检索增强生成(RAG)是当下 AI 领域最热门的技术之一。它把信息检索的精准性和大语言模型的推理能力结合起来,让模型的回答既有理有据,又切中要害。从智能客服到企业内部知识库,RAG 的应用场景非常广阔。
但问题是,跑通一个 Jupyter Notebook 里的 RAG 原型,和把它变成一个能稳定、高效地提供服务的线上产品,完全是两码事。后者才是真正的挑战。
这篇文章,我们就来聊聊怎么填上这个坑。我将带你走一遍完整的流程:先用 LangChain 快速搭建一个 RAG 管道,然后用 FastAPI 把它封装成一个健壮的 API 服务,最后再聊聊如何把它部署到生产环境。
RAG 的核心逻辑拆解
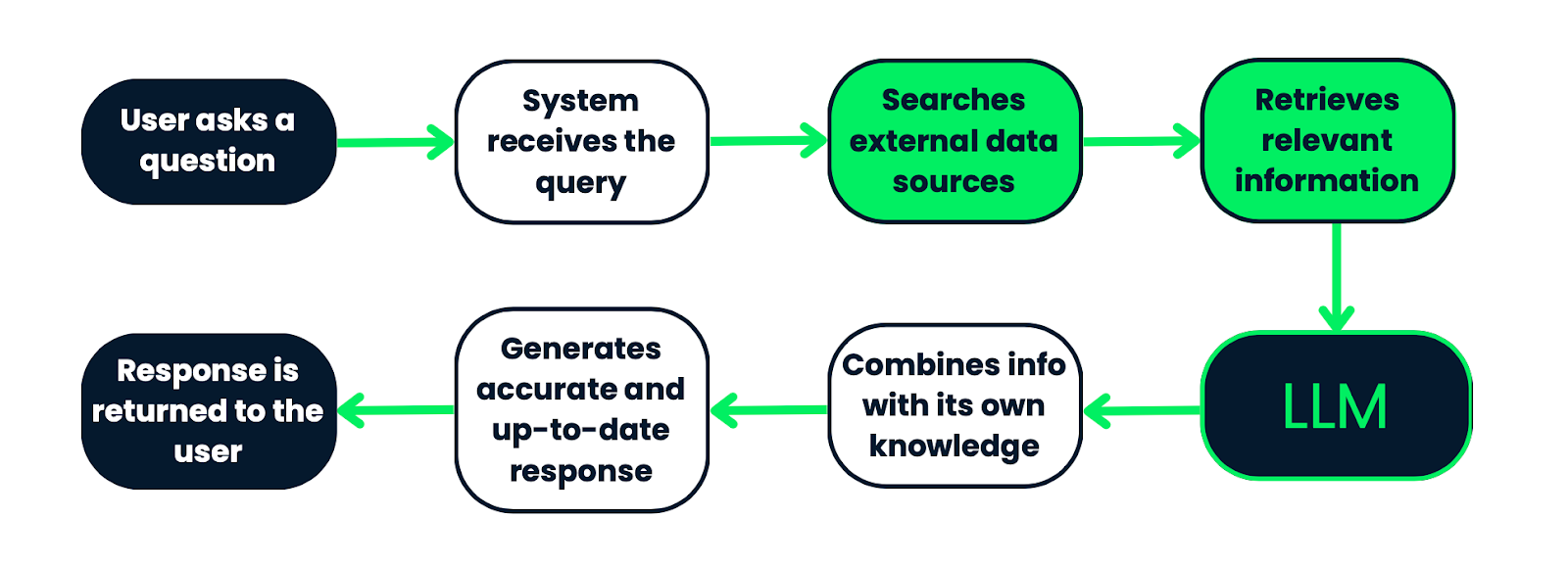
在我们深入代码之前,先快速过一下 RAG 系统的工作流。简单来说,当用户提出一个问题时,系统并不会直接把问题丢给大模型。它会执行以下几个步骤:
-
加载与切分 (Load & Split):首先,系统需要一个知识库。这可能是公司的内部文档、产品手册或者一堆 PDF 文件。
Document Loaders负责把这些不同格式的文档加载进来,然后Text Splitter会把长文档切成一个个更小的、便于处理的文本块(Chunks)。 -
向量化与索引 (Embed & Index):接下来,系统会用一个 Embedding 模型将每个文本块转换成一串数字,也就是向量(Vector)。这些向量代表了文本的语义信息。然后,所有的文本块向量会被存入一个专门的
Vector Store(向量数据库)里,并建立索引,方便后续快速检索。 -
检索 (Retrieve):当用户提问时,系统会先将用户的问题也转换成一个向量。然后,它会拿着这个查询向量去向量数据库里,通过相似度计算,找出与问题最相关的几个文本块。这个过程就像在图书馆里根据关键词快速找到相关的几本书。
-
生成 (Generate):最后一步,系统会把用户原始的问题和上一步检索到的相关文本块,一起打包发给大语言模型(LLM)。LLM 会基于这些补充信息,生成一个更准确、更有依据的回答。
整个流程确保了模型的回答不是凭空捏造,而是基于我们提供给它的真实数据。
动手实践:用 LangChain 搭建 RAG 管道
理论讲完了,我们来动手写代码。
环境准备
首先,确保你的 Python 版本是 3.10 或更高。然后,创建一个虚拟环境是个好习惯,可以避免包依赖冲突。
python3 -m venv ragenv
source ragenv/bin/activate # Linux/Mac
# ragenv\Scripts\activate # Windows
接着,安装我们需要的库。
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu python-dotenv
这里简单说明一下它们各自的作用:
fastapi: 我们用来构建 API 的 web 框架。uvicorn: 一个 ASGI 服务器,用来运行 FastAPI 应用。langchain&langchain-community: 核心的 RAG 框架。openai&langchain-openai: 用于调用 OpenAI 的模型和 Embedding 服务。faiss-cpu: 一个由 Facebook 开发的高效向量相似度搜索库,这里我们用它做本地向量存储。python-dotenv: 用来管理环境变量,比如 API 密钥。
为了安全地存放你的 OpenAI API 密钥,在项目根目录下创建一个 .env 文件,并写入:
OPENAI_API_KEY=your-openai-api-key
构建完整的 RAG 查询脚本
下面这个脚本整合了从加载数据到最终查询的完整 RAG 流程。为了方便演示,我们假设有一个 data/my_document.txt 文件,里面包含了一些关于北极熊的科普知识。
# rag_script.py
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# 加载 .env 文件中的环境变量
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# 1. 加载文档
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# 2. 切分文档
# chunk_size 定义每个块的大小,overlap 定义块之间的重叠部分
# 重叠是为了保证上下文的连续性
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# 3. 创建 Embeddings 和向量存储
# 使用 OpenAI 的 Embedding 模型
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# 使用 FAISS 作为向量数据库,从文档块和 embedding 模型创建
