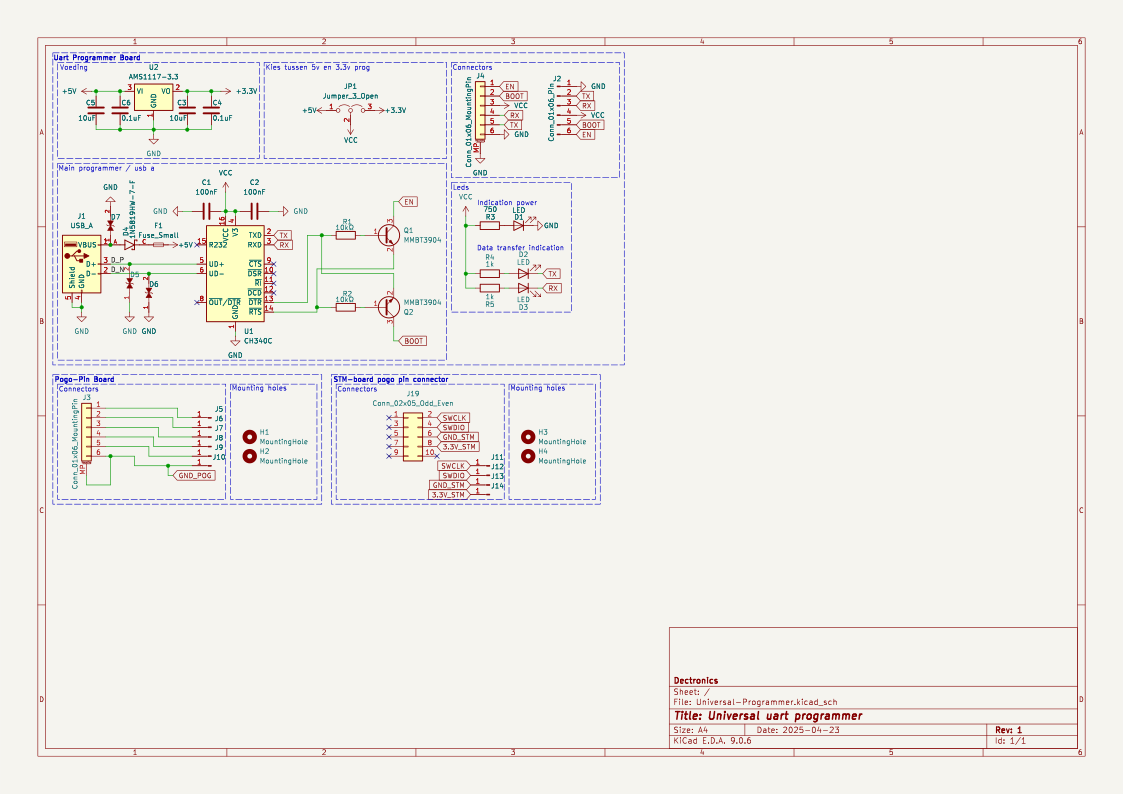 电子原理图
电子原理图
最后,我们来看看这张原理图中使用的所有元件列表。
print(ex.get("components_used"))
['Conn_01x01_Pin', 'Conn_01x06_Pin', 'USB_A', 'Conn_02x05_Odd_Even', 'Conn_01x06_MountingPin', 'C', 'Fuse_Small', 'LED', 'R', 'CH340C', 'Jumper_3_Open', 'MountingHole', 'AMS1117-3.3', 'MMBT3904', '1N5819HW-7-F', 'LESD5D5.0CT1G', '+3.3V', '+5V', 'GND', 'VCC']
这个元件列表为原理图图像和电路中存在的电子元件之间提供了清晰的对应关系。
4. 清理和过滤数据集
在训练模型之前,我会先对数据集进行清理和过滤,以确保每个样本都包含视觉语言学习所需的最低限度信息。特别要强调的是,我们只保留那些拥有有效元件注释和对应原理图图像的示例。这就像是筛选原材料,确保数据是干静的,能让模型学到真正有用的东西,而不是被噪声干扰。
首先,我们检查有多少样本缺少、为空或包含无效的 components_used 条目。
need_cols = [c for c in ["components_used", "schematic", "name", "type"] if c in ds_all.column_names]
ds_small = ds_all.select_columns(need_cols)
missing_key = none_components = empty_components = missing_any = 0
has_schematic_but_missing = 0
for ex in ds_small:
if "components_used" not in ex:
missing_key += 1
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
continue
cu = ex["components_used"]
bad = (cu is None) or (isinstance(cu, list) and len(cu) == 0)
if cu is None:
none_components += 1
elif isinstance(cu, list) and len(cu) == 0:
empty_components += 1
if bad:
missing_any += 1
if ex.get("schematic"):
has_schematic_but_missing += 1
print("\n=== Missing components report ===")
print("Total:", len(ds_all))
print("Missing key:", missing_key)
print("None:", none_components)
print("Empty list:", empty_components)
print("Missing (any):", missing_any)
if "schematic" in need_cols:
print("Has schematic but missing components:", has_schematic_but_missing)
报告结果:
=== Missing components report ===
Total: 84470
Missing key: 0
None: 47558
Empty list: 8
Missing (any): 47566
Has schematic but missing components: 47566
摘要显示,很大一部分样本包含原理图数据,但缺少可用的元件注释。这可是个大问题,我们得处理。
为了在过滤过程中避免不必要的内存使用,我们明确禁用了图像解码。这可以确保 Hugging Face 在应用过滤器时不会将图像加载到内存中,提高了效率。
from datasets.features import Image as HFImage
ds_all = ds_all.cast_column("image", HFImage(decode=False))
然后,我们定义一个过滤器,只保留那些包含非空元件列表和有效图像引用的样本。
def keep_components_and_image(components_used, image):
# keep only rows with components
if not (isinstance(components_used, list) and len(components_used) > 0):
