光学字符识别(OCR)这个领域,感觉上已经被解决了,但实际应用中总会遇到各种棘手的场景。识别标准印刷体文档没问题,可一旦遇到手写笔记、复杂的图表、数学公式,甚至是网络上的 Meme 图,传统 OCR 工具就开始力不从心。
DeepSeek-OCR 是一个新的开源视觉语言模型,它声称能搞定这些复杂的文档理解任务。它不只是简单地识别文字,还能解析表格结构、提取图表数据,甚至处理多语言和手写内容。
这篇文章不是一篇简单的介绍。我打算把它拉到“练兵场”上,通过 7 个真实的、有代表性的场景,端到端地测试它的能力。从搭建一个简单的 Web 应用开始,我们会一起看看 DeepSeek-OCR 在图表提取、手写识别、公式解析等方面的真实表现,看看它到底是真的强,还是只是听起来很美。
DeepSeek-OCR 是什么?
简单来说,DeepSeek-OCR 是一个拥有 30 亿参数的开源视觉语言模型,专门为文档理解而生。它的核心特点是利用一种名为“上下文光学压缩”(Context Optical Compression)的技术,能将高分辨率的 2D 视觉信息高效地压缩成 Vision Token,从而让模型能以更低的计算成本处理超长文档。
它的几个关键能力包括:
- 读取大型扫描文档,如收据、发票、研究论文等。
- 解析表格、图表和几何图形。
- 处理多语言混合及手写文本。
它的工作原理
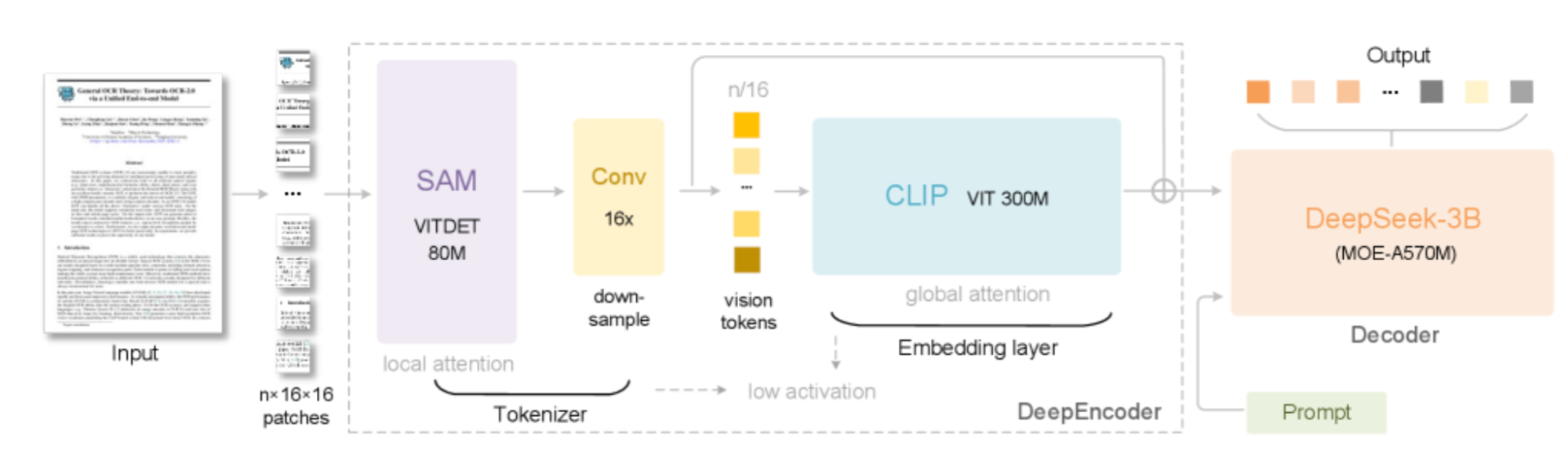
DeepSeek-OCR 的架构设计很有意思,它没有把图像和文本看作两个独立的东西,而是将视觉作为一种长文本的“压缩引擎”。这使得大语言模型(LLM)能用少得多的 Token 来处理海量信息。
它的核心流水线主要包含两个部分:
- DeepEncoder (视觉 Tokenizer 和压缩器)
- DeepSeek-3B MoE Decoder (文本生成器)
 来源: DeepSeek-OCR: Contexts Optical Compression
来源: DeepSeek-OCR: Contexts Optical Compression
整个过程可以分解为几步:
-
图像预处理:输入的文档图像,比如一张扫描合同或手写笔记,首先会被切分成 16x16 像素的网格块(Patch),这是模型能理解的最小视觉单位。
-
DeepEncoder (视觉编码器):这是一个多阶段的视觉处理引擎,目标是在分辨率、内存占用和信息压缩之间找到平衡。
- SAM (Segment Anything Model):负责处理局部注意力,通过分析重叠的小块来捕捉精细的细节和布局。
- 卷积压缩器:通过压缩局部特征,大幅减少视觉 Token 的数量,这样就能把更少的 Token 送到计算成本高昂的全局注意力阶段。
- CLIP ViT:这是一个视觉 Transformer,它对压缩后的 Token 应用全局注意力,以理解整个文档的结构和上下文。
-
Vision Token 到文本:压缩后的视觉 Token 被送入 DeepSeek-3B MoE(Mixture-of-Experts)解码器。MoE 架构在推理时只激活最相关的“专家”网络,从而在不牺牲准确性的前提下降低了计算成本。
-
Prompt 驱动的灵活性:和操作 LLM 类似,我们可以通过改变 Prompt 来控制输出的格式,比如 Markdown、HTML 表格、SMILES 化学式等等。
这种设计让 DeepSeek-OCR 能将一张文档图像的信息压缩到只有纯文本所需 Token 数量的十分之一,同时还不会有明显的精度损失。
搭建一个 Gradio 应用来测试
理论说完了,我们来动手搭个 Web 应用,方便直观地测试 DeepSeek-OCR。下面几步可以让你在本地或者 Google Colab 里跑起来。
第一步:安装依赖
首先,把所有需要的库装上。
!pip install -q "transformers==4.46.3" "tokenizers==0.20.3" einops addict easydict pillow gradio
注意:这个环境建议在带有 L4 GPU 和高内存的 Google Colab 实例上运行。
第二步:导入必要的模块