vector_store = FAISS.from_documents(document_chunks, embeddings)
# 4. 创建检索器
# as_retriever 会将向量数据库转换为一个可以检索文档的 retriever
retriever = vector_store.as_retriever()
# 5. 初始化 LLM
llm = OpenAI(openai_api_key=openai_api_key)
# 6. 创建 QA 链
# chain_type="stuff" 是最直接的一种方式,它会把所有检索到的文档内容塞进 prompt
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 7. 执行查询
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# 打印结果
print(response)
运行这个脚本,你就能在终端看到基于文档内容生成的答案了。这个脚本验证了我们的 RAG 管道是通的,但它离一个能用的服务还差很远。
服务化:用 FastAPI 封装 RAG 能力
现在,我们要把上面的脚本改造成一个 API 服务。为什么需要 API?因为 API 提供了一个标准的、可供其他应用(比如前端网页、移动 App 或其他后端服务)调用的接口。
我们的目标是创建一个 /query/ 端点,用户可以通过 GET 请求发送一个查询字符串,然后 API 会返回 RAG 系统的回答。
为了让项目结构更清晰,我们创建几个文件:
main.py: FastAPI 应用的入口。rag.py: 封装 RAG 核心逻辑。endpoints.py: 定义 API 路由。
1. 重构 RAG 核心逻辑 (rag.py)
我们将之前的脚本逻辑封装成两个函数:一个用于初始化 RAG 系统,另一个用于处理异步查询。这样做不仅代码更整洁,也方便复用和测试。
# rag.py
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
llm = OpenAI(openai_api_key=openai_api_key)
# 这个 funtion 负责设置 RAG 管道,它只做一次数据处理和索引
def setup_rag_system():
loader = TextLoader('data/my_document.txt')
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vector_store = FAISS.from_documents(document_chunks, embeddings)
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 5})
return retriever
# 异步函数,处理用户的查询
async def get_rag_response(query: str, retriever):
# 这里不再每次都重新构建索引,而是直接使用传入的 retriever
retrieved_docs = retriever.get_relevant_documents(query)
context = "\n".join([doc.page_content for doc in retrieved_docs])
# 构建一个清晰的 prompt
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# 调用 LLM 生成回答
# 注意:llm.generate 需要一个 prompts 列表
generated_response = llm.generate(prompt)
return generated_response
注意:在实际生产环境中,setup_rag_system 这个函数应该在服务启动时调用一次,而不是每次请求都调用。我们稍后会在 FastAPI 的启动事件中处理这个问题,但为了简化,这里先这么写。
2. 定义 API 端点 (endpoints.py)
这个文件负责定义 API 的路由。它会接收 HTTP 请求,调用 rag.py 中的逻辑,然后返回 JSON 格式的响应。
# endpoints.py
from fastapi import APIRouter, HTTPException
from rag import get_rag_response, setup_rag_system
router = APIRouter()
# 在应用启动时,就初始化好 retriever
# 这样就不必在每次请求时都重新加载和索引文档了
retriever = setup_rag_system()
@router.get("/query/")
async def query_rag_system(query: str):
if not query:
raise HTTPException(status_code=400, detail="Query parameter is required.")
