大型语言模型(LLM)在理解和生成文本方面表现出色,但它们并非无所不知。为了让 LLM 在特定应用场景中发挥作用,通常需要为其提供外部知识。检索增强生成(Retrieval Augmented Generation, RAG)是一种流行的解决方案,它允许 LLM 在生成响应之前,从外部知识库中检索相关信息。
然而,传统的 RAG 方法在处理和编码信息时,常常会丢失重要的语境(context),导致检索效果不佳,甚至完全失败。为了解决这一核心问题,Anthropic 推出了创新的**“语境化检索”(Contextual Retrieval)**技术,通过在信息处理阶段融入更多的语境信息,显著提升了 RAG 系统的检索准确性。
RAG 概述与传统挑战
RAG 基本原理
对于超出 LLM 上下文窗口限制的大型知识库,RAG 是一种非常实用的解决方案。其传统预处理步骤包括:
- 文档分块(Chunking): 将长文档(语料库)分割成较小的文本块(通常为几百个 Token)。
- 嵌入(Embedding): 使用嵌入模型(embedding model)将这些文本块转换为高维向量(vector embeddings)。
- 向量数据库存储: 将这些嵌入存储在向量数据库中,以便进行语义相似性搜索。
在运行时,RAG 系统会根据用户查询,从向量数据库中查找语义上最相关的文本块,并将其作为附加语境添加到 LLM 的提示(prompt)中,引导 LLM 生成更准确、信息更丰富的响应。
BM25:词汇匹配的补充
除了基于语义相似性的向量检索,**BM25(Best Match 25)**是一种基于词汇匹配的排名函数,它在处理包含唯一标识符或特定技术术语的查询时表现出色。例如,当用户查询“错误代码 TS-999”时,BM25 能够直接通过精确字符串匹配找到包含该代码的文本,而单纯的嵌入模型可能只会找到一些通用性的错误代码信息。
因此,许多 RAG 系统会结合嵌入和 BM25 的优势,采用混合检索策略:
- 为文本块同时创建 TF-IDF 编码(用于 BM25)和语义嵌入。
- 分别使用 BM25 查找精确匹配的顶级块和使用嵌入查找语义相似的顶级块。
- 对检索结果进行合并和去重(通常通过排名融合技术)。
- 将最相关的 K 个(Top-K)文本块添加到提示中,用于 LLM 生成响应。
传统 RAG 的局限:语境破坏
尽管混合检索方法能有效扩展到大型知识库,但传统 RAG 系统存在一个关键限制:它们在分块时常常破坏了语境。 当一个文本块从原始文档中被孤立出来时,其原本的含义可能变得模糊。例如,一个关于“公司收入增长 3%”的文本块,在脱离上下文时,我们无法得知是哪家公司、哪个季度。这种语境信息的丢失极大地影响了检索的准确性。
引入语境化检索(Contextual Retrieval)
为了解决传统 RAG 的语境丢失问题,Anthropic 提出了语境化检索。其核心思想是在对文本块进行嵌入和创建 BM25 索引之前,为每个文本块添加一段**“块特定解释性语境”(chunk-specific explanatory context)**。
示例对比:
- 原始文本块: “The company’s revenue grew by 3% over the previous quarter.”
- 语境化文本块: “This chunk is from an SEC filing on ACME corp’s performance in Q2 2023; the previous quarter’s revenue was $314 million. The company’s revenue grew by 3% over the previous quarter.”
通过在文本块前缀加入这些描述性语境,检索系统在处理查询时就能更好地理解每个文本块的实际含义和来源,从而显著提高检索的相关性。
如何实现语境化检索?