import os, time, torch, gradio as gr
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from datetime import datetime
import random
import string
第三步:加载模型
要从 Hugging Face 加载模型,你需要一个 Access Token。在 Google Colab 里,可以通过 “Secrets” 功能安全地存储你的 Token。
model_id = "deepseek-ai/DeepSeek-OCR"
tok = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
if tok.pad_token is None and tok.eos_token is not None:
tok.pad_token = tok.eos_token
model = AutoModel.from_pretrained(
model_id,
trust_remote_code=True,
use_safetensors=True,
attn_implementation="eager"
).to(dtype=torch.bfloat16, device="cuda").eval()
这里我们用 bfloat16 格式加载模型,这是一种在保持性能的同时降低显存占用的有效方法。
第四步:辅助函数
为了让每次测试的输出都井井有条,我们写个函数来创建带时间戳的独立运行目录。
def new_run_dir(base="/content/runs"):
os.makedirs(base, exist_ok=True)
ts = datetime.now().strftime("%Y%m%d-%H%M%S")
rid = ''.join(random.choices(string.ascii_lowercase + string.digits, k=5))
path = os.path.join(base, f"run_{ts}_{rid}")
os.makedirs(path)
return path
第五步:核心 OCR 处理函数
这个函数是 Gradio 应用的核心逻辑,它负责处理图像、调用模型、并整理输出。
def gr_ocr(image, mode, custom_prompt, base_size, image_size, crop_mode):
img = image.convert("RGB")
if max(img.size) > 2000:
s = 2000 / max(img.size)
img = img.resize((int(img.width*s), int(img.height*s)), Image.LANCZOS)
run_dir = new_run_dir()
img_path_proc = os.path.join(run_dir, "input.png")
img.save(img_path_proc, optimize=True)
if mode == "Custom Prompt" and custom_prompt.strip():
prompt = custom_prompt.strip()
else:
prompt = DEMO_MODES[mode]["prompt"]
t0 = time.time()
try:
with torch.inference_mode():
_ = model.infer(
tok,
prompt=prompt,
image_file=img_path_proc,
output_path=run_dir,
base_size=base_size,
image_size=image_size,
crop_mode=crop_mode,
save_results=True,
test_compress=True
)
except ZeroDivisionError:
print(" [Patched] Division by zero in compression ratio (valid_img_tokens==0). Ignored.")
