处理文档,尤其是长文档,一直是 LLM 和 VLM 应用里一个又贵又慢的环节。无论是文档问答、信息提取还是数据分析,只要输入内容一多,token 数量就会暴涨,随之而来的是更高的内存占用、更慢的推理速度和实实在在的成本。归根结底都的怪 token。
DeepSeek-AI 最近推出的 DeepSeek-OCR 另辟蹊径,提出一个很有意思的概念:光学上下文压缩 (Optical Context Compression)。它的核心想法是,与其把文档图像先 OCR 成海量文本 token 再喂给模型,不如直接把文档页面本身“压缩”成一小组视觉 token。这相当于是用视觉特征来给整个页面内容做个高度浓缩的摘要。
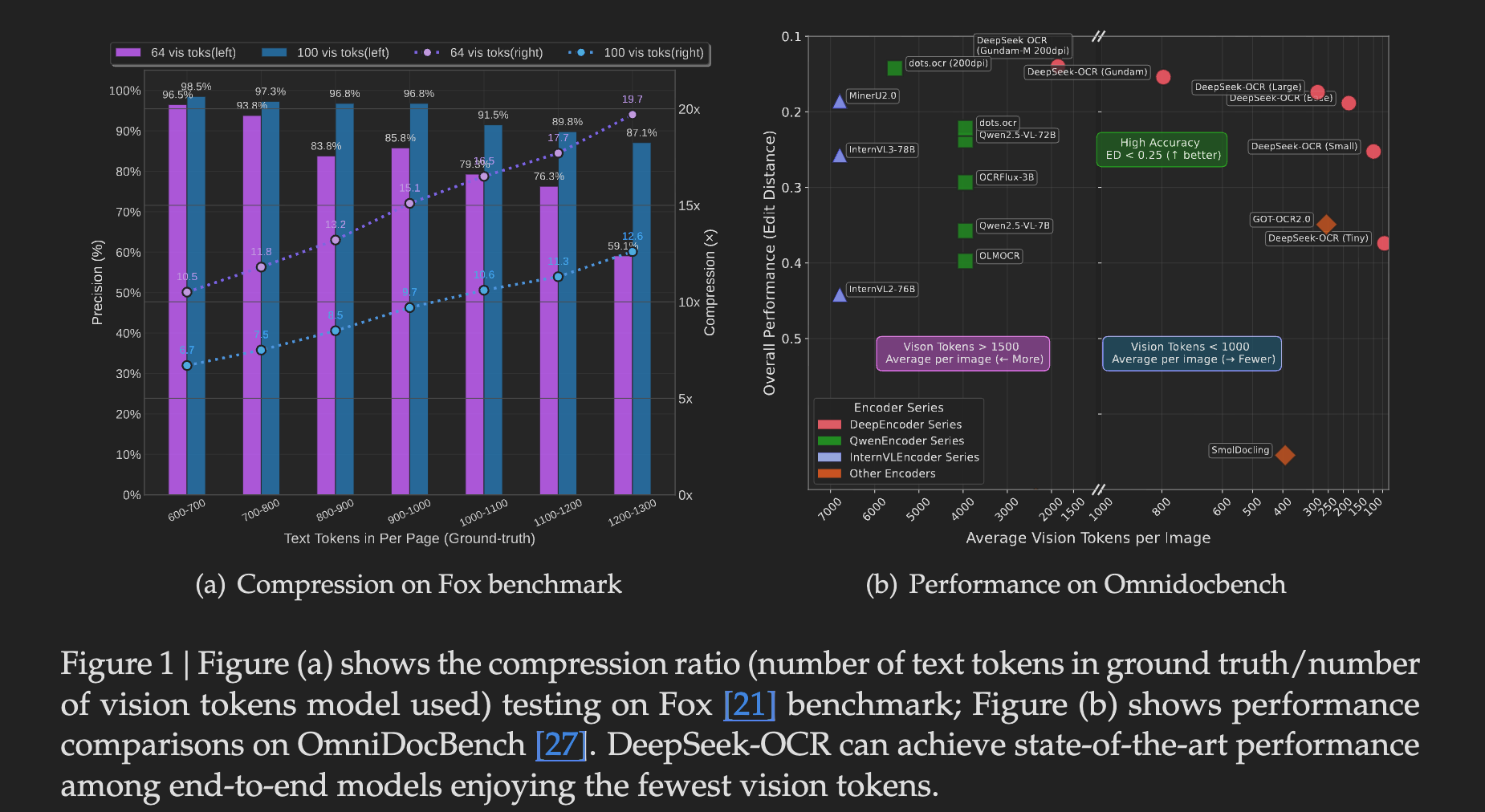
这种方法将 token 数量降低了 7 到 20 倍,同时在基准测试中依然保持了很强的竞争力。它不仅为大规模文档处理提供了一个高效的解决方案,也为生成 LLM/VLM 训练数据开辟了新思路。
核心思路:为什么是“光学压缩”?