手动为每个文本块添加语境显然是不切实际的。Anthropic 利用其自家的 Claude 大模型自动生成这些语境。
Claude 3 Haiku 生成语境的提示(Prompt)示例:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
这段提示将完整的文档(WHOLE_DOCUMENT)和待处理的文本块(CHUNK_CONTENT)同时提供给 Claude 3 Haiku 模型,并要求它生成一段简洁的语境描述(通常 50-100 个 Token),用于辅助检索。
生成的语境文本会在嵌入和创建 BM25 索引前被预置到原始文本块中。
预处理流程图示:
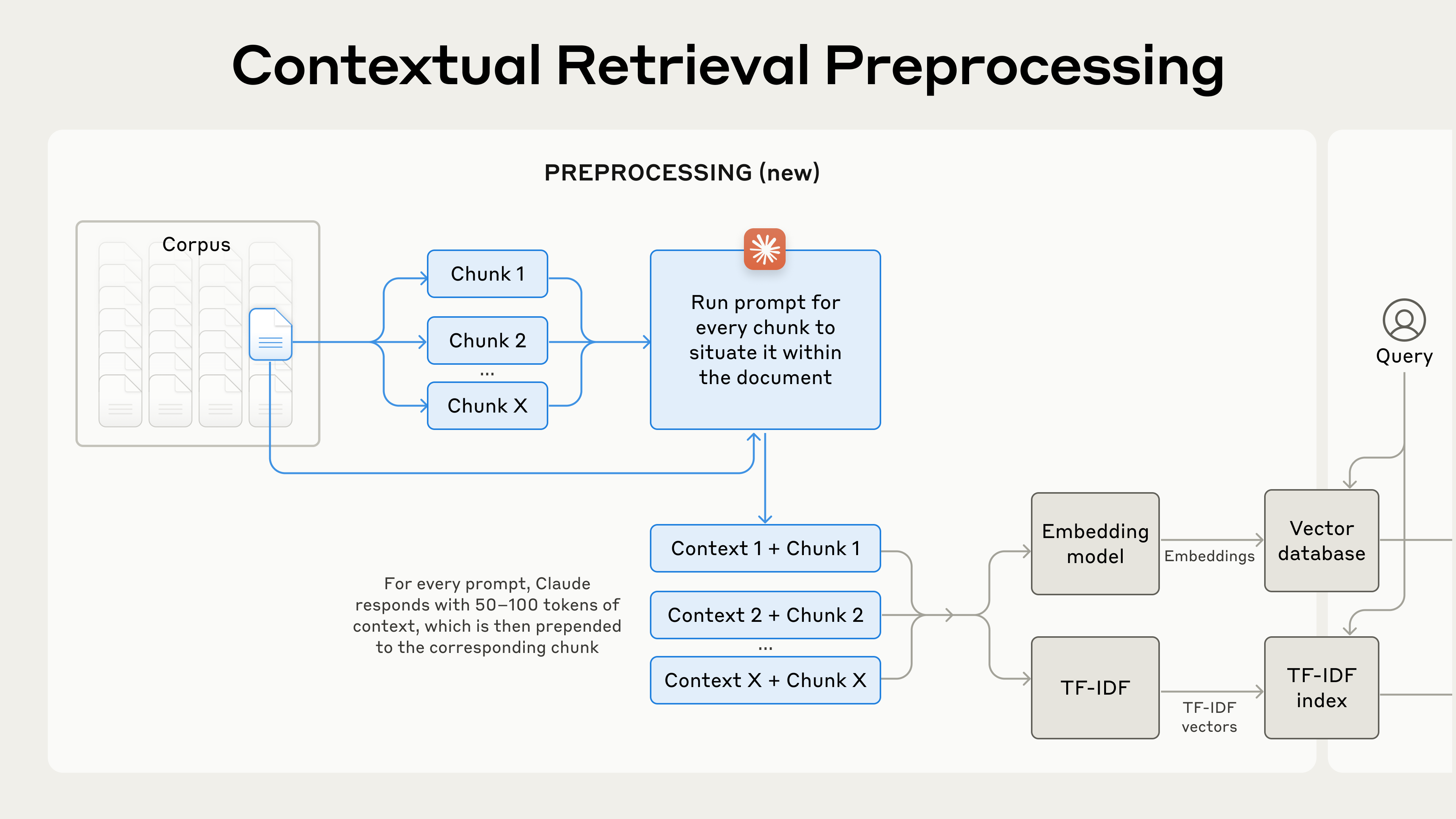 语境化检索是一种提高检索准确性的预处理技术。
语境化检索是一种提高检索准确性的预处理技术。
成本效益