dt = time.time() - t0
result_file = os.path.join(run_dir, "result.mmd")
if not os.path.exists(result_file):
result_file = os.path.join(run_dir, "result.txt")
result = "[No text extracted]"
if os.path.exists(result_file):
with open(result_file, "r", encoding="utf-8") as f:
result = f.read().strip() or "[No text extracted]"
boxed_path = os.path.join(run_dir, "result_with_boxes.jpg")
boxed_img = Image.open(boxed_path) if os.path.exists(boxed_path) else None
stats = f"""
**{dt:.1f}s** | Image: {img.size[0]}×{img.size[1]} px
**Output directory:** {run_dir}
"""
return result, stats, boxed_img
第六步:构建 Gradio 界面
最后,我们用 Gradio 的 Blocks API 来搭建一个交互界面,把所有功能整合在一起。
# (此处省略 DEMO_MODES 字典的定义,原文太长,功能是预设不同的 prompt)
DEMO_MODES = {
"Document ➔ Markdown": {
"prompt": "<image>\n<|grounding|>Convert the document to markdown.",
"desc": "Extracts full document text as Markdown, preserving structure (headings, tables, lists, etc.).",
"base_size": 1024, "image_size": 640, "crop_mode": False
},
"Chart Deep Parsing": {
"prompt": "<image>\nParse all charts and tables. Extract data as HTML tables.",
"desc": "Extracts tabular/chart data into HTML tables.",
"base_size": 1024, "image_size": 640, "crop_mode": False
},
# ... 其他模式
"Custom Prompt": {
"prompt": "",
"desc": "Provide your own custom prompt for flexible OCR or parsing.",
"base_size": 1024, "image_size": 640, "crop_mode": False
}
}
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown("""
<div style="text-align:center;">
<h1>DeepSeek-OCR Demo</h1>
</div>
""")
with gr.Row():
with gr.Column():
# ... 此处省略左侧输入组件(图片上传、模式选择等)的 Gradio 代码
image_input = gr.Image(type="pil", label="Upload Document/Image", height=350)