return False
# image must exist
if image is None:
return False
# when decode=False, image is dict-like: {"path": ...} or {"bytes": ...}
if isinstance(image, dict):
return bool(image.get("path")) or bool(image.get("bytes"))
return True
应用此过滤器将数据集大幅缩减为高质量、完全可用的样本。
ds_clean = ds_all.filter(
keep_components_and_image,
input_columns=["components_used", "image"],
)
print("Original:", len(ds_all))
print("Clean:", len(ds_clean))
print("Dropped:", len(ds_all) - len(ds_clean))
Original: 84470
Clean: 33275
Dropped: 51195
经过过滤,我们还剩下超过3.3万个干净的样本,它们都包含有效的原理图图像和明确的元件注释。这个经过清洗的数据集为后续的预处理和模型训练奠定了可靠的基础。
5. 加载 Qwen3-VL-8B 视觉语言模型
现在,我们加载 Qwen3-VL-8B-Instruct 模型及其对应的处理器。这个模型是一个大规模的视觉语言模型,能够联合推理图像和文本,非常适合原理图理解这类任务。
模型以 bfloat16 精度加载,以减少内存使用同时保持数值稳定性。我还为 A100 GPU 启用了 Flash Attention 2,以实现更快、更节省内存的注意力计算。device_map="auto" 选项会自动将模型层放置在可用的 GPU 上。这些都是我在实际部署这类模型时常用的优化手段,能让训练效率倍增,同时还能稳住精度。
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
MODEL_ID = "Qwen/Qwen3-VL-8B-Instruct"
model = Qwen3VLForConditionalGeneration.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(MODEL_ID)
6. 针对电路分析的提示词设计
这一步定义了一些轻量级的工具函数,用于为视觉语言模型训练准备提示词、目标输出和图像。通过切换 TASK 变量(可以是 components、yaml、json 或 schematic 重构),我们可以用一套管道来处理多项任务。
这里还设置了一些基本的安全限制,用来控制目标输出的长度和图像大小。这有助于保持训练的稳定性和内存效率,避免出现意外情况。
from PIL import Image
TASK = "components" # "components" | "yaml" | "json" | "schematic"
MAX_TARGET_CHARS = 5000 # safety cap for long targets like schematic/json
MAX_IMAGE_SIDE = 1024 # bigger side
MAX_IMAGE_PIXELS = 1024 * 1024 # safety cap (1.0 MP). raise to 1.5MP if stable
构建提示词
build_prompt() 函数负责构建传递给模型的指令文本。它利用数据集中的元数据提供上下文信息,并强制实施严格的输出约束,以减少模型“幻觉”并保持跨任务的监督一致性。对我来说,构建一个清晰、有针对性的提示词,是微调成功的关健一步。
def build_prompt(example):
# Use dataset fields to give better context (name/type are helpful)
name = example.get("name") or "Unknown project"
ftype = example.get("type") or "unknown format"
if TASK == "components":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, extract all component labels and identifiers exactly as shown "
"(part numbers, values, footprints, net labels like +5V/GND).\n"
"Output only a comma-separated list. Do not generalize or add extra text."