得益于 Claude 的提示缓存(Prompt Caching)功能,语境化检索的成本非常低。文档只需加载到缓存一次,后续生成语境时直接引用缓存内容即可,极大地降低了延迟和成本。根据 Anthropic 的估算,生成语境化文本块的一次性成本仅为每百万文档 Token 1.02 美元。
性能提升:语境化检索的实测效果
Anthropic 在不同知识领域(代码库、小说、ArXiv 论文、科学论文)和多种嵌入模型上对语境化检索进行了广泛实验。结果显示,该技术带来了显著的性能提升:
- 语境化嵌入(Contextual Embeddings): 单独使用语境化嵌入,Top-20 文本块的检索失败率降低了 35%(从 5.7% 降至 3.7%)。
- 语境化嵌入 + 语境化 BM25: 结合语境化嵌入和语境化 BM25,Top-20 文本块的检索失败率更是降低了 49%(从 5.7% 降至 2.9%)。
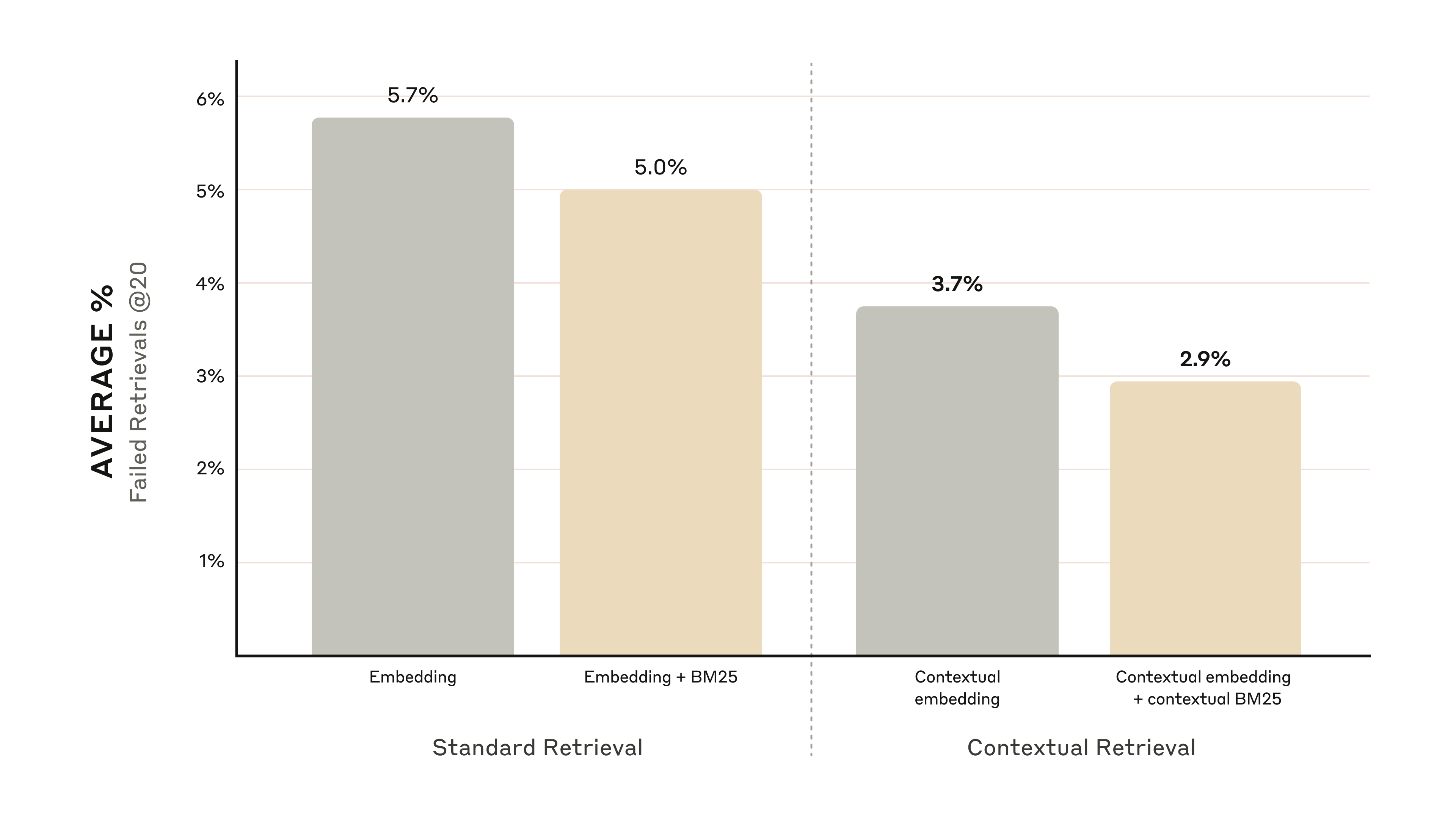 结合语境化嵌入和语境化 BM25 可将 Top-20 文本块检索失败率降低 49%。