mode = gr.Radio(choices=list(DEMO_MODES.keys()), value="Document ➔ Markdown", label="Select Capability to Test")
desc = gr.Markdown(DEMO_MODES["Document ➔ Markdown"]["desc"])
custom_prompt = gr.Textbox(label="Custom Prompt", visible=False)
process_btn = gr.Button("Process Image", variant="primary")
with gr.Column():
# ... 此处省略右侧输出组件(文本框、状态、带框图片)的 Gradio 代码
ocr_output = gr.Textbox(label="Extracted Content", lines=22, show_copy_button=True)
status_out = gr.Markdown("_Process an image to see stats and output dir_")
boxed_output = gr.Image(label="Result with Bounding Boxes", type="pil")
def update_mode(selected):
d = DEMO_MODES[selected]
return d["desc"], gr.update(visible=selected=="Custom Prompt"), d["base_size"], d["image_size"], d["crop_mode"]
mode.change(update_mode, inputs=mode, outputs=[desc, custom_prompt, base_size, image_size, crop_mode])
process_btn.click(
gr_ocr,
inputs=[image_input, mode, custom_prompt, base_size, image_size, crop_mode],
outputs=[ocr_output, status_out, boxed_output]
)
demo.launch(share=True, debug=True)
现在,我们的测试平台准备就绪。让我们开始动真格的。
场景一:图表数据深度解析
图表数据提取是大多数 OCR 和视觉模型的痛点。我用了两种典型的图表来测试:一个标准的条形统计图和一个充满技术指标的复杂金融分析图。

评测结果:
DeepSeek-OCR 为每个图表都返回了一个 HTML 表格,单元格对应图中的类别、数值和标签。
- 优点:模型确实捕捉到了图表中所有可见的文本和结构,并以机器可读的 HTML 表格格式输出。这保留了表格的逻辑,甚至能处理复杂的金融图表,尝试将每个数字和标签都制成表格。
- 缺点:原始输出非常冗长,充满了
<td>和<tr>标签,一眼看过去很难解读。在复杂的图表中,模型有时会重复条目或丢失高层视觉结构,导致输出的表格充满了重复的 “BUY”/“SELL” 信号和数值。
我的看法是,这个功能更适合作为数据管道的输入,需要进行二次处理才能方便人类阅读或直接导入 Pandas/Excel。它是一个不错的图表数字化工具,但离“即开即用”还有点距离。
场景二:化学式提取
接下来,我测试了模型处理化学信息的能力,包括文本公式和图形化的分子结构。
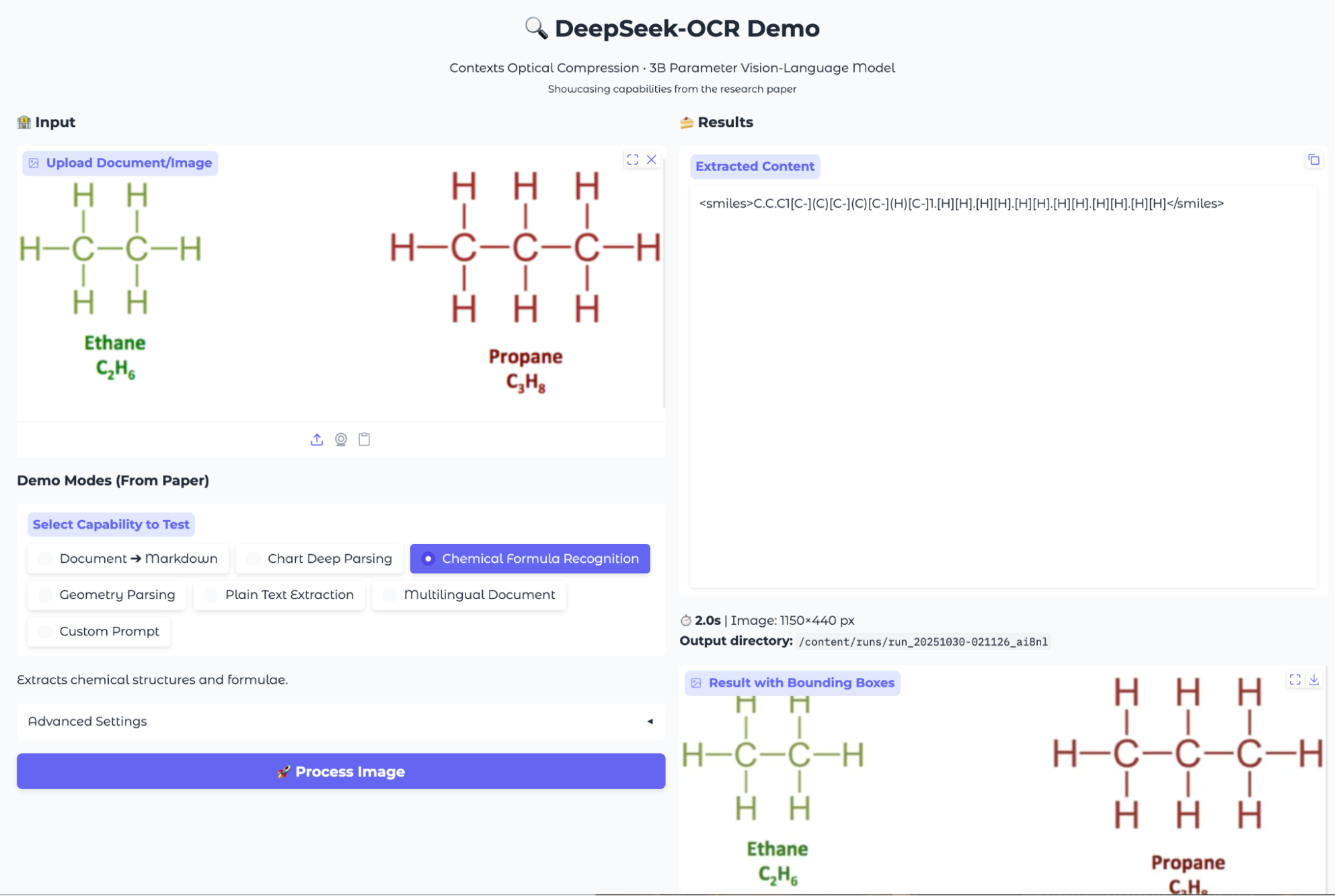
评测结果:
- 文本公式提取:对于包含化学名称和分子式的文本(如“葡萄糖:C₆H₁₂O₆”),模型能准确地转录。但同样,输出是原始的 HTML 表格代码,结构化但可读性一般。