)
if TASK == "yaml":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce YAML metadata for the design.\n"
"Return valid YAML only. No markdown, no explanations."
)
if TASK == "json":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, produce a JSON representation of the schematic structure.\n"
"Return valid JSON only. No markdown, no explanations."
)
if TASK == "schematic":
return (
f"Project: {name}\nFormat: {ftype}\n"
"From the schematic image, reconstruct the raw KiCad schematic content.\n"
"Return only the schematic text. No markdown, no explanations."
)
raise ValueError("Unknown TASK")
构建目标输出
build_target() 函数直接从数据集中提取所选任务的真实输出。内容会原样返回,以便模型学习精确复现,而不是进行转述。
def build_target(example):
if TASK == "components":
comps = example.get("components_used") or []
return ", ".join(comps)
if TASK == "yaml":
return (example.get("yaml") or "").strip()
if TASK == "json":
return (example.get("json") or "").strip()
if TASK == "schematic":
return (example.get("schematic") or "").strip()
raise ValueError("Unknown TASK")
clamp_text() 函数对目标文本应用硬字符限制。这可以防止过大的 JSON、YAML 或原理图文件在训练期间导致内存问题。
def clamp_text(s: str, max_chars: int = MAX_TARGET_CHARS) -> str:
s = (s or "").strip()
return s if len(s) <= max_chars else s[:max_chars].rstrip()
调整图片大小
_resize_pil() 函数在处理前对原理图图像进行标准化和大小调整。它强制执行最大边长和最大总像素数,这既能确保可预测的 GPU 内存使用,又能保留视觉细节,对我来说是平衡性能和效果的关键。
def _resize_pil(pil: Image.Image, max_side: int = MAX_IMAGE_SIDE, max_pixels: int = MAX_IMAGE_PIXELS) -> Image.Image:
pil = pil.convert("RGB")
w, h = pil.size
# Scale down if max side too large
scale_side = min(1.0, max_side / float(max(w, h)))
# Scale down if too many pixels (area cap)
scale_area = (max_pixels / float(w * h)) ** 0.5 if (w * h) > max_pixels else 1.0
scale = min(scale_side, scale_area)
if scale < 1.0:
nw, nh = max(1, int(w * scale)), max(1, int(h * scale))
pil = pil.resize((nw, nh), resample=Image.BICUBIC)
return pil
7. 设置多模态聊天模板
在这一步中,我们将每个经过清理的数据集样本转换为多模态聊天格式,这种格式可以直接被 Qwen 视觉语言模型使用。这种格式明确地将原理图图像与文本指令及其对应的目标输出对齐,是模型理解复杂指令的关键。
def to_messages(example):
prompt = build_prompt(example)