结合语境化嵌入和语境化 BM25 可将 Top-20 文本块检索失败率降低 49%。
实施注意事项
Anthropic 在实验中也总结了一些实施经验:
- 文本块边界: 文本块的大小、边界划分和重叠策略会直接影响检索性能。
- 嵌入模型选择: 语境化检索能提升所有测试嵌入模型的性能,其中 Google Gemini 和 Voyage AI 的嵌入模型表现尤为出色。
- 自定义语境化提示: 针对特定领域或用例(例如,法律文档或医学报告),定制生成语境的提示(例如,包含关键词汇表)可以获得更好的效果。
- 文本块数量(Top-K): 增加传递给 LLM 的文本块数量(K 值)可以提高包含相关信息的几率,但过多信息也可能干扰模型。实验发现,Top-20 通常能获得最佳效果。
重排序(Reranking):进一步优化检索
重排序(Reranking)是一种重要的后处理技术,它在初始检索之后对结果进行二次筛选和排序,以确保只有最相关的文本块最终传递给 LLM。在大规模知识库中,初始检索可能会返回数百个相关性不一的文本块,重排序能有效过滤掉低相关性的结果,从而提高 LLM 响应的质量,并降低成本和延迟。
重排序的关键步骤:
- 初始检索: 执行嵌入检索和/或 BM25 检索,获取 N 个(例如 150 个)潜在相关的文本块。
- 重排序: 将这 N 个文本块和用户查询一起传递给一个专门的重排序模型。
- 二次筛选: 重排序模型根据相关性和重要性为每个文本块打分,并选择其中 Top-K 个(例如 20 个)得分最高的文本块。
- 最终提示: 将这 Top-K 个文本块作为语境传递给 LLM,生成最终响应。
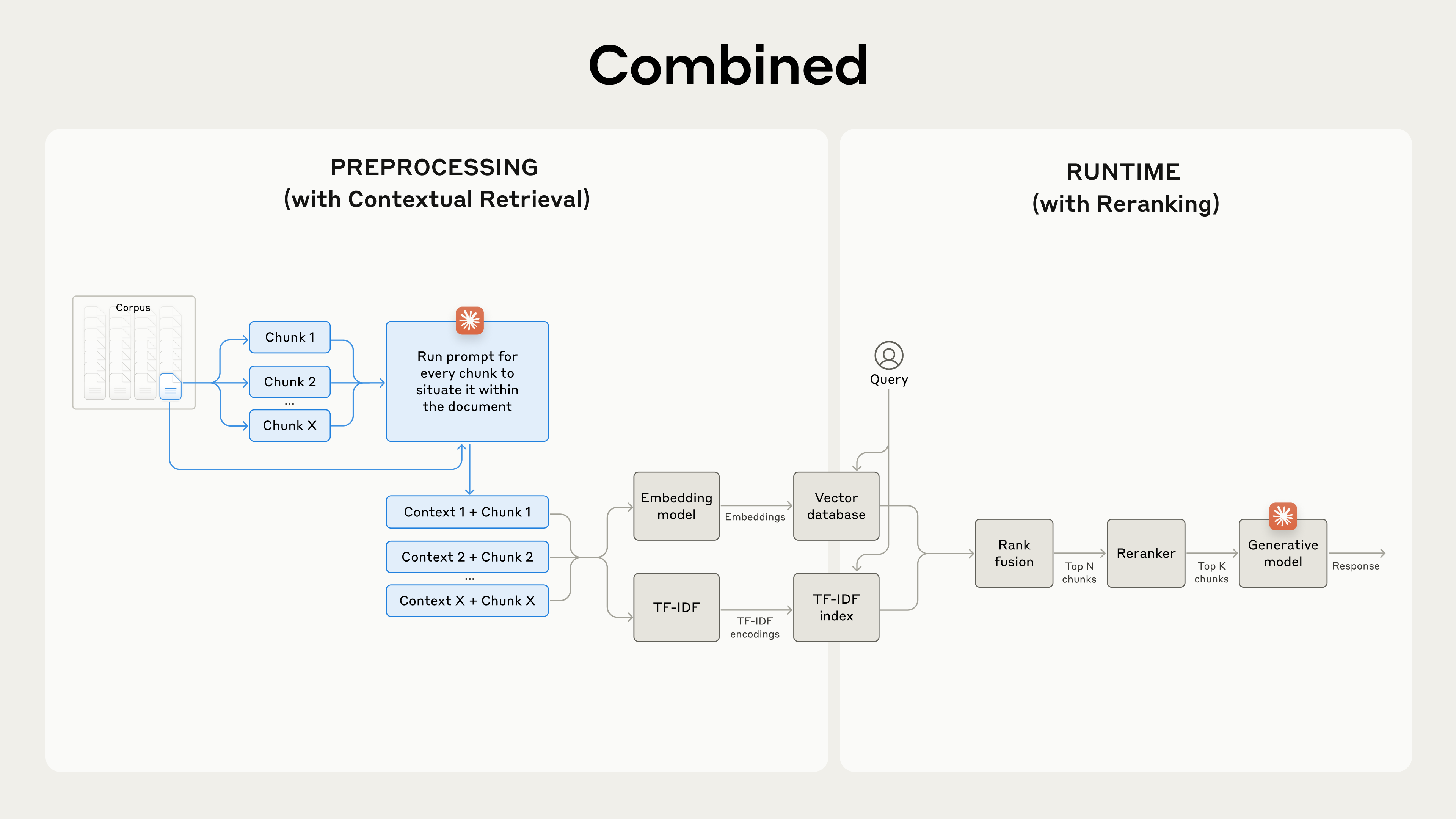 结合语境化检索和重排序以最大化检索准确性。
结合语境化检索和重排序以最大化检索准确性。
结合重排序的性能提升
Anthropic 使用 Cohere 的重排序器进行了测试,结果令人印象深刻:
- 重排序后的语境化嵌入 + 语境化 BM25: 将 Top-20 文本块的检索失败率从 5.7% 大幅降低至 1.9%,提升了 67%。