- 分子结构识别:对于包含化学结构图的图片,模型会尝试生成对应的 SMILES 字符串。它成功识别出这是化学结构,但生成的 SMILES 字符串并不总是化学上有效的,这表明在解析更复杂的分子图像时能力有限。
总的来说,这个功能为化学数据数字化提供了一个快速的途径,但要获得可靠的结果,特别是对于复杂的分子结构,还需要进一步的优化。
场景三:手写文本识别
手写识别是 OCR 的经典难题。我上传了一张在横线纸上手写的化学物质清单。
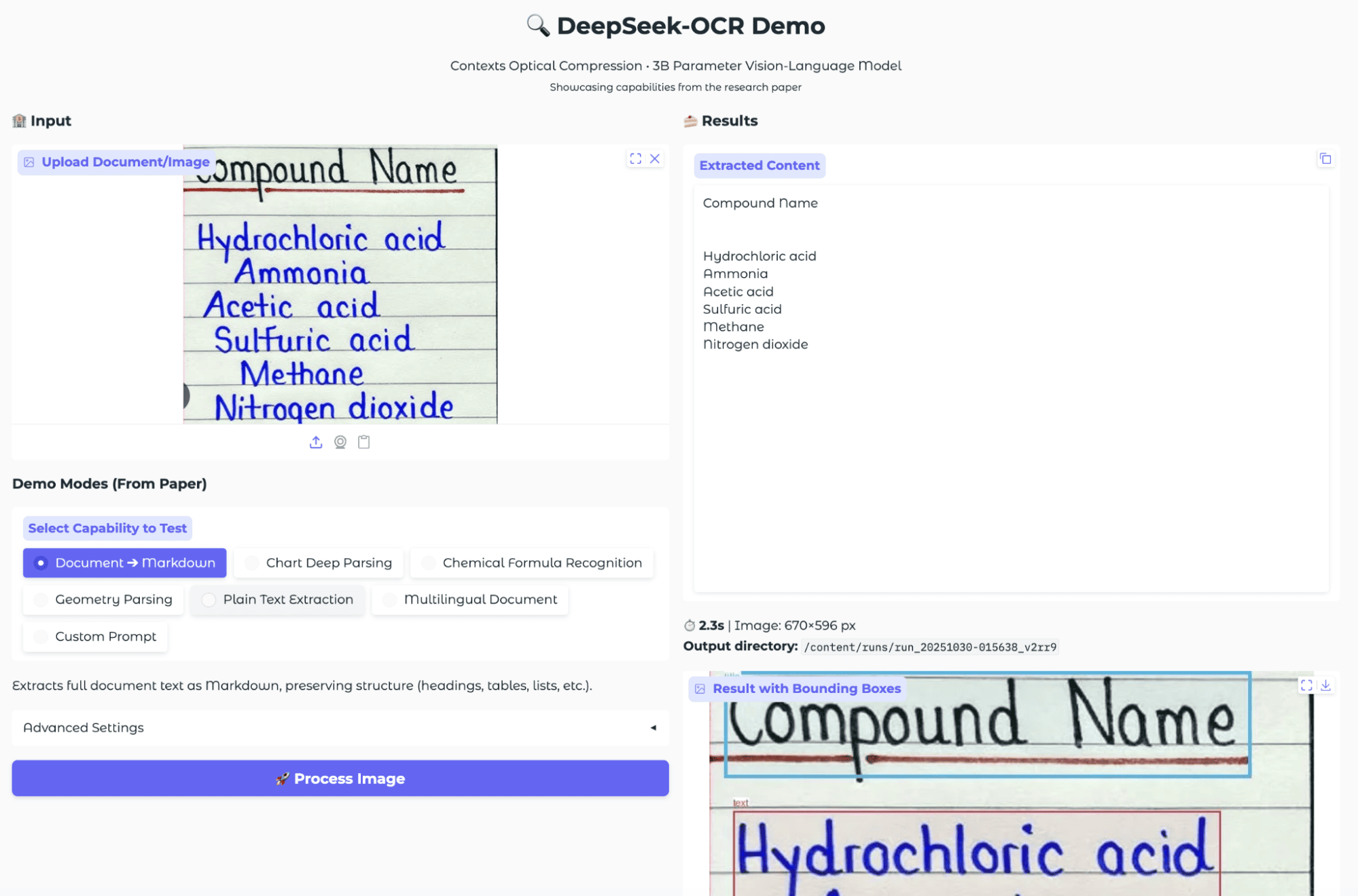
评测结果:
结果出乎意料地好。模型不仅准确识别了所有手写文字,还很好地保留了原始的列表结构。它识别出了标题,并将每个化合物单独列为一行。从带边界框的输出图上也能看到,模型准确地定位了每一行文本。对于手写内容,这个表现非常扎实。
场景四:数学公式提取
我上传了一张包含多个复杂 LaTeX 风格数学公式的图片,来评估模型是否能准确地提取和格式化这些表达式。
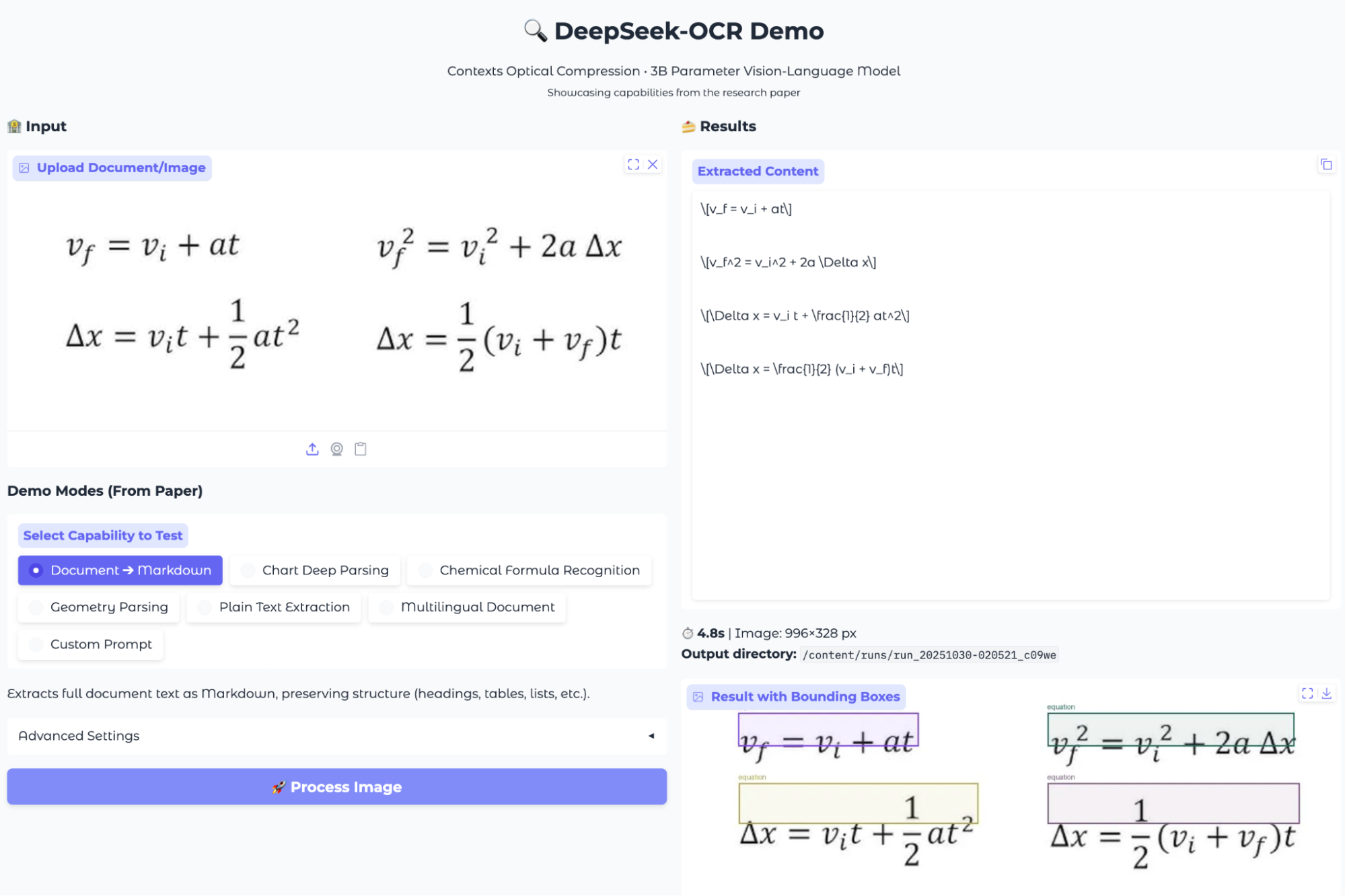
评测结果:
DeepSeek-OCR 成功检测并提取了图片中的所有四个方程,并将其转换为 LaTeX 字符串。输出结果结构清晰,每个方程都以标准的 LaTeX 格式单独成行。它正确地使用了 \frac 等命令来表示分数,结果可以直接在文档中复用。这是一个非常实用的功能,特别对学术和研究领域。
场景五:表格提取
表格提取是 OCR 最常见的应用之一。我用了一张包含多国经济数据的结构化表格图片来测试。
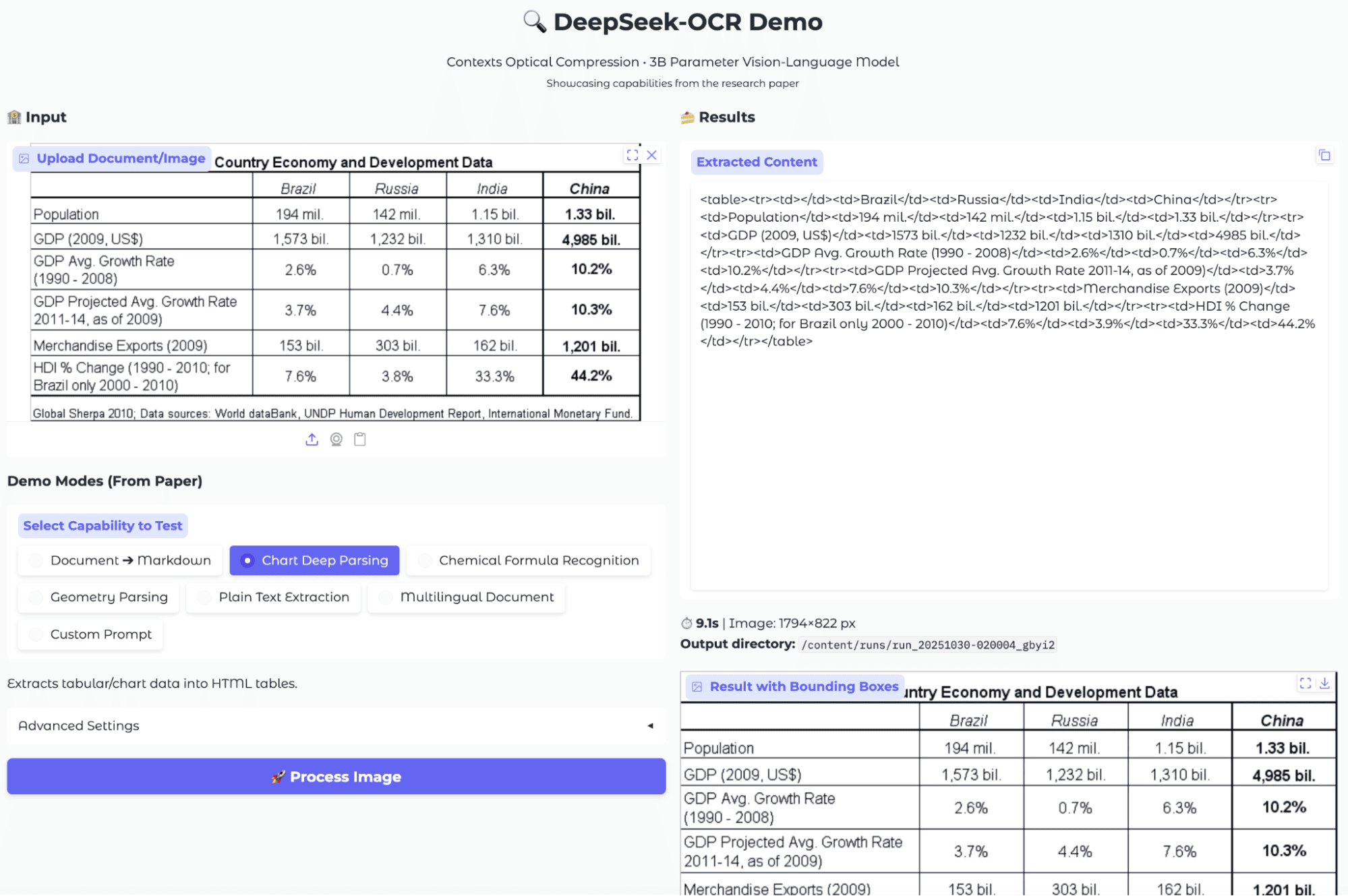
评测结果:
模型成功将视觉表格转换为了 HTML 表格结构。边界框输出也确认模型准确地识别和分割了整个表格区域。对于简单的结构化表格,它的表现是可靠的。但和图表提取一样,原始的 HTML 输出对人类用户不太友好,需要后处理才能方便地用于数据分析。
场景六:网络 Meme 图识别