传统流程是 图像 -> OCR 引擎 -> 大量文本 Token -> LLM。这个过程的瓶颈在于,一页排版密集的 A4 纸转成文本后,可能会轻易产生几千个 token。
DeepSeek-OCR 的流程则是 图像 -> DeepEncoder -> 少量视觉 Token -> DeepSeek MoE 解码器 -> 文本。它把 OCR 这个任务,看作是一个“视觉压缩-文本解压”的过程。通过一个专门的视觉编码器,将页面图像的精华信息,包括文字、布局、图表等,编码成数量很少的视觉 token。然后,再由一个高效的语言模型解码器,从这些浓缩的视觉 token 中重建出原始的文本内容。
这种思路的直接好处就是降本增效。token 少了,计算量和显存开销自然就下来了。
DeepSeek-OCR 的架构拆解
整个模型由两个关键部分组成:负责压缩的 DeepEncoder 和负责解码的 DeepSeek-3B-MoE。
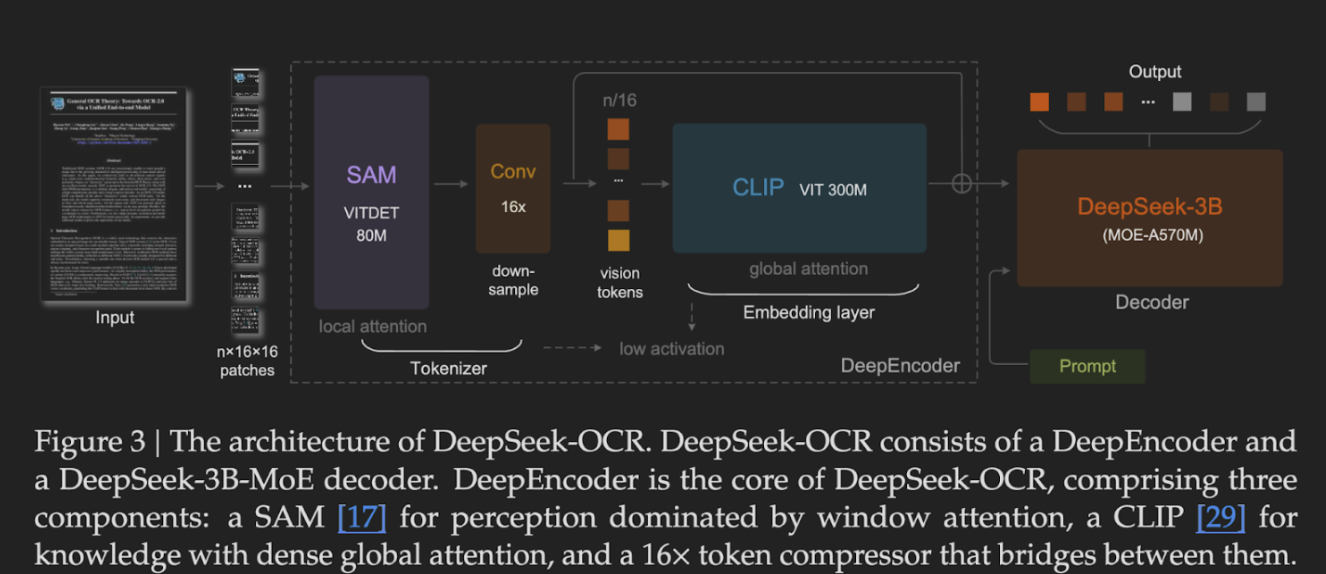
DeepEncoder:视觉信息的双重保障
DeepEncoder 是一个专门为高分辨率输入设计的视觉编码器,它巧妙地结合了两种注意力机制来捕捉信息:
- SAM (Segment Anything Model):利用其大约 8000 万的参数进行局部注意力计算,负责提取精细的视觉特征和不句信息,比如字符的笔画、单词的间距等。
- CLIP (Contrastive Language–Image Pre-training):利用其 3 亿参数进行全局注意力计算,负责从压缩后的视觉 token 中提炼出更高层次的语义特征。
这种局部与全局结合的策略,确保了在压缩信息的同时,关键的细节和整体的语义都能被保留下来。
DeepSeek-3B-MoE 解码器:高效的文本重建
解码器采用的是 DeepSeek 拿手的 Mixture-of-Experts (MoE) 架构。这个模型总共有 30 亿参数,但在实际推理时,每次只会激活其中的一小部分专家(约 5.7 亿参数)。MoE 架构的优势在于,它能以远小于模型总参数量的计算成本,获得与大型稠密模型相近的性能,非常适合这种需要兼顾效率和效果的场景。
性能与权衡
当然,压缩总是有代价的。DeepSeek-OCR 的性能与压缩率直接挂钩。
- 在 10 倍以下的压缩率时,模型能达到约 97% 的 OCR 精度,这对于大多数应用场景来说,几乎是无损的。
- 当压缩率提高到 20 倍时,精度会下降到 60% 左右。虽然精度损失较大,但在某些对精度要求不高,比如文档归档或粗略索引的场景下,可能仍然有价值。
它在 OmniDocBench 基准测试上的表现也印证了这点,用远少于竞品模型的 token 数量(每页 100 tokens 对比 GOT-OCR2.0 的 256 tokens,每页不到 800 tokens 对比 MinerU2.0 的 6000+ tokens),实现了超越或持平的性能。
为了方便用户在不同场景下做权衡,DeepSeek-OCR 提供了多种分辨率模式,每种模式对应不同的视觉 token 数量和处理精度。