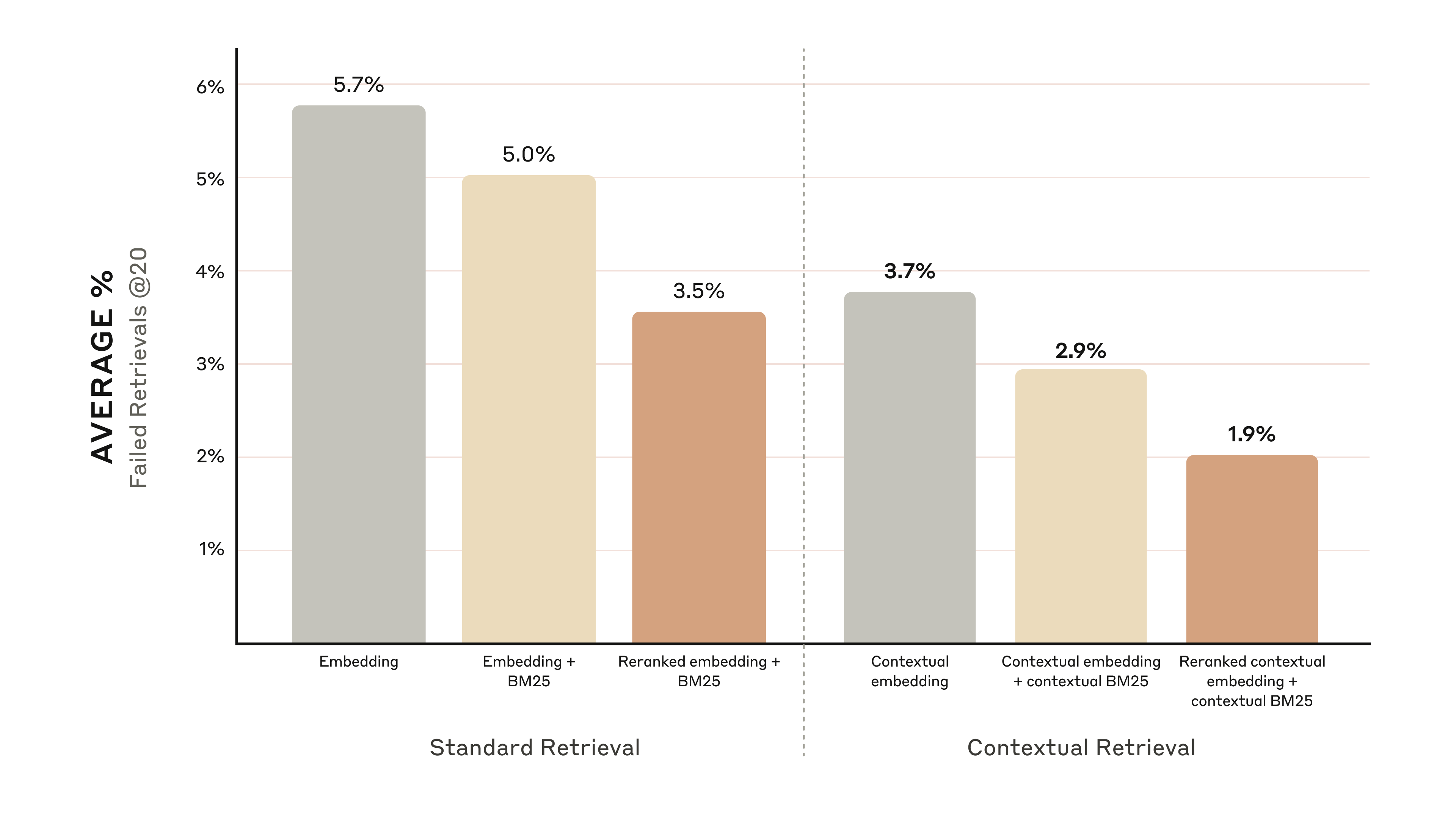 重排序后的语境化嵌入和语境化 BM25 将 Top-20 文本块检索失败率降低 67%。
重排序后的语境化嵌入和语境化 BM25 将 Top-20 文本块检索失败率降低 67%。
成本与延迟考量
重排序会增加额外的运行时步骤,从而引入少量延迟。在实际应用中,开发者需要在性能提升、延迟和成本之间进行权衡,并通过实验找到最适合自身用例的最佳平衡点。
结论:综合优化策略
Anthropic 通过大量的测试和实验,对嵌入模型、BM25 使用、语境化检索、重排序以及 Top-K 结果数量等多种组合进行了深入比较,得出了以下关键结论:
- 嵌入 + BM25 优于单独嵌入: 结合语义检索和词汇匹配的混合方法效果更好。
- 优质嵌入模型: 在测试中,Voyage 和 Gemini 是表现最佳的嵌入模型。
- 合适的 Top-K: 传递 Top-20 个文本块通常比 Top-10 或 Top-5 更有效。