为了测试模型在非典型场景下的表现,我用了一张经典的 Meme 图,上面有大号白色文字叠加在复杂的电影背景上。
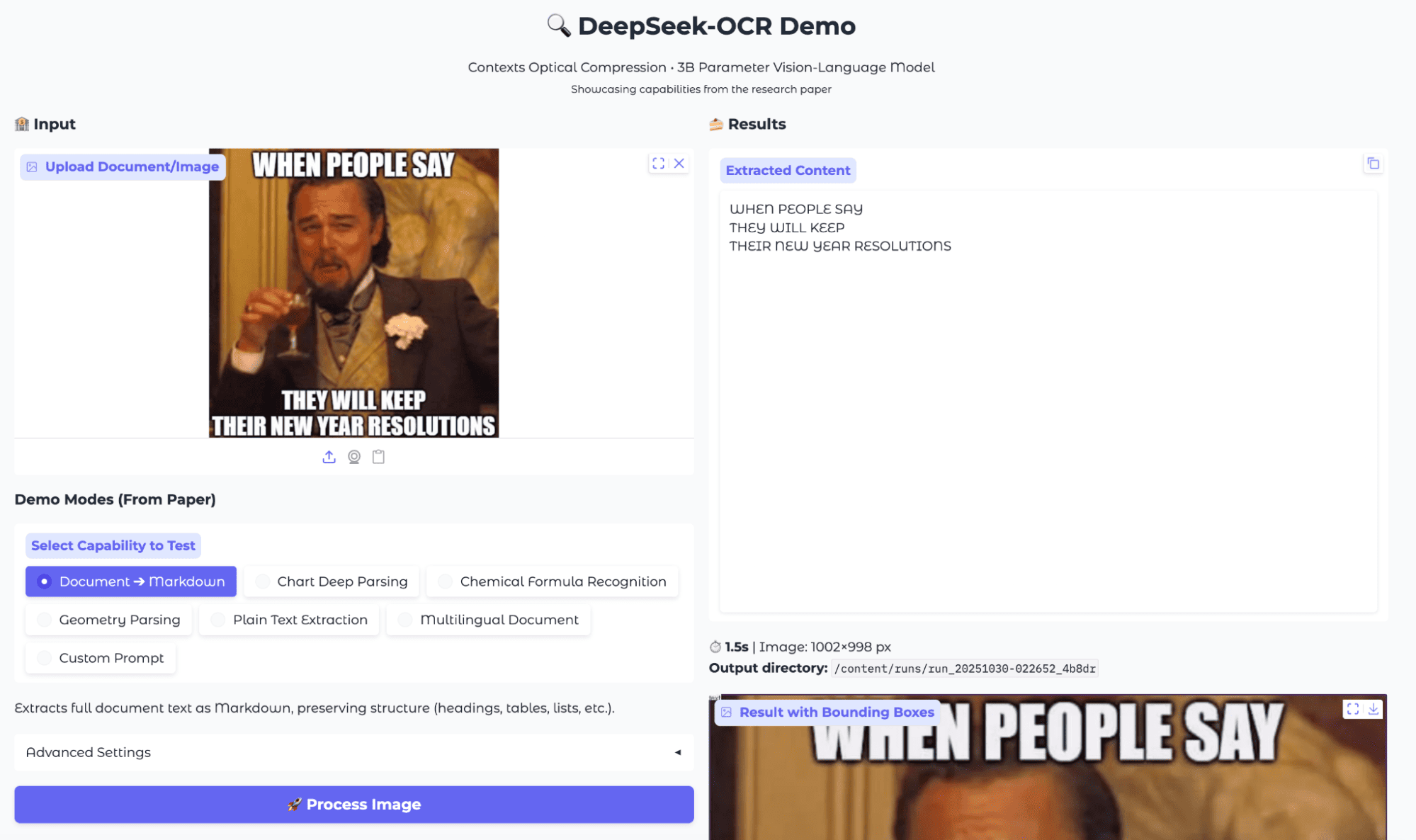
评测结果:
出人意料地稳健。即使背景复杂,字体也很特殊,模型还是准确地捕捉了所有单词,顺序正确,没有拼写错误。虽然没有复杂的结构化信息,但这种纯文本提取对于内容审核、情感分析或基于文本的 Meme 搜索等下游任务已经足够好用了。
场景七:多语言 OCR
DeepSeek-OCR 的一个亮点是支持多语言文本提取。我用了一张包含中文的真实街景照片,以及一个混合了中日韩三种语言的样本进行测试。
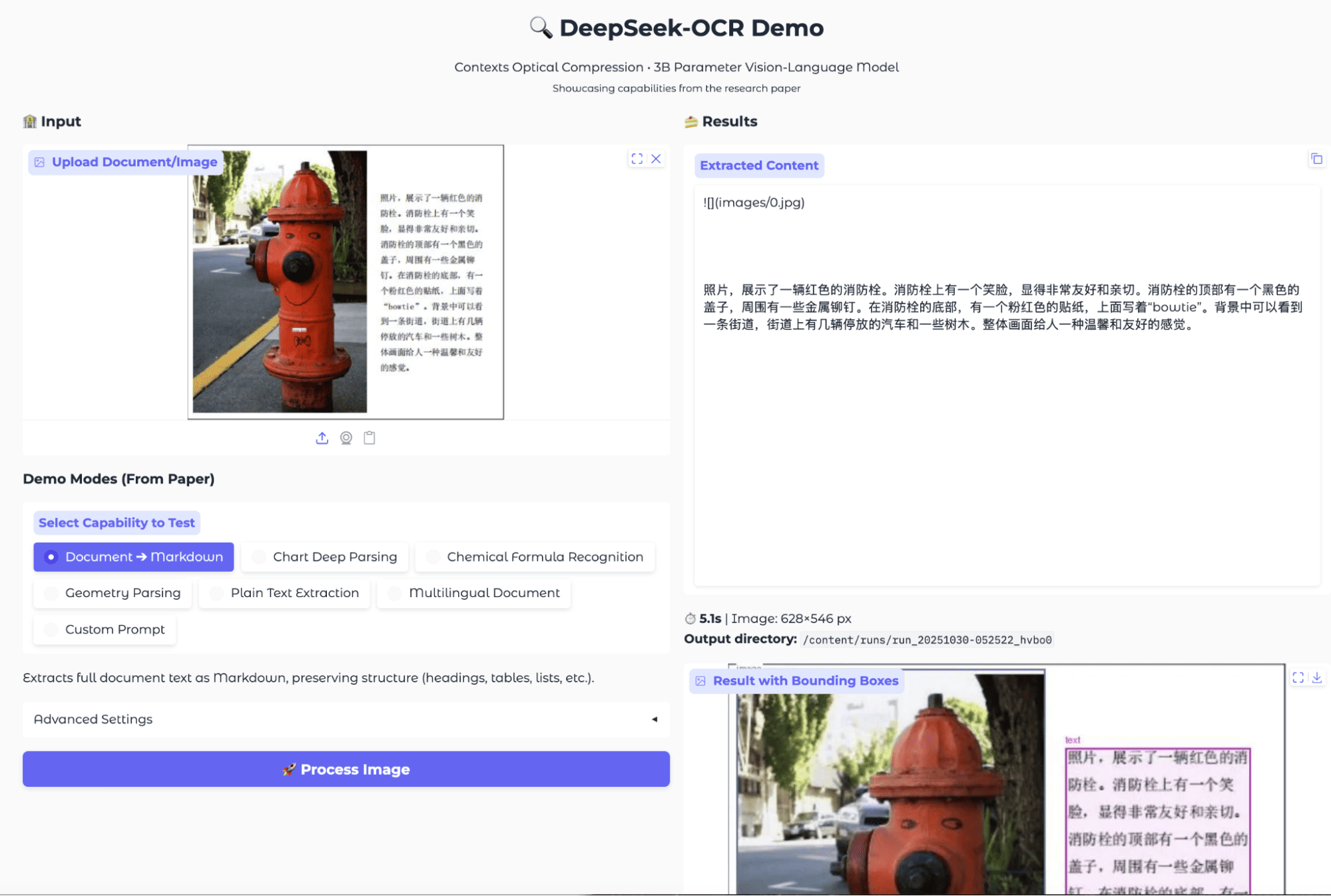
评测结果:
模型准确地检测并提取了非英语脚本。对于街景照片,它识别出了整段中文。对于混合语言样本,它正确地分离并标记了中文、日文和韩文部分。
不过有两个要注意的地方:
- 处理速度:再处理多语言时,速度明显比单语言或表格提取慢得多,可能是因为脚本检测和解码的复杂性更高。
- 偶尔出错:有时输出会包含一些冗余的 Token 或格式错误。
尽管有这些小问题,它在多语言 OCR 方面的能力依然很强,能可靠地处理混合脚本和真实世界的照片。
最终结论
DeepSeek-OCR 确实在传统 OCR 和现代多模态大模型之间架起了一座桥梁。它最大的优势是通用性——用一个模型就能处理扫描文档、复杂图表、数学公式、化学结构,甚至手写体和 Meme 图。
当然,它也不是完美的。图表和表格的输出可能过于冗长,化学结构识别有时会失败,多语言处理速度也偏慢。对于复杂的视觉布局,可能还需要一些后处理工作。
但对于需要高级 OCR 功能的研究人员、学术工作者和开发者来说,DeepSeek-OCR 已经比传统工具好用太多了。它在处理复杂文档方面表现的非常好,特别是在需要进行快速原型设计或处理非纯文本数据时,它是一个非常值得考虑的工具。
关于
关注我获取更多资讯