target = clamp_text(build_target(example))
example["messages"] = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": target}],
},
]
return example
我们打乱数据集以消除排序偏差,并选择一个小子集进行初步实验。
然后,数据集通过 to_messages() 进行映射,以生成多模态训练示例。最后,重新启用图像解码,这样图像只在训练时加载,从而使预处理保持轻量化和内存高效。
# Start small (increase later)
train_ds = ds_clean.shuffle(seed=42).select(range(min(800, len(ds_clean)))).map(to_messages)
train_ds = train_ds.cast_column("image", HFImage(decode=True))
8. Qwen3-VL-8B 预微调评估
在真正动手微调之前,我总是会习惯性地先跑个基线测试。这就像做实验前的对照组,能帮我搞清楚 Qwen3-VL 8B Instruct 模型在没有针对性训练前,在我们的任务上到底是个什么水平。这个基线能帮助我们理解预训练模型在没有任务特定适应的情况下,从原理图图像中提取信息的能力如何。
run_inference() 函数会使用与训练时相同的提示词和图像预处理逻辑,对一个示例执行一次前向传播。
import torch
def run_inference(model_, example, max_new_tokens=256):
prompt = build_prompt(example)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": _resize_pil(example["image"])},
{"type": "text", "text": prompt},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model_.device)
with torch.inference_mode():
out = model_.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
gen = out[0][inputs["input_ids"].shape[1]:]
return processor.decode(gen, skip_special_tokens=True)
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
我们首先评估模型在训练集中随机选择的一个样本上的表现。
print("\n--- BASELINE OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))
输出结果:
--- BASELINE OUTPUT ---
J1,Conn_02x11_Odd_Even,CINT6,CINT5,CINT4,CINT3,CINT2,CINT1,CINT0,CINT15,CINT14,CINT13,CINT12,CINT11,CINT10,CINT9,CINT8,CINT7,CINT16,CINT17,CINT18,CINT19,CINT20,CINT21,CINT22,CINT23,CINT24,CINT25,CINT26,CINT27,CINT28,CINT29,CINT30,CINT31,CINT32,CINT33,CINT34,CINT35,CINT36,CINT37,CINT38,CINT39,CINT40,CINT41,CINT42,CINT43,CINT44,CINT45,CINT46,CINT47,CINT48,CINT49,CINT50,CINT51,CINT52,CINT53,CINT54,CINT55,CINT56,CINT57,CINT58,CINT59,CINT60,CINT61,CINT62
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GND
在这个例子中,模型虽然识别出了一些结构性元素,但它过度生成了引脚和信号名称,并且未能精确地复现数据集中使用的元件标识符。我在评估更多例子时也发现了同样的模式。
总的来说,这些基线结果表明,尽管模型具有很强的通用视觉和文本理解能力,但它与数据集特定的元件注释之间缺乏对齐。这种行为凸显了微调的必要性,以减少幻觉输出并提高准确性。
9. 构建视觉语言数据整理器(Data Collator)以用于训练