- 语境化检索是关键: 为文本块添加语境信息能大幅提高检索准确性。
- 重排序是强力后处理: 重排序能够进一步优化检索结果。
- 优势叠加: 所有这些优化方法都可以相互叠加,以实现最大的性能提升。要达到最佳效果,建议将语境化嵌入(结合 Voyage 或 Gemini 模型)与语境化 BM25、重排序步骤以及将 20 个文本块添加到提示中相结合。
Anthropic 鼓励开发者通过其提供的 Cookbook 来实验这些先进的方法,解锁 RAG 系统的全新性能水平。
附录 I:详细性能数据
附录 I 提供了在不同数据集、嵌入提供商、BM25 与嵌入结合使用、语境化检索使用以及重排序使用情况下的检索召回率(1 减去召回率@20)详细结果,验证了上述各项优化策略的有效性。
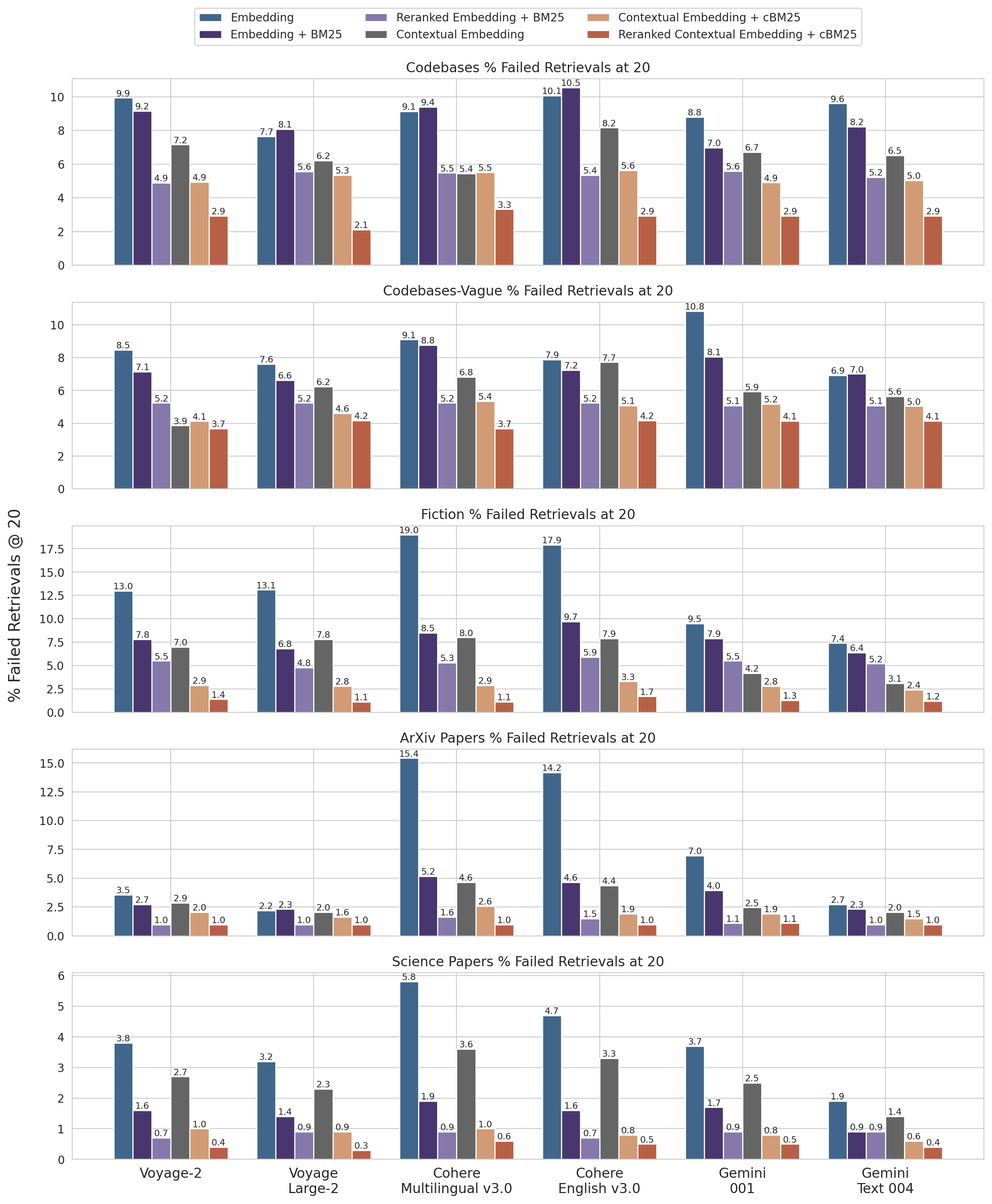 不同数据集和嵌入提供商的召回率@20结果(1减去召回率)。
不同数据集和嵌入提供商的召回率@20结果(1减去召回率)。
关于
关注我获取更多资讯