| 模式 (Mode) | 分辨率 (Resolution) | 视觉 Token 数 | 适用场景 |
|---|---|---|---|
Tiny |
512x512 | 64 | 快速预览、低分辨率文档 |
Small |
640x640 | 100 | 标准文档 |
Base |
1024x1024 | 256 | 高分辨率页面 |
Large |
1280x1280 | 400 | 复杂布局 |
Gundam |
动态 (Dynamic) | 795+ | 再多栏、高密度文档,如学术论文或报告 |

实际上手试试
DeepSeek-OCR 的使用非常简单,通过 transformers 库就能快速调用。
from transformers import AutoModel, AutoTokenizer
import torch
from PIL import Image
model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 为了获得最佳性能,建议使用 flash_attention_2
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True
).eval().cuda().to(torch.bfloat16)
# 加载一张文档图片
image = Image.open("document.png").convert("RGB")
prompt = "<image>\nFree OCR." # prompt 可以为空或包含特定指令
inputs = tokenizer(prompt, images=[image], return_tensors="pt").to("cuda")
output = model.generate(**inputs, max_new_tokens=4096)
# 解码并打印结果
print(tokenizer.decode(output[0]))
局限性与思考
有几点需要注意:
- 精度与压缩的权衡:如前所述,超高的压缩率会牺牲准确性,需要根据具体业务需求选择合适的分辨率模式。
- 复杂布局的挑战:虽然
Gundam模式对多栏布局有所优化,但对于报纸这种极端复杂的排版,识别结果可能仍需人工校对。 - 硬件要求:模型需要支持 CUDA 的 NVIDIA GPU 才能发挥最佳性能。
我个人认为,这个思路的价值可能不只在于 OCR 本身,它更像是一种高效的“长上下文”处理范式。未来,这种将高维信息(如文档、网页、视频帧)压缩成少量 token 再让 LLM 理解的方式,可能会被应用到更多领域,成为解决 LLM 上下文长度瓶颈的一个重要方向。
总的来说,DeepSeek-OCR 用一种很巧妙的方式,绕开了传统 OCR 和 VLM 处理文档时的高 token 成本问题。它的开源和多模式设计,使其无论是对于需要大规模文档数字化的企业,还是对于需要生成高质量图文训练数据的 AI 实验室,都是一个值得关注的工具。
模型已经在 GitHub 和 Hugging Face 上开源,感兴趣的朋友可以自己动手试试。
关于
关注我获取更多资讯