我得说,这个数据整理器是整个训练流程中非常精巧的一个部分。它不仅仅是简单地打包数据,更重要的是确保损失计算只集中在模型生成的部分,而不会被提示词或填充token给干扰了。这在多模态模型里面尤为重要,因为输入往往很复杂。
它将每个示例转换为模型就绪的张量,通过联合编码文本和图像,同时确保只在助手的响应上计算损失。
该整理器构建了两个版本的聊天文本:一个用于输入编码的完整版本(提示和目标),以及一个仅用于计算提示词token长度的仅提示词版本。利用这些长度,所有提示词和填充token在标签中都被掩码,这样只有助手的输出才对损失做出贡献。图像大小被一致调整,并且强制执行固定的最大序列长度以进行内存控制。
from typing import List, Dict, Any
import torch
MAX_LEN = 1500
def collate_fn(batch: List[Dict[str, Any]]):
# 1) Build full chat text (includes assistant answer)
full_texts = [
processor.apply_chat_template(
ex["messages"],
tokenize=False,
add_generation_prompt=False,
)
for ex in batch
]
# 2) Build prompt-only text (up to user turn; generation prompt on)
prompt_texts = [
processor.apply_chat_template(
ex["messages"][:-1],
tokenize=False,
add_generation_prompt=True,
)
for ex in batch
]
# 3) Images
images = [_resize_pil(ex["image"]) for ex in batch]
# 4) Tokenize full inputs ONCE (text + images)
enc = processor(
text=full_texts,
images=images,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
)
input_ids = enc["input_ids"]
pad_id = processor.tokenizer.pad_token_id
# 5) Compute prompt lengths with TEXT-ONLY tokenization (much cheaper than text+images)
prompt_ids = processor.tokenizer(
prompt_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_LEN,
add_special_tokens=False, # chat template already includes special tokens
)["input_ids"]
# Count non-pad tokens in prompt
prompt_lens = (prompt_ids != pad_id).sum(dim=1)
# 6) Labels: copy + mask prompt tokens + mask padding
labels = input_ids.clone()
bs, seqlen = labels.shape
for i in range(bs):
pl = int(prompt_lens[i].item())
pl = min(pl, seqlen)
labels[i, :pl] = -100
# Mask padding positions too
labels[labels == pad_id] = -100
# If your processor produces pixel_values / image_grid_thw, keep them
enc["labels"] = labels
return enc
这个整理器实现了对视觉语言微调的有效且正确的监督。
10. 配置 LoRA 实现高效的 Qwen3-VL-8B 微调
现在,我们将配置 LoRA(Low-Rank Adaptation,低秩适应)来高效地微调 Qwen3-VL 模型,而无需更新所有模型权重。LoRA 通过在选定的投影层中注入可训练的低秩矩阵,显著减少内存使用,同时保持性能。
对于像Qwen3-VL-8B这样的大模型,直接全量微调几乎是不可能的,或者说,成本太高了。所以我一般都会用LoRA,它能在大幅减少显存占用的同时,还保持不错的性能,在我看来,这是非常实用的技术。