try:
# 使用 await 调用我们的异步 RAG 函数
response = await get_rag_response(query, retriever)
# 提取并返回可读的文本结果
# .generations[0][0].text 是从 OpenAI 返回的复杂结构中提取文本的方式
text_response = response.generations[0][0].text.strip()
return {"query": query, "response": text_response}
except Exception as e:
# 捕获异常,返回 500 错误
raise HTTPException(status_code=500, detail=str(e))
FastAPI 的 async 支持非常关键。RAG 查询涉及到 I/O 操作(比如调用 OpenAI API),使用异步可以让服务器在等待这些操作完成时,去处理其他请求,从而大大提高并发性能。这是它比 Flask 这类传统同步框架的的的优势之一。
3. 组合应用入口 (main.py)
最后,main.py 文件非常简单,它只是创建 FastAPI 应用实例,并把 endpoints.py 中定义的路由包含进来。
# main.py
from fastapi import FastAPI
from endpoints import router
app = FastAPI(
title="RAG System API",
description="An API for querying a RAG system built with LangChain and FastAPI.",
version="1.0.0"
)
app.include_router(router)
启动与测试
现在,在终端中运行 Uvicorn 来启动我们的服务:
uvicorn main:app --reload
--reload 参数非常有用,它会在你修改代码后自动重启服务。
服务启动后,打开浏览器访问 http://127.0.0.1:8000/docs。你会看到 FastAPI 自动生成的 Swagger UI 交互式 API 文档。你可以在这里直接测试 /query/ 端点,非常方便。
输入一个问题,比如 “Are polar bears in danger?",然后点击 “Execute”,你就能看到 API 返回的 JSON 结果了。
迈向生产:部署策略探讨
API 能跑起来只是第一步,要让它在生产环境中稳定运行,我们还需要考虑部署。
容器化:Docker 的价值
把应用打包成 Docker 镜像几乎是现代部署的标配。Docker 容器能确保你的应用在任何地方都以完全相同的环境运行,彻底告别 “在我电脑上是好的啊” 的窘境。
创建一个 Dockerfile:
# 使用官方 Python 镜像
FROM python:3.11-slim
# 设置工作目录
WORKDIR /app
# 复制依赖文件
COPY requirements.txt requirements.txt
# 安装依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制项目代码
COPY . .
# 暴露端口
EXPOSE 8000
# 启动命令
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
有了这个文件,你就可以构建并运行你的 Docker 容器了。
云端部署选项
一旦应用被容器化,你就可以把它部署到任何支持容器的云平台。
- AWS: 可以使用 Amazon ECS 或 EKS(Kubernetes)来管理容器集群,或者用更简单的 AWS App Runner、Elastic Beanstalk。
- Google Cloud (GCP): Google Cloud Run 是一个非常棒的无服务器平台,可以根据流量自动伸缩容器实例。GKE(Google Kubernetes Engine)则提供了更强大的容器编排能力。
- Microsoft Azure: Azure App Service 和 Azure Kubernetes Service (AKS) 提供了类似的功能。
选择哪个平台取决于你的团队技术栈、预算和对基础设施的控制需求。但无论如何,在云上部署能让你获得高可用性、可扩展性和强大的监控能力。
结语
我们从一个简单的 RAG 脚本出发,用 FastAPI 将其升级为一个高性能的异步 API,并探讨了如何通过 Docker 和云平台将其推向生产。
这个过程其实是很多 AI 应用从原型走向产品的必经之路。LangChain 帮我们解决了 RAG 的复杂逻辑,而 FastAPI 则为我们提供了坚实的工程化基座。
当然,这只是个开始。你还可以继续优化,比如:
- 使用更强大的向量数据库(如 Pinecone, Weaviate)。
- 对检索结果进行重排(Re-ranking)以提高精度。
- 为 API 增加认证、日志和监控。
希望这篇文章能为你提供一个清晰的路线图。动手去构建你自己的 RAG 应用吧!
关于
关注我获取更多资讯