from peft import LoraConfig, TaskType, get_peft_model
lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM,
target_modules=[
"q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"
],
)
然后,我们使用 SFTConfig 定义训练配置,设置批量大小、学习率、精度和日志记录选项,这些都是为 A100 GPU 上的稳定微调量身定制的。
from trl import SFTTrainer, SFTConfig
args = SFTConfig(
output_dir=f"qwen3vl-open-schematics-{TASK}-lora",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=False,
learning_rate=1e-4,
warmup_steps=10,
weight_decay=0.01,
max_grad_norm=1.0,
bf16=True,
fp16=False,
lr_scheduler_type="cosine",
logging_steps=10,
report_to="none",
remove_unused_columns=False,
)
最后,我们初始化 SFTTrainer,结合模型、数据集、自定义整理器和 LoRA 配置,开始进行监督微调。
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=train_ds,
data_collator=collate_fn,
peft_config=lora
)
11. 在 Open Schematics 数据集上微调 Qwen3‑VL-8B
现在,我们使用配置好的训练器启动微调过程。
trainer.train()
训练开始后,你可以监控 RunPod 的遥测仪表板。在 A100 80GB 实例上,整个过程通常会占用大约 40–45 GB 的 VRAM,并且 GPU 利用率接近满载,这表明硬件资源得到了高效利用。
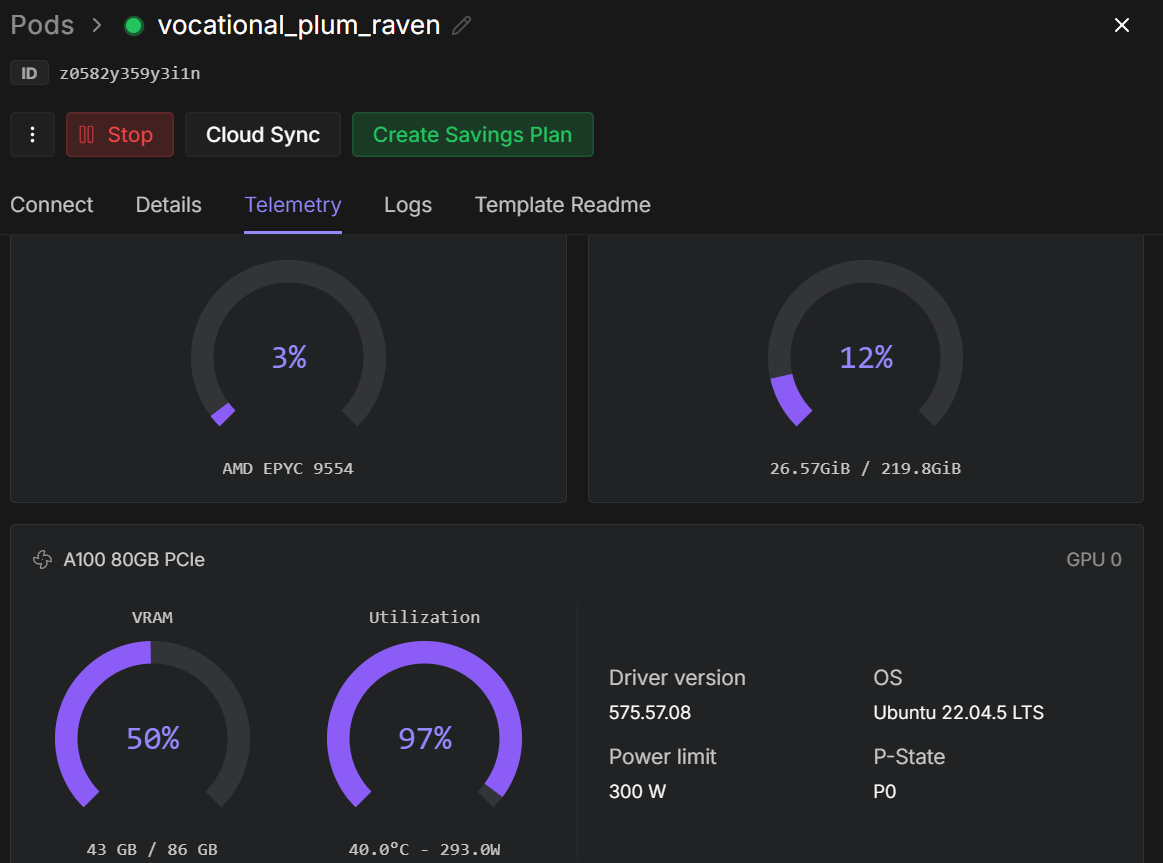 模型训练期间的 Runpod 遥测
模型训练期间的 Runpod 遥测
随着训练的进行,你会看到训练损失(training loss)稳步下降,然后趋于稳定。在我的实践中,损失收敛并稳定在大约 6.5,这作为一个基线指标,说明模型已经适应了原理图元件提取任务。
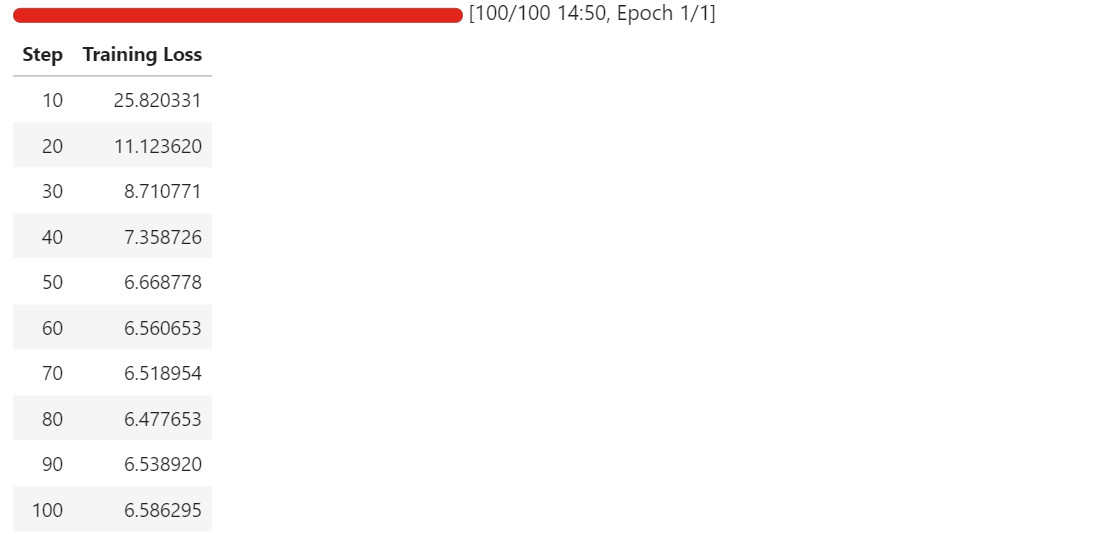 训练损失逐渐降低
训练损失逐渐降低
至此,LoRA 适配器已经成功微调,可以进行评估和导出了。
12. 将微调后的模型发布到 Hugging Face Hub
微调完成后,我通常会先将训练好的 LoRA 适配器和相关的处理器保存到本地。这是为了确保我们有一个本地备份,以防后续操作出现问题。
out_dir = trainer.args.output_dir # from your SFTConfig/TrainingArguments
trainer.save_model(out_dir) # saves model/adapters into output_dir
processor.save_pretrained(out_dir) # save processor (tokenizer + image processor)
接下来,我们将微调后的模型发布到 Hugging Face Hub。这样做的好处是,这些适配器和处理器可以方便地用于推理或进一步的微调,实现了模型的共享和复用。
import os
repo_id = "kingabzpro/qwen3vl-open-schematics-lora" # replace with your username/repo
# Push model/adapters
trainer.model.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
# Push processor
processor.push_to_hub(
repo_id,
token=os.getenv("HF_TOKEN"),
)
 将模型适配器和处理器推送到 Hugging Face Hub
将模型适配器和处理器推送到 Hugging Face Hub
上传完成后,经过微调的 LoRA 适配器和处理器将公开在 指定的仓库 中可用。
 已将微调后的 LoRA 推送到 Hugging Face Hub
已将微调后的 LoRA 推送到 Hugging Face Hub
12. 评估微调后的 Qwen3-VL-8B 模型
微调之后,我会直接从 Hugging Face Hub 重新加载模型和处理器。这能确保我们在评估时,使用的是导出后的 LoRA 适配器,模拟真实的推理环境。
model = Qwen3VLForConditionalGeneration.from_pretrained(
repo_id,
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(repo_id)
我们再在用之前那个例子来跑一下,看看微调后的模型表现如何。这种前后对比是验证微调效果最直观的方法。
baseline_ex = train_ds.shuffle(seed=120).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))
输出结果:
--- FINETUNED OUTPUT ---
Conn_02x11_0dd_Even, P3.3V
--- TARGET (dataset) ---
Conn_02x11_Odd_Even, R_Pack04, GND
与基线模型相比,微调后的模型生成了更短、更集中的输出,避免了大量生成引脚名称和推断信号。
尽管预测仍不完整且包含微小错误,但它明显趋向于与数据集对齐的元件标识符。
现在,我们将评估第二个例子来确认这种行为。
baseline_ex = train_ds.shuffle(seed=170).select(range(1))[0]
print("\n--- FINETUNED OUTPUT ---\n", run_inference(model, baseline_ex))
print("\n--- TARGET (dataset) ---\n", clamp_text(build_target(baseline_ex), 1500))
输出结果:
--- FINETUNED OUTPUT ---
ATMEGA328P-PU, +5V, GND, R, C, C16MHz, SERVO_A, SERVO_B, SERVO_C, SERVO_D, SERVO_E, SERVO_F, SERVO_G
--- TARGET (dataset) ---
+5V, 7.62MM-3P, 7.62MM-3P_1, 7.62MM-3P_2, 7.62MM-3P_3, 7.62MM-3P_4, 7.62MM-3P_5, 7.62MM-3P_6, ATMEGA328P-PU, ATMEGA328P-PU_1, GND, MBB02070C1002FCT00, MBB02070C1002FCT00_1, Unknown_0_-806, X49SD16MSD2SC, Y5P102K2KV16CC0224, Y5P102K2KV16CC0224_1, Y5P102K2KV16CC0224_2
在这里,微调后的模型正确识别了微控制器和电源网络等核心元件,并显著减少了不相关的信号级幻觉。然而,它仍然对一些元件进行了抽象或泛化,而不是复现精确的数据集特定标识符。
总的来说,这些结果表明,微调成功地抑制了过多的生成,并提高了与原理图级元件提取的对齐。虽然通过更多的 epoch、更大的训练集或更严格的输出约束可以进一步提高准确性,但微调后的行为代表了相对于基线模型的明显可衡量的改进。
如果你在运行本教程中的代码时遇到任何问题,请参考 随附的 Notebook。
最终思考
处理视觉语言模型与纯文本模型有着本质上的不同,如果把它们一概而论,结果往往不尽如人意。我个人在实践中就吃过亏:哪怕批量大小设为一,也很容易遇到显存不足的问题;或者模型看起来在训练,但实际上并没有真正学到任务。
最终让我醍醐灌顶的是,必须关注多模态训练中那些“细节”之处。把图像调整到安全的尺寸、清理数据集以剔除损坏或无法使用的样本、确保只将有效的图像-文本对输入模型——这些都是至关重要的步骤。跳过其中任何一个环节,都可能导致模型不稳定或计算资源白白浪费。
在模型方面,只使用相关的 LoRA 目标层,有助于保持训练的高效和专注,同时精心调整训练参数,在不增加内存压力的前提下,改善了收敛效果。针对 A100 GPU 进行优化、启用 Flash Attention 并使用 bfloat16 精度,这些都让训练过程保持稳定,并显著缩短了运行时间。在我的实际经验中,这些优化几乎将训练时间缩短了一半,而且并没有牺牲模型质量。
最终结果表明,即使是一个强大的预训练视觉语言模型,也能从领域特定的微调中获益匪浅。只要有正确的预处理、合理的配置和硬件感知的优化,我们就能可靠且高效地适配大型多模态模型。
如果你对进一步练习微调感兴趣,我推荐你学习 Llama 3 微调 课程。
关于
关注我获取更多资讯

